
聚类是一种机器学习技术,它涉及到数据点的分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督学习的方法,是许多领域中常用的统计数据分析技术。
在数据科学中,我们可以使用聚类分析从我们的数据中获得一些有价值的见解。在这篇文章中,我们将研究5种流行的聚类算法以及它们的优缺点。
K-MEANS聚类算法
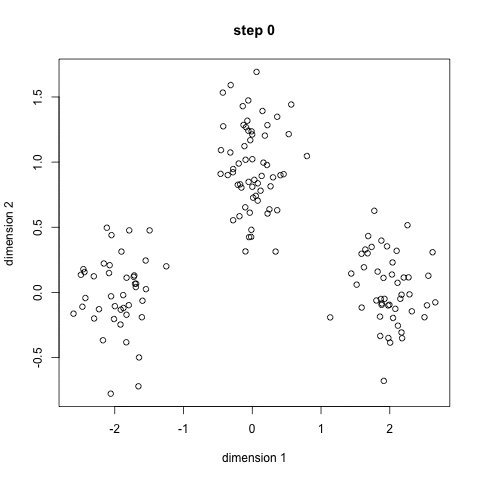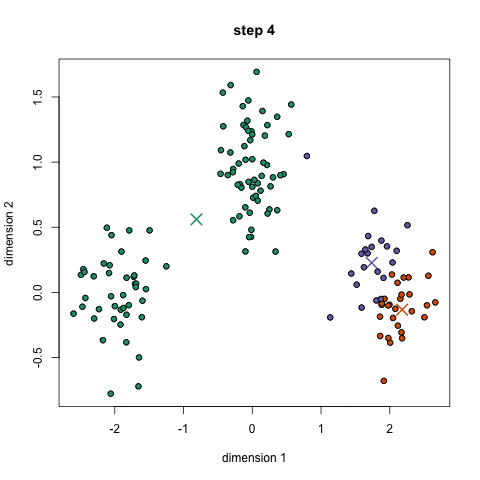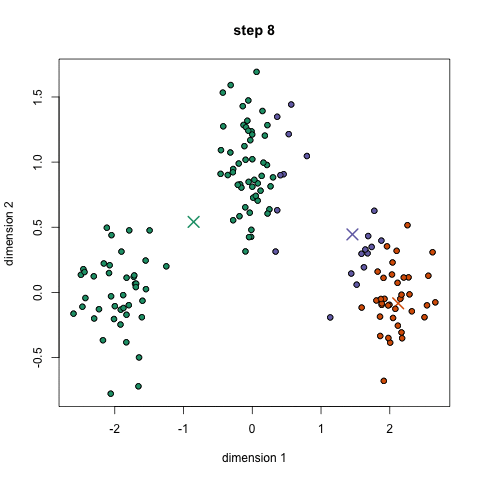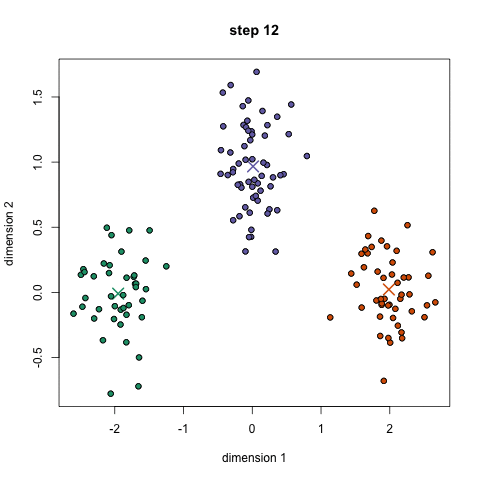
K-Means聚类算法可能是大家最熟悉的聚类算法。它出现在很多介绍性的数据科学和机器学习课程中。在代码中很容易理解和实现!请看下面的图表。
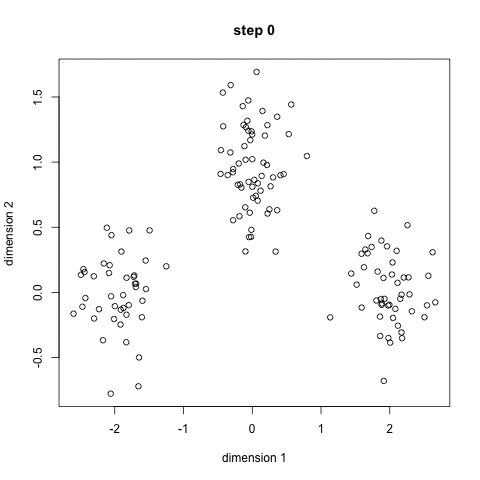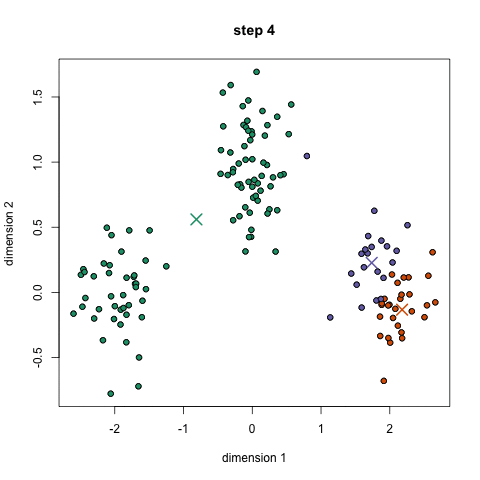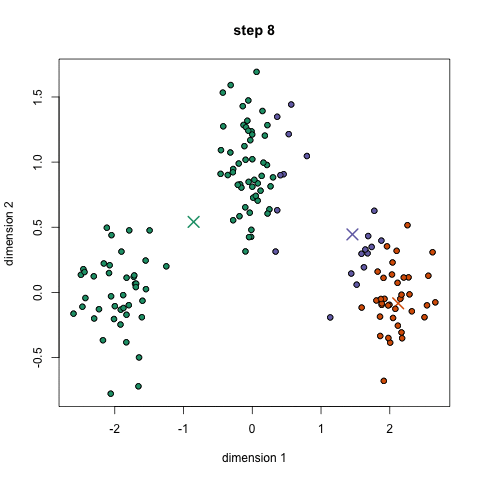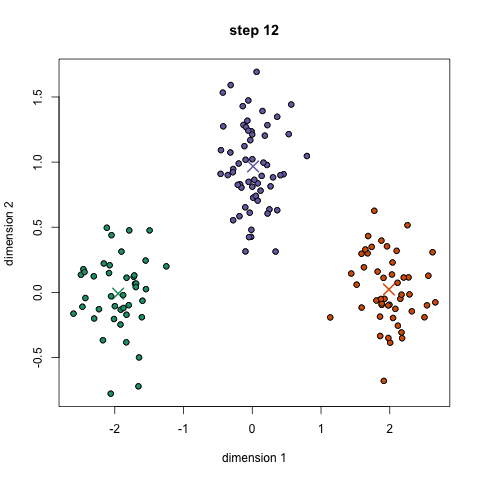
K-Means聚类
1.首先,我们选择一些类/组来使用并随机地初始化它们各自的中心点。要想知道要使用的类的数量,最好快速地查看一下数据,并尝试识别任何不同的分组。中心点是与每个数据点向量相同长度的向量,在上面的图形中是“X”。
2.每个数据点通过计算点和每个组中心之间的距离进行分类,然后将这个点分类为最接近它的组。
3.基于这些分类点,我们通过取组中所有向量的均值来重新计算组中心。
4.对一组迭代重复这些步骤。你还可以选择随机初始化组中心几次,然后选择那些看起来对它提供了最好结果的来运行。
K-Means聚类算法的优势在于它的速度非常快,因为我们所做的只是计算点和群中心之间的距离;它有一个线性复杂度O(n)。
