
我们认为创造力是人类专属,AI没有创造力。
但法国索邦大学的最新研究成果,揭开了AI创造力从受限的领域生成模型中自然涌现的事实。

研究将创造力解构为时代精神、世界观、模式化习得与任意性四个核心组件,通过在限定的18世纪数据环境中,进行多模态生成对抗网络实验,证明了结构性约束与跨模态张力如何共同催生出超越模仿的新颖形式。
创造力源于系统内部的结构化博弈
现代人工智能领域对创造力的讨论往往陷入结果导向的误区。
人们习惯拿着放大镜审视AI生成的画作或文本,用新颖性、多样性或实用性这些外在标尺去丈量机器的灵感。
这种评估视角虽然方便了模型间的跑分对比,却回避了创造力究竟是如何从生成系统的内部动力学中生长出来的。
论文作者Corina Chutaux的研究转换了观察视角,不再纠结于产出物,转而关注生成过程本身的结构条件。
创造力被重新定义为一种在受限信息环境中涌现的属性。
这里的数据集不再仅仅是喂给算法的燃料,而是构成了一个封闭的认识论环境。在这个环境中,模型建立内部表征,通过动态博弈产生新的可能性。
我们将创造力视为一种位于特定知识领域内的涌现现象。正如人类艺术家无法脱离其所处的历史语境和个人经历,AI的创造力同样依赖于训练数据的边界、表征结构以及模态之间的交互。
这种观点将创造力从一种神秘的通用能力,还原为一种可被形式化描述的系统行为。
研究提出了一个包含四个维度的概念框架,旨在通过数学形式解构这一复杂的认知过程。
这四个维度分别是:模式化生成(Patternism)、诱导世界模型(Weltanschauung)、语境锚定(Zeitgeist)和任意性(Arbitrarity)。
这四个组件对应着具体的计算机制和数据分布特征。
数学化的表达让这种解构更加清晰。
研究引入了三个索引轴:个体索引I代表具体的模型实例,宏观历史索引S代表特定的历史时期,时间索引t代表系统的训练步数或生命周期。
在这种坐标系下,创造力不再是一个抽象的形容词,而是一个随着时间演变的函数。
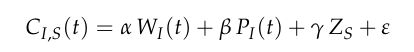
公式中的每一项都代表了创造力生成机制中不可或缺的一环。
这是为了搭建一个脚手架,让我们能够从结构上理解创造行为发生的必要条件。
模式化生成(Patternism)对应公式中的PI(t)。这是生成模型最擅长的部分,通过在大规模数据集上的优化,模型习得数据中反复出现的结构规律。在图像中,这是笔触、构图和光影的统计特征;在文本中,这是句法结构和修辞习惯。
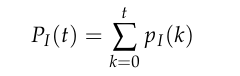
这是一个随时间累积的过程。随着训练步数k的增加,模型内化的规律越来越多,重组这些规律的能力也随之增强。
对于人类,这是通过反复练习获得的技艺;对于算法,这是梯度下降带来的参数优化。纯粹的模式化只能带来熟练的模仿,无法产生本质的创新。
诱导世界模型(Weltanschauung),即WI(t),代表了模型内部的意义组织方式。
它不是对外部世界的直接镜像,而是模型在潜在空间中构建的概念拓扑。
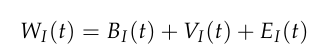
这个函数由信念结构、价值结构和经验结构三部分组成。
在多模态模型中,这种世界观体现为不同模态在共享潜空间中的对齐关系。
图像与文本的对应关系构成了模型理解世界的本体论基础,决定了概念之间如何关联,元素之间如何互动。
语境锚定(Zeitgeist),记作ZS,描述了宏观层面的历史文化约束。对于在18世纪语料库上训练的模型,当时的审美规范、社会习俗和知识体系构成了其运作的背景场。
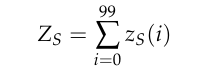
这个分量代表了百年间积累的文化信号。
它定义了什么是典型的、连贯的或可被接受的。创造力并不是要完全脱离这些约束,而是在这些隐性规范的张力中寻找突破。
训练数据的边界实际上赋予了生成内容以意义,绝对的自由往往导致无意义的混沌。
任意性(Arbitrarity),即公式中的ε,是一个常数项,代表了不可控的随机扰动。
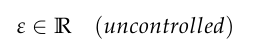
在计算系统中,这通常由随机种子或噪声向量引入。
它对应着创造过程中的偶然性,那些意外的错误、突发的灵感或系统性的偏差。
它的价值不在于随机本身,而在于它迫使系统偏离高概率的生成路径,探索那些潜在的、未被充分挖掘的表达空间。
受限领域内的生成动力学
为了验证这一理论框架,研究者设计了一个名为“创意生成对抗网络”(Creative Generative Adversarial Network, CGAN)的多模态系统。
实验构建一个历史上受限的封闭领域。研究者没有使用海量的互联网数据,而是严格筛选了18世纪的欧洲绘画和文学作品。
视觉语料库包含了18世纪的风景画、静物、肖像和风俗画。每张图片都配有详细的文本元数据,描述了构图、对象和风格。
文本语料库则包含了同时期的小说、散文和评论。这种数据选择策略直接实例化了Zeitgeist组件,迫使模型完全沉浸在特定历史时期的审美和认知环境中。
训练过程中,模型接收来自18世纪文学作品的句子作为条件输入。
这种提示策略避免了现代人的主观干预,确保了生成过程在封闭的历史循环中进行。系统不仅仅是在画画,而是在尝试建立文本描述与视觉表现之间的结构性映射。
实验设置了一个基线对照组:一个仅在图像数据上训练的单模态DCGAN。这个对照组的表现完全符合预期。在早期的训练阶段,它生成模糊的色块。

