


大规模训练 AI 模型并非易事。
除了需要大量算力和资源外,训练非常大的模型背后也有着相当大的工程复杂性。在 Facebook AI Research(FAIR)Engineering,我们一直在努力构建各种工具和基础设施,让大型 AI 模型训练起来更加轻松。
我们最近的一部分成果包括了 层内模型并行、流水线模型并行、优化器状态 + 梯度分片 和 多专家模型 等领域的工作,旨在提升为任意数量的任务训练高级 AI 模型的效率。
完全分片数据并行(Fully Sharded Data Parallel,FSDP)是我们推出的最新工具。它将 AI 模型的参数分片到数据并行 worker 中,并且可以选择将部分训练计算卸载到 CPU。顾名思义,FSDP 是一种数据并行训练算法。
尽管参数被分片到了不同的 GPU,但每个微批次数据的计算仍然是每个 GPU worker 上的本地计算。这种简洁的概念让 FSDP 更容易理解,适用于更广泛的使用场景(与层内并行和流水线并行相比)。与优化器状态 + 梯度分片数据并行方法相比,FSDP 分片参数更均匀,并且能够通过训练期间的通信和计算重叠来获得更好的性能。
有了 FSDP 后,我们现在可以使用更少的 GPU 更高效地训练更大数量级的模型。FSDP 已在 FairScale 库 中实现,允许工程师和开发人员使用简单的 API 扩展和优化他们的模型训练。
在 Facebook,FSDP 已被集成和测试,用于训练我们的一些 NLP 和 视觉 模型。
NLP 研究是一个特殊领域,其中我们可以看到有效利用算力来训练 AI 的重要性。去年,OpenAI 宣布他们训练出了 GPT-3,这是有史以来最大的神经语言模型,有 1750 亿个参数。
据估计,训练 GPT-3 需要大约 355 个 GPU 年,或者相当于 1,000 个 GPU 连续工作四个多月。
除了需要大量计算和工程资源外,大多数扩展到如此程度的方法都会带来额外的通信成本,并要求工程师仔细评估内存使用和计算效率之间的权衡。
例如,典型的数据并行训练需要在每个 GPU 上都维护模型的冗余副本,而模型并行训练需要在 worker(GPU)之间移动激活,从而引入额外的通信成本。
相比之下,FSDP 牺牲的东西相对较少。它通过跨 GPU 分片模型参数、梯度和优化器状态来提高内存效率,并通过分解通信并将其与前向和后向传递重叠来提高计算效率。
FSDP 产生的训练结果与标准分布式数据并行(DDP)训练相同,并且可在一个易用的界面中使用,该界面可直接替代 PyTorch 的 DistributedDataParallel 模块。我们的早期测试表明,FSDP 可以扩展到数万亿个参数。
在标准的 DDP 训练中,每个 worker 处理一个单独的批次,并且使用 all-reduce 操作对各个 worker 的梯度求和。虽然 DDP 已经变得非常流行,但它需要的 GPU 内存过多了,因为模型权重和优化器状态需要在所有 DDP worker 之间复制。