另一方面,K-Means也有几个缺点。首先,你必须选择有多少组/类。这并不是不重要的事,理想情况下,我们希望它能帮我们解决这些问题,因为它的关键在于从数据中获得一些启示。K-Means也从随机选择的聚类中心开始,因此在不同的算法运行中可能产生不同的聚类结果。因此,结果可能是不可重复的,并且缺乏一致性。其他聚类方法更加一致。
K-Medians是另一种与K-Means有关的聚类算法,除了使用均值的中间值来重新计算组中心点以外,这种方法对离群值的敏感度较低(因为使用中值),但对于较大的数据集来说,它要慢得多,因为在计算中值向量时,每次迭代都需要进行排序。
均值偏移聚类算法
均值偏移(Mean shift)聚类算法是一种基于滑动窗口(sliding-window)的算法,它试图找到密集的数据点。而且,它还是一种基于中心的算法,它的目标是定位每一组群/类的中心点,通过更新中心点的候选点来实现滑动窗口中的点的平均值。这些候选窗口在后期处理阶段被过滤,以消除几乎重复的部分,形成最后一组中心点及其对应的组。请看下面的图表。
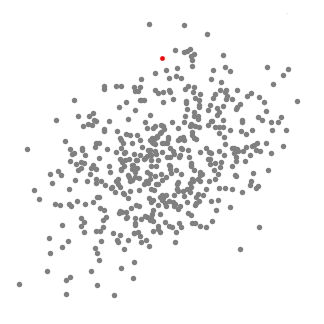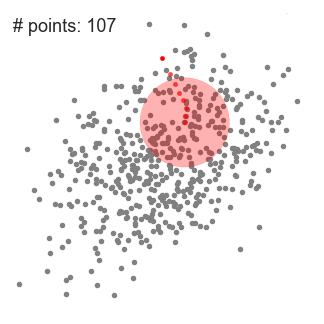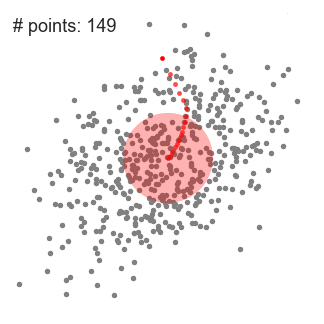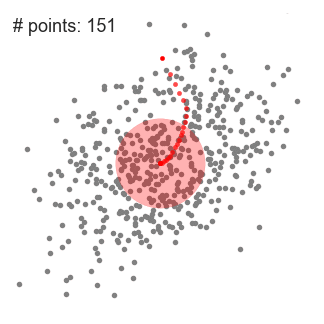
单滑动窗口的均值偏移聚类
1.为了解释这一变化,我们将考虑二维空间中的一组点(就像上面的例子)。我们从一个以点C(随机选择)为中心的圆形滑窗开始,以半径r为内核。均值偏移是一种爬山算法(hill climbing algorithm),它需要在每个步骤中反复地将这个内核移动到一个更高的密度区域,直到收敛。
2.在每一次迭代中,滑动窗口会移向密度较高的区域,将中心点移动到窗口内的点的平均值(因此得名)。滑动窗口中的密度与它内部的点的数量成比例。自然地,通过移向窗口中点的平均值,它将逐渐向更高的点密度方向移动。
