
近年来,大规模视频扩散模型在视频生成领域取得了显著进展。然而,采样效率低下仍然是这类模型的核心瓶颈。
标准的扩散模型依赖多步去噪过程,通常需要数十甚至上百次迭代步骤,才能将噪声逐步转化为真实输出。这种迭代特性带来了高推理延迟和高计算成本,使得大型扩散模型难以应用于实时视频生成、内容编辑、或为智能体训练构建世界模型等交互式场景。因此,如何在不牺牲视觉质量的前提下加速扩散采样,成为一个关键的开放性挑战。
现有的扩散蒸馏方法主要分为两大类:一类是基于轨迹的蒸馏,包括知识蒸馏和一致性模型,它们直接回归教师模型的去噪轨迹;另一类是基于分布的蒸馏,包括对抗蒸馏和变分分数蒸馏方法,它们对齐学生和教师的输出分布。这些技术在图像领域已经可以将采样过程压缩到仅需一到两步。
然而,将这些方法扩展到视频扩散模型面临独特的挑战。视频具有高时空维度和复杂的帧间依赖关系,在蒸馏过程中很难同时保持全局运动连贯性和细粒度空间细节。而且,现有大多数方法将扩散网络视为一个单一的整体映射,忽略了大型视频扩散主干网络中固有的层级结构和语义演进特性。
针对上述挑战,NVIDIA 联合 NYU 的谢赛宁等研究者提出了「转移匹配蒸馏」(Transition Matching Distillation,简称 TMD)框架,用于将大型视频扩散模型蒸馏为高效的少步生成器。

- 论文标题:Transition Matching Distillation for Fast Video Generation