减少重复的一种方法是应用一个称为全参数分片的过程,其中只有局部计算所需的模型参数、梯度和优化器的一个子集是可用的。这种方法的一个实现,ZeRO-3,已被微软推而广之。
解锁全参数分片的关键在于,我们可以将 DDP 中的 all-reduce 操作分解为单独的 reduce-scatter 和 all-gather 操作:
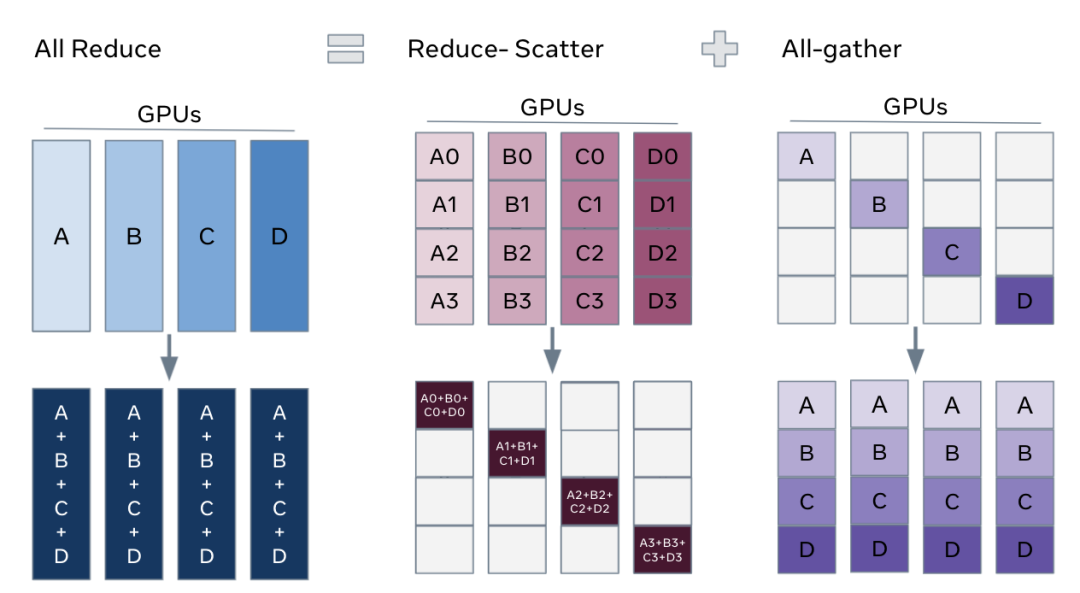
All-reduce 是 reduce-scatter 和 all-gather 的组合。聚合梯度的标准 all-reduce 操作可以分解为两个独立的阶段:reduce-scatter 和 all-gather。在 reduce-scatter 阶段,梯度在每个 GPU 上的各个 rank 之间的相等块中基于它们的 rank 索引相加。在 all-gather 阶段,每个 GPU 上可用的聚合梯度的分片部分可供所有 GPU 使用。
然后,我们可以重新排列 reduce-scatter 和 all-gather,让每个 DDP worker 只需存储参数和优化器状态的单个分片。下图分别展示了标准 DDP 训练(上)和 FSDP 训练(下):
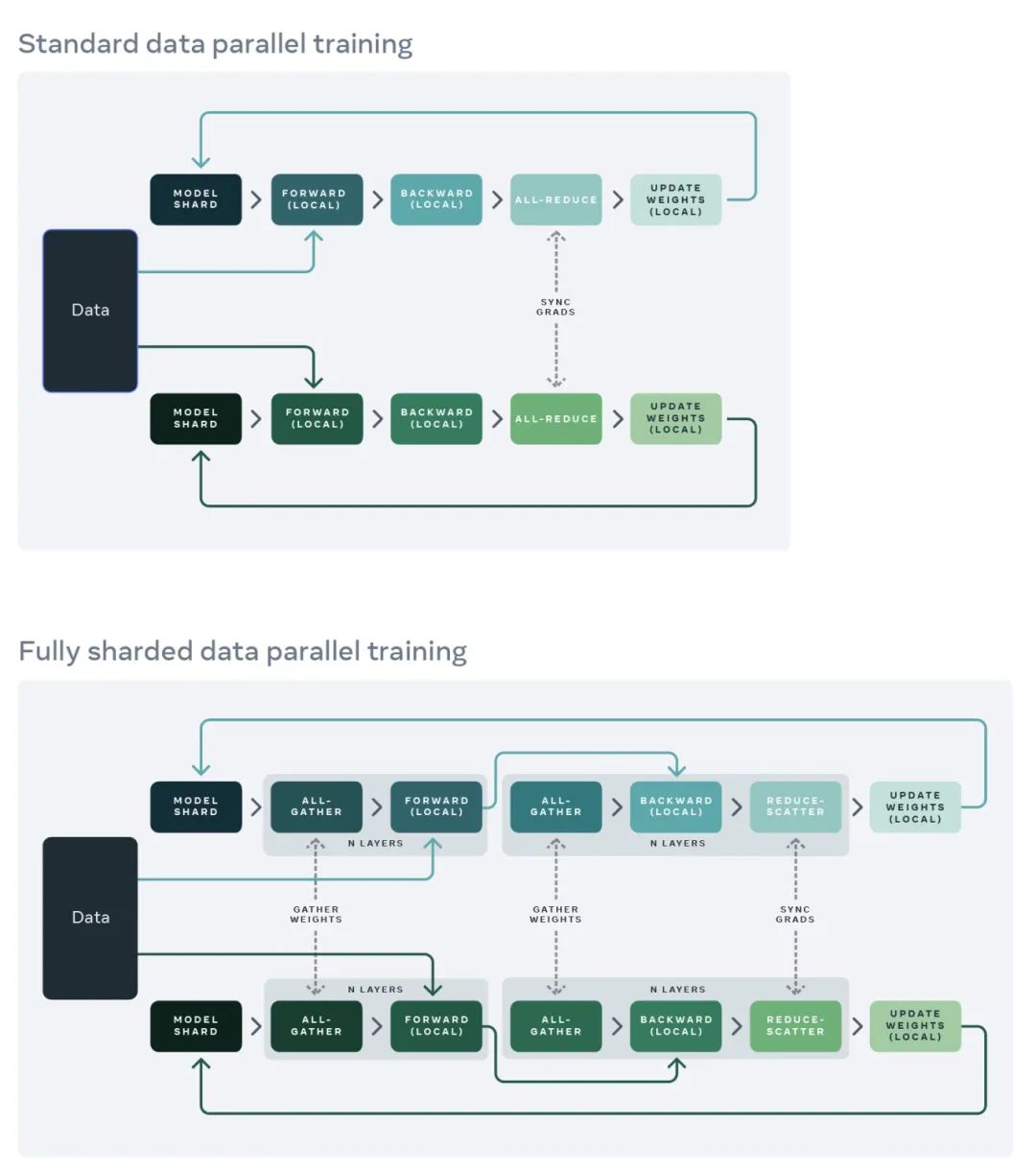
标准数据并行训练和完全分片数据并行训练的对比。在标准数据并行训练方法中,模型的副本存在于每个 GPU 上,并且仅在数据的一个分片上评估一系列前向和后向传递。在这些本地计算之后,每个本地进程的参数和优化器与其他 GPU 共享,以计算全局权重更新。在 FSDP 中,GPU 上仅存在模型的一个分片。然后在本地,所有权重都通过 all-gather 步骤从其他 GPU 收集,来计算前向传递。然后在向后传递之前再次执行这种权重收集。在向后传递之后,局部梯度被平均,并通过 reduce-scatter 步骤在 GPU 上分片,这样每个 GPU 都能更新其局部权重分片。
为了最大限度地提高内存效率,我们可以在每层前向传递后丢弃全部权重,从而为后续层节省内存。要实现这一点,可以将 FSDP 包装器应用于网络中的每一层(使用 reshard_after_forward=True)。
在伪代码中:
FSDP forward pass:
for layer_i in layers:
all-gather full weights for layer_i
forward pass for layer_i
discard full weights for layer_i
FSDP backward pass:
for layer_i in layers:
all-gather full weights for layer_i
backward pass for layer_i
discard full weights for layer_i
reduce-scatter gradients for layer_
在大规模 AI 研究中使用 FSDP 有几种方法。当下我们提供四种解决方案,以适应不同的需求。
对于语言模型,fairseq 框架 通过以下新参数支持 FSDP:
- –ddp-backend=fully_sharded:通过 FSDP 启用完整分片
- –cpu-offload:将优化器状态和 FP32 模型副本卸载到 CPU(搭配–optimizer=cpu_adam)
- –no-reshard-after-forward:提高大型模型的训练速度(1B+ 参数),类似于 ZeRO 阶段 2
- 其他流行的选项(–fp16、–update-freq、–checkpoint-activations、–offload-activations 等)可以继续正常使用
关于使用 FSDP 在八个 GPU 上,或在单个 GPU 上使用 FSDP+CPU 卸载训练 13B 参数模型的说明,请参阅 fairseq教程。
对于计算机视觉模型,VISSL 已支持 FSDP,并在 RegNets 架构上做了测试。像 BatchNorm 和 ReLU 这样的层被无缝处理,并测试了收敛。
使用以下选项启用 FSDP:
- config.MODEL.FSDP_CONFIG.AUTO_SETUP_FSDP=True
- config.MODEL.SYNC_BN_CONFIG.SYNC_BN_TYPE=pytorch
- config.MODEL.AMP_PARAMS.AMP_TYPE=pytorch
关于在 VISSL 中配置 FSDP 的其他选项,请参阅 yaml 配置的 这一部分。
为了更轻松地与更一般的用例集成,PyTorch Lightning 已经以测试特性的形式支持了 FSDP。这份 教程 包含了如何将 FSDP 插件与 PyTorch Lightning 搭配使用的详细示例。在高层次上,在下面添加 plugins=’fsdp’可以激活它。
model = MyModel()
trainer = Trainer(gpus=4, plugins='fsdp', precision=16)
trainer.fit(model)
trainer.test()
trainer.predict()
FairScale 是开发 FSDP,以及你可以找到最新更新的主库。你可以在下面的示例中简单地替换 DDP(my_module),直接使用 FairScale 的 FSDP:
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP
...