3.我们继续根据均值移动滑动窗口,直到没有方向移动可以容纳内核中的更多点。看看上面的图表;我们一直在移动这个圆,直到我们不再增加密度(也就是窗口中的点数)。
4.步骤1到3的过程是用许多滑动窗口完成的,直到所有的点都位于一个窗口内。当多个滑动窗口重叠的时候,包含最多点的窗口会被保留。然后,数据点根据它们所在的滑动窗口聚类。
下面展示了从端到端所有滑动窗口的整个过程的演示。每个黑点代表一个滑动窗口的质心,每个灰色点都是一个数据点。

均值偏移聚类的整个过程
与K-Means聚类相比,均值偏移不需要选择聚类的数量,因为它会自动地发现这一点。这是一个巨大的优势。聚类中心收敛于最大密度点的事实也是非常可取的,因为它非常直观地理解并适合于一种自然数据驱动。缺点是选择窗口大小/半径r是非常关键的,所以不能疏忽。
DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法,类似于均值转移聚类算法,但它有几个显著的优点。
DBSCAN笑脸聚类
1.DBSCAN以一个从未访问过的任意起始数据点开始。这个点的邻域是用距离ε(所有在ε距离的点都是邻点)来提取的。
2.如果在这个邻域中有足够数量的点(根据 minPoints),那么聚类过程就开始了,并且当前的数据点成为新聚类中的第一个点。否则,该点将被标记为噪声(稍后这个噪声点可能会成为聚类的一部分)。在这两种情况下,这一点都被标记为“访问(visited)”。
3.对于新聚类中的第一个点,其ε距离附近的点也会成为同一聚类的一部分。这一过程使在ε邻近的所有点都属于同一个聚类,然后重复所有刚刚添加到聚类组的新点。
4.步骤2和步骤3的过程将重复,直到聚类中的所有点都被确定,就是说在聚类附近的所有点都已被访问和标记。
5.一旦我们完成了当前的聚类,就会检索并处理一个新的未访问点,这将导致进一步的聚类或噪声的发现。这个过程不断地重复,直到所有的点被标记为访问。因为在所有的点都被访问过之后,每一个点都被标记为属于一个聚类或者是噪音。