- 论文链接:https://arxiv.org/pdf/2601.09881v1
- 项目链接:https://research.nvidia.com/labs/genair/tmd/
TMD 的核心思想是:用一个紧凑的少步概率转移过程来近似扩散模型的多步去噪过程。在这个框架中,每一个转移步骤都捕捉了视频样本在相距较远的噪声水平之间的分布演变,从而使学生模型能够以大的转移步长来匹配教师模型的分布。
实验结果表明,在相当的推理预算下,TMD 始终优于现有的蒸馏方法,能够实现更好的视觉保真度和对提示词的遵循度。作者蒸馏出的 14B 模型在 VBench 上的综合得分为 84.24,接近一步生成(NFE=1.38)。

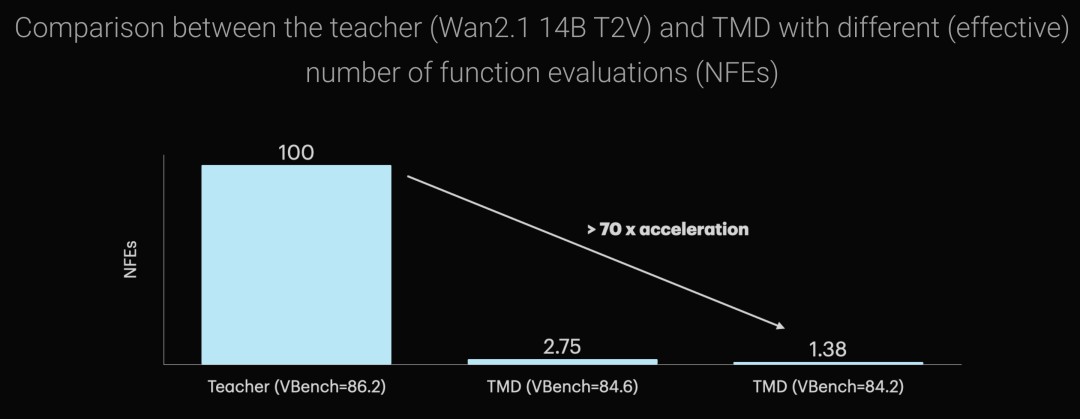
下图对比了教师模型(Wan2.1 14B)和 TMD 蒸馏模型在函数评估次数(NFE)上的差异。原始的 Wan2.1 14B 教师模型需要 100 次 NFE 才能生成一个视频,在 VBench 上的得分是 86.2。而经过 TMD 蒸馏后,模型只需要 2.75 次 NFE 就能达到 84.6 的 VBench 得分,或者只需要 1.38 次 NFE 就能达到 84.2 的得分。换算下来,TMD 实现了超过 70 倍的加速,而 VBench 得分仅下降约 2 分(从 86.2 降到 84.2)。这意味着在质量损失很小的情况下,视频生成速度提升了一个数量级以上。
在该项目网站,我们可以看到视频生成结果以及与基线方法的效果对比:

方法详解
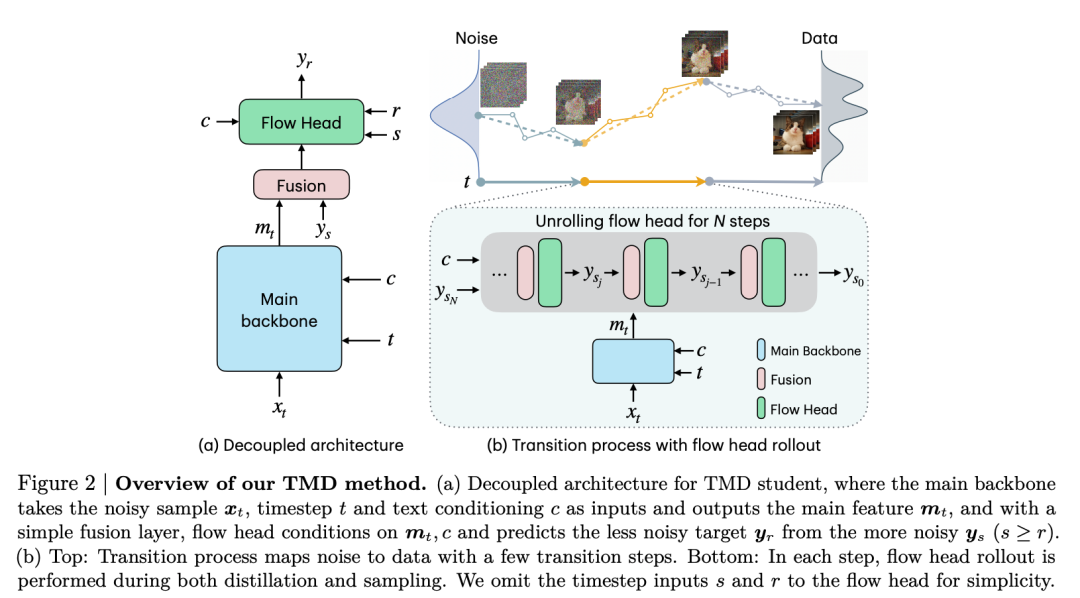
为了实现高效蒸馏,研究团队提出了一种解耦的学生模型架构,将原始的扩散主干网络分解为两个组件:第一个是「主干网络」,包含大部分早期层,负责在每个外部转移步骤提取高层语义表征;第二个是 Flow Head,由最后几层组成,它以主干网络提取的表征为条件,通过多个内部流更新来细化细粒度的视觉细节。
这种层级化的分解设计带来了显著优势。主干网络可以与 Flow Head 共享表征,而 Flow Head 则在每个外部转移步骤内执行若干轻量级的内部细化步骤,为平衡采样效率和视觉保真度提供了灵活的机制。举例来说,如果从一个 30 层的 DiT 模型中选取最后 5 层作为 Flow Head,并展开 2 个内部步骤,额外计算开销不到 17%。
TMD 采用两阶段训练策略。第一阶段是「转移匹配预训练」,研究团队借鉴了 MeanFlow 的思想,将 Flow Head 训练成一个条件流映射,使其能够进行迭代细化。这一阶段的关键在于让 Flow Head 的输出保持与预训练教师模型的输出对齐。第二阶段是「带 Flow Head 的分布匹配蒸馏」,研究团队改进了 DMD2 方法使其适应视频生成场景(称为 DMD2-v),并在每个转移步骤中展开 Flow Head 进行训练。通过展开 Flow Head,学生模型的概率转移与教师模型的多步扩散分布得以对齐,同时捕捉语义演变和细粒度视觉细节。