sharded_module = DDP(my_module)FSDP(my_module)
optim = torch.optim.Adam(sharded_module.parameters(), lr=0.0001)
for sample, label in dataload.next_batch:
out = sharded_module(x=sample, y=3, z=torch.Tensor([1]))
loss = criterion(out, label)
loss.backward()
optim.step()
FairScale 中的 FSDP 库为大规模训练的许多重要方面提供了底层选项。当你充分利用 FSDP 时,需要考虑以下几个重要方面。
- 模型包装:为了最小化瞬时 GPU 内存需求,用户需要以嵌套方式包装模型。这引入了额外的复杂性。auto_wrap 实用程序可用于注释现有 PyTorch 模型代码,用于嵌套包装目的。
- 模型初始化:与 DDP 不同,FSDP 不会在 GPU worker 之间自动同步模型权重。这意味着我们必须小心地完成模型初始化,以便所有 GPU worker 具有相同的初始权重。
- 优化器设置:由于分片和包装,FSDP 仅支持某些类型的优化器和优化器设置。特别是,如果一个模块被 FSDP 包装,并且它的参数被扁平化为单个张量,那么用户就不能在这样的模块中为不同的参数组使用不同的超参数。
- 混合精度:FSDP 支持具有 FP16 主权重的高级混合精度训练,以及梯度上的 FP16 减少和分散。有些情况下,只有在使用全精度时,模型的某些部分才能收敛。在这些情况下,需要额外的包装来选择以全精度运行模型的某些部分。
- 状态检查点和推理:当模型规模很大时,保存和加载模型状态会变得颇具挑战性。FSDP 支持多种方式来完成该任务,但这绝非易事。
- 最后,FSDP 经常与 FairScale 的 checkpoint_wrapper 等 激活检查点 函数搭配使用。用户可能需要仔细调整激活检查点策略,以在有限的 GPU 内存空间内适配大型模型。
下一步计划
FSDP 是开源的,早期用户已经尝试过它并为之做出了贡献。我们认为它可以让整个研究社区受益,我们期待与所有人合作,让它变得更好。下面是一些尤为重要的领域。
- 让 FSDP更通用 。到目前为止,FSDP 已用于具有 SGD 和 Adam 优化器的 NLP 和视觉模型。随着更新的模型和优化器不断涌现,FSDP 需要继续支持它们。作为纯粹的数据并行训练方案,FSDP 在支持广泛的 AI 算法方面拥有极大的潜力。
- 使 FSDP支持自动调优 。今天,用户在使用 FSDP 时可以调整许多旋钮,以实现扩展和性能提升。我们期待能开发出自动调优 GPU 内存使用和训练性能的算法。
- 除了训练之外,更具扩展性的推理 和模型服务是 FSDP 可能需要支持的一个重要用例。
- 最后一点也很重要,重构和继续模块化FSDP及其核心组件对于更新更好的组件来说也是很关键的基础。
试用并做出贡献!
FSDP 目前可直接从 FairScale 库中获得。
原文链接:
Fully Sharded Data Parallel: faster AI training with fewer GPUs
内容来源:Facebook工程团队
![]()