DBSCAN比其他聚类算法有一些优势。首先,它不需要一个预设定的聚类数量。它还将异常值识别为噪声,而不像均值偏移聚类算法,即使数据点非常不同,它也会将它们放入一个聚类中。此外,它还能很好地找到任意大小和任意形状的聚类。
DBSCAN的主要缺点是,当聚类具有不同的密度时,它的性能不像其他聚类算法那样好。这是因为当密度变化时,距离阈值ε和识别邻近点的minPoints的设置会随着聚类的不同而变化。这种缺点也会出现在非常高维的数据中,因为距离阈值ε变得难以估计。
使用高斯混合模型(GMM)的期望最大化(EM)聚类
K-Means的一个主要缺点是它对聚类中心的平均值的使用很简单幼稚。我们可以通过看下面的图片来了解为什么这不是最好的方法。在左边看起来很明显的是,有两个圆形的聚类,不同的半径以相同的平均值为中心。K-Means无法处理,因为聚类的均值非常接近。在聚类不是循环的情况下,K-Means也会失败,这也是使用均值作为聚类中心的结果。

K-Means的两个失败案例
高斯混合模型(GMMs)比K-Means更具灵活性。使用高斯混合模型,我们可以假设数据点是高斯分布的;比起说它们是循环的,这是一个不那么严格的假设。这样,我们就有两个参数来描述聚类的形状:平均值和标准差!以二维的例子为例,这意味着聚类可以采用任何形式的椭圆形状(因为在x和y方向上都有标准差)。因此,每个高斯分布可归属于一个单独的聚类。
为了找到每个聚类的高斯分布的参数(例如平均值和标准差)我们将使用一种叫做期望最大化(EM)的优化算法。看看下面的图表,就可以看到高斯混合模型是被拟合到聚类上的。然后,我们可以继续进行期望的过程——使用高斯混合模型实现最大化聚类。
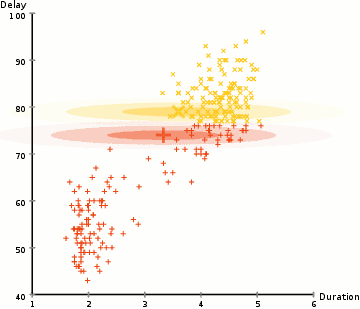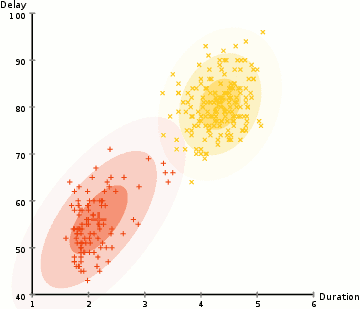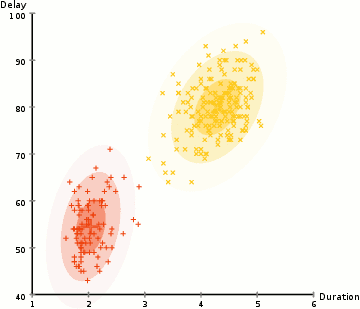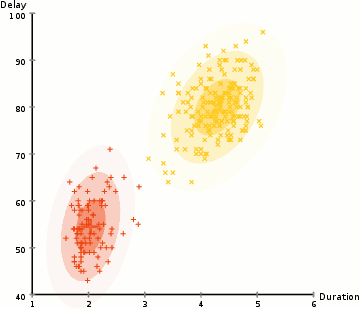