在 DMD2-v 的改进中,研究团队识别出三个对视频蒸馏至关重要的因素:首先是 GAN 判别器架构,使用 Conv3D 层优于其他架构,这表明局部化的时空特征对 GAN 损失很重要;其次是知识蒸馏预热策略,它在单步蒸馏中有帮助,但在多步生成中反而会引入难以修复的粗粒度伪影;第三是时间步偏移,对采样时间步应用偏移函数可以改善性能并防止模式崩溃。
实验结果
研究团队在 Wan2.1 的 1.3B 和 14B 两个文本到视频模型上验证了 TMD 的效果,生成的是 5 秒、480p 分辨率、81 帧的视频。评估采用了 VBench 基准测试和用户偏好研究两种方式。
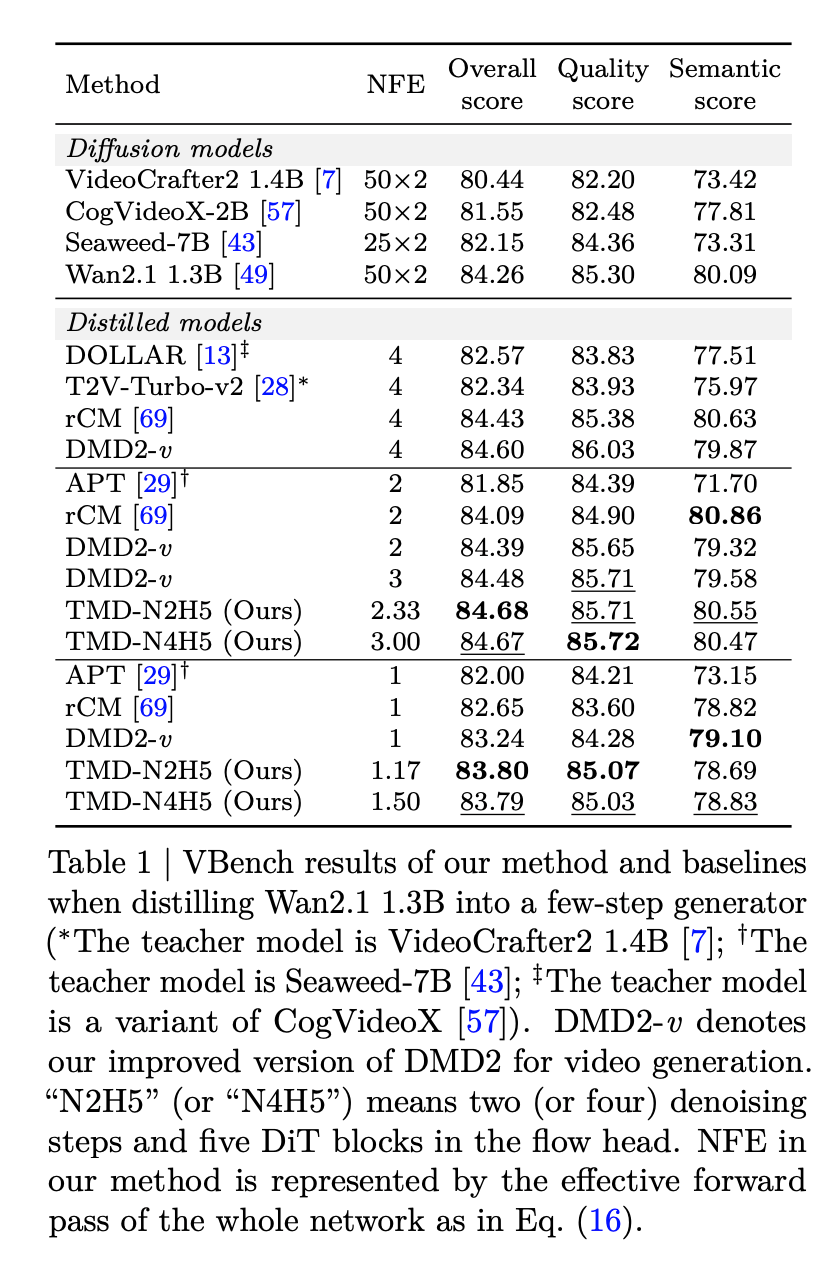
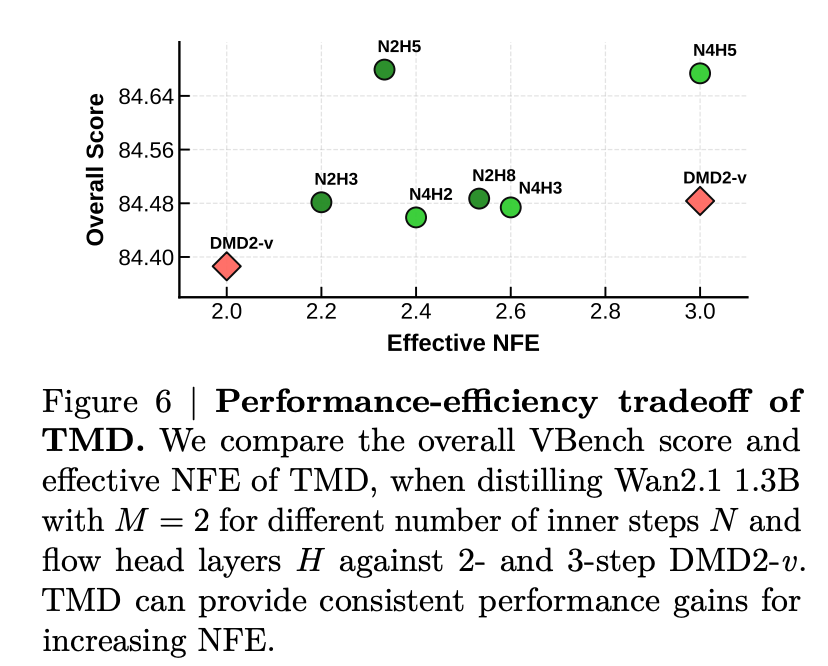
在 Wan2.1 1.3B 模型的蒸馏实验中,当使用 2 个外部去噪步骤时,TMD-N2H5(即 2 个去噪步骤配合 5 层 Flow Head)以 2.33 的有效 NFE(函数评估次数)取得了 84.68 的 VBench 总分,超越了所有其他蒸馏模型,包括 NFE 为 4 的最强基线 rCM(总分 84.43)。当只使用 1 个外部步骤时,TMD-N2H5 以 1.17 的有效 NFE 取得了 83.80 的总分,同样优于所有其他单步蒸馏方法,大幅缩小了与两步蒸馏方法之间的差距。