随着训练的深入,单模态模型逐渐掌握了18世纪绘画的形式语法。生成的图像在纹理和构图上越来越清晰,不仅有了具体的形状,还能复现当时的笔触风格。

即使训练到最后,单模态模型的产出依然保守。
它主要是在已知的视觉流形内进行插值,生成看起来很像原作但缺乏本质创新的“仿作”。
这就是纯粹的模式化生成(Patternism)的局限:它擅长复制和混合,却难以产生结构性的变异。

引入多模态约束后,情况发生了质的变化。
多模态CGAN要求生成器不仅要骗过判别器,还要让生成的图像与输入的文本描述在语义上一致。
这种跨模态的条件作用在潜空间中引入了强大的张力。
文本和图像虽然都来自18世纪,但它们代表了两种完全不同的表征空间。
强行要求两者对齐,迫使模型无法简单地复制训练集中的图像。
模型必须在满足文本语义和保持视觉真实性之间寻找平衡。这种内部的冲突和协商,打破了单模态模型稳定的收敛路径。
结果是惊人的。
多模态模型开始生成偏离原始语料库分布的图像。这些图像不再是标准的肖像或风景,而是呈现出抽象的形状、非指涉性的色块和新颖的形式组织。

这些图像并非无意义的噪声。它们在形式上依然保留了某种难以言喻的“18世纪特质”,例如色彩的调性,或是某种构图的节奏。但它们在结构上是全新的。
这种创新并非来自外部的指令,而是系统为了解决内部结构冲突而自发涌现的解决方案。
这就是所谓的“涌现性创造力”。
它不是对现有模式的简单重组,而是通过引入不同模态间的结构性不兼容,迫使系统逃离舒适区,探索未知的生成空间。
多模态与具身智能的未来
从实验观察中,我们得出了关于AI创造力本质的重要启示。
创造力往往被误解为一种不受限制的自由,但实际上,它是限制与自由之间辩证互动的产物。
过度的自由导致混乱,过度的限制导致僵化。
在多模态CGAN中,受限的18世纪数据集提供了必要的连贯性基础(Zeitgeist),而跨模态的对齐要求则引入了破坏性的张力。正是这种“有界限的破坏”,催生了意想不到的新形式。
这一框架同样揭示了当前生成模型的局限性。
目前的大模型主要依赖海量数据和模式识别。它们在Patternism维度上表现卓越,但在建立连贯的内部世界模型(Weltanschauung)方面仍有欠缺。
它们更多是在模仿数据的统计分布,而非理解概念之间的因果逻辑。
多模态学习是迈向更高级创造力的关键一步。
通过在共享的潜空间中映射视觉、文本甚至听觉信息,模型开始建立起类似于人类认知中的跨感官关联。这种关联为概念的重组和隐喻的生成提供了结构基础。
研究进一步指出,具身智能(Embodied AI)将是完善这一框架的必经之路。
目前的模型仍处于纯粹的表征领域,缺乏与物理世界的因果接触。没有身体的互动,模型无法获得经验性的反馈,也无法验证其内部表征的正确性。
机器人系统可以将这一理论框架落地。
通过与环境的物理交互,机器人能够获得直接的感官反馈,从而不断修正其内部的世界模型。这种闭环的交互过程,将使创造力从单纯的符号重组,进化为解决实际问题的适应性行为。
AI的创造力不需要意识、情感或生物本能作为前提。它是一种系统属性,源于结构化的约束、内部的组织以及不可约减的偶然性。
当我们剥离了人类中心主义的迷思,我们会发现,机器的创造力并非是对人类的拙劣模仿,而是一种独特的、基于算法逻辑的生成过程。
在设计未来的人工智能系统时,不应只关注任务优化的效率。保留一定的冗余、容忍偶然的偏差、引入跨模态的冲突,或许是激发机器产生真正创新解决方案的关键。
文章来自:51CTO