使用高斯混合模型来期望最大化聚类
1.我们首先选择聚类的数量(如K-Means所做的那样),然后随机初始化每个聚类的高斯分布参数。通过快速查看数据,可以尝试为初始参数提供良好的猜测。注意,在上面的图表中可以看到,这并不是100%的必要,因为高斯开始时的表现非常不好,但是很快就被优化了。
2.给定每个聚类的高斯分布,计算每个数据点属于特定聚类的概率。一个点离高斯中心越近,它就越有可能属于那个聚类。这应该是很直观的,因为有一个高斯分布,我们假设大部分的数据都离聚类中心很近。
3.基于这些概率,我们为高斯分布计算一组新的参数,这样我们就能最大程度地利用聚类中的数据点的概率。我们使用数据点位置的加权和来计算这些新参数,权重是属于该特定聚类的数据点的概率。为了解释这一点,我们可以看一下上面的图,特别是黄色的聚类作为例子。分布在第一次迭代中是随机的,但是我们可以看到大多数的黄色点都在这个分布的右边。当我们计算一个由概率加权的和,即使在中心附近有一些点,它们中的大部分都在右边。因此,自然分布的均值更接近于这些点。我们还可以看到,大多数点都是“从右上角到左下角”。因此,标准差的变化是为了创造一个更符合这些点的椭圆,从而使概率的总和最大化。
步骤2和3被迭代地重复,直到收敛,在那里,分布不会从迭代到迭代这个过程中变化很多。
使用高斯混合模型有两个关键的优势。首先,高斯混合模型在聚类协方差方面比K-Means要灵活得多;根据标准差参数,聚类可以采用任何椭圆形状,而不是局限于圆形。K-Means实际上是高斯混合模型的一个特例,每个聚类在所有维度上的协方差都接近0。其次,根据高斯混合模型的使用概率,每个数据点可以有多个聚类。因此,如果一个数据点位于两个重叠的聚类的中间,通过说X%属于1类,而y%属于2类,我们可以简单地定义它的类。
层次聚类算法