在更大的 Wan2.1 14B 模型上,TMD 的优势更加明显。当使用 1 个外部步骤时,TMD-N4H5 以 1.38 的有效 NFE 取得了 84.24 的总分,显著超越了所有其他单步蒸馏方法。相比单步 rCM 的 83.02 分,TMD 提升了 1.22 分,而额外的推理成本几乎可以忽略不计。
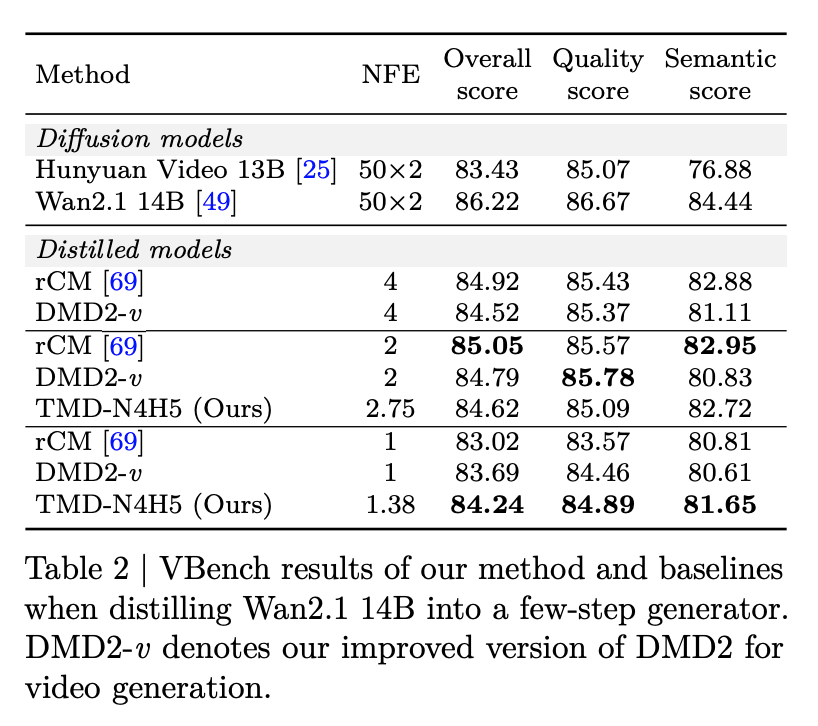
此外,TMD 还消除了单步 DMD2-v 所需的计算昂贵的知识蒸馏预热步骤。
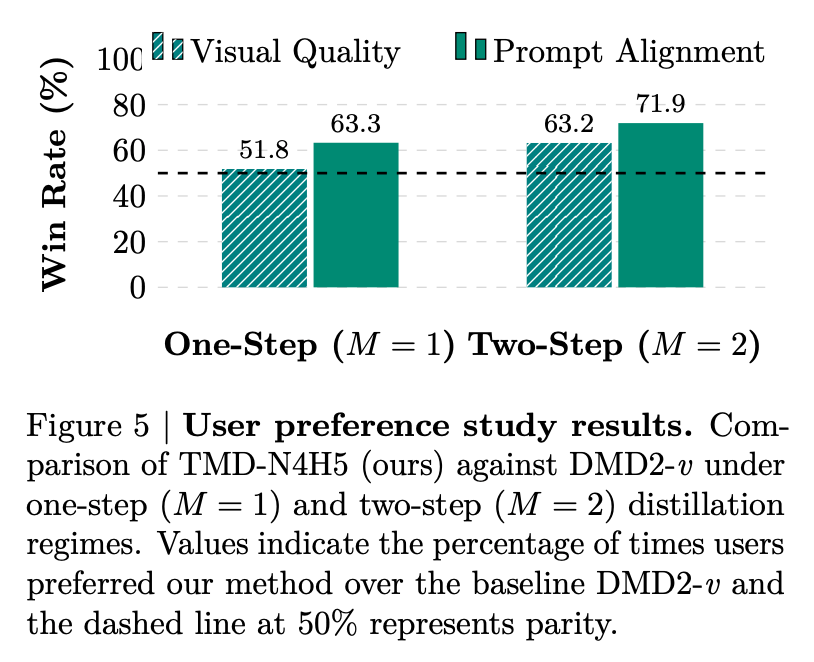
除了自动化指标,研究团队还进行了用户偏好研究。他们从 VBench 中随机抽取 60 个具有挑战性的提示,针对每个提示用不同种子生成 5 个视频,让评估者在视觉质量和提示对齐两个维度上进行盲测对比。结果显示,无论是在单步还是两步生成设置下,用户都一致更偏好 TMD 生成的视频。在两步生成中,TMD 在视觉质量上的胜率为 63.3%,在提示对齐上的胜率高达 71.9%。这一结果表明,Flow Head 的迭代细化机制对于提升提示遵循能力有显著帮助。

研究团队还进行了详细的消融实验来验证各设计选择的有效性。在预训练方法上,使用 MeanFlow 目标(TM-MF)一致优于普通的流匹配目标(TM)。在蒸馏阶段,启用 Flow Head 展开可以带来更快的训练收敛和更好的最终性能。此外,通过调整内部步数和 Flow Head 层数,TMD 可以实现细粒度的质量 – 效率权衡,VBench 总分随有效 NFE 的增加而稳步提升。
文章来自:51CTO