层次聚类算法实际上分为两类:自上而下或自下而上。自下而上的算法在一开始就将每个数据点视为一个单一的聚类,然后依次合并(或聚集)类,直到所有类合并成一个包含所有数据点的单一聚类。因此,自下而上的层次聚类称为合成聚类或HAC。聚类的层次结构用一棵树(或树状图)表示。树的根是收集所有样本的唯一聚类,而叶子是只有一个样本的聚类。在继续学习算法步骤之前,先查看下面的图表。
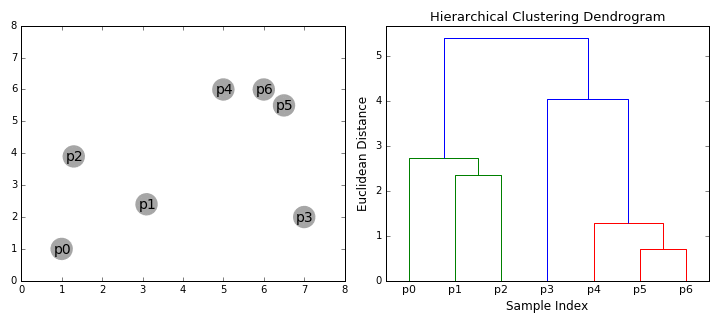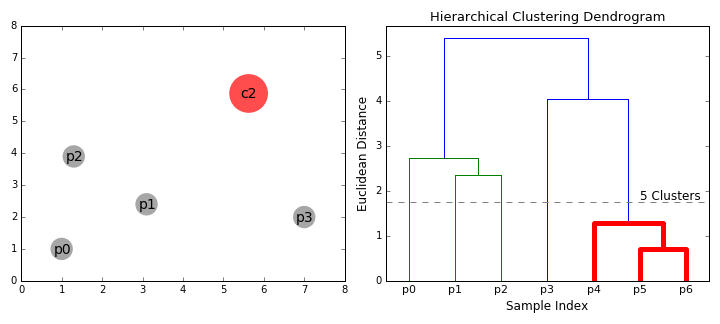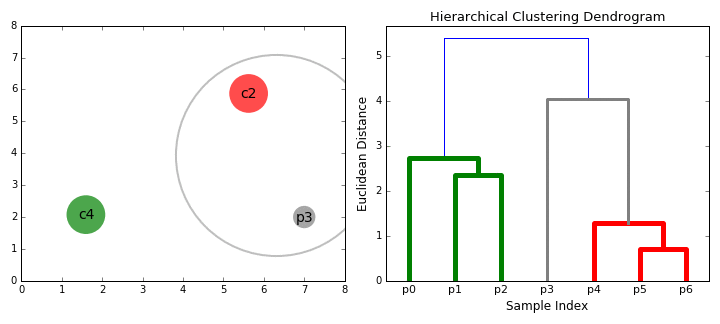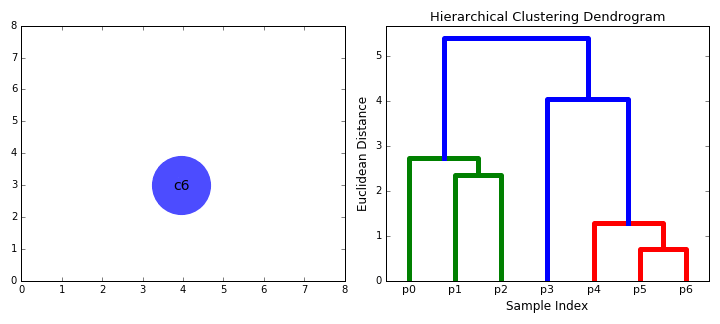
合成聚类
1.我们首先将每个数据点作为一个单独的聚类进行处理。如果我们的数据集有X个数据点,那么我们就有了X个聚类。然后我们选择一个度量两个聚类之间距离的距离度量。作为一个示例,我们将使用平均连接(average linkage)聚类,它定义了两个聚类之间的距离,即第一个聚类中的数据点和第二个聚类中的数据点之间的平均距离。
2.在每次迭代中,我们将两个聚类合并为一个。将两个聚类合并为具有最小平均连接的组。比如说根据我们选择的距离度量,这两个聚类之间的距离最小,因此是最相似的,应该组合在一起。
3.重复步骤2直到我们到达树的根。我们只有一个包含所有数据点的聚类。通过这种方式,我们可以选择最终需要多少个聚类,只需选择何时停止合并聚类,也就是我们停止建造这棵树的时候!
层次聚类算法不要求我们指定聚类的数量,我们甚至可以选择哪个聚类看起来最好。此外,该算法对距离度量的选择不敏感;它们的工作方式都很好,而对于其他聚类算法,距离度量的选择是至关重要的。层次聚类方法的一个特别好的用例是,当底层数据具有层次结构时,你可以恢复层次结构;而其他的聚类算法无法做到这一点。层次聚类的优点是以低效率为代价的,因为它具有O(n³)的时间复杂度,与K-Means和高斯混合模型的线性复杂度不同。
![]()