


如果从达特茅斯会议起算,AI 已经走过 65 年历程,尤其是近些年深度学习兴起后,AI 迎来了空前未有的繁荣。不过,最近两年中国 AI 热潮似乎有所回落,在理论突破和落地应用上都遇到了挑战,外界不乏批评质疑的声音,甚至连一些 AI 从业者也有些沮丧。
从 90 年代到美国卡耐基梅隆大学读博开始,我有幸成为一名 AI 研究者,见证了这个领域的一些起伏。通过这篇文章,我将试图通过个人视角回顾 AI 的发展,审视我们当下所处的历史阶段,以及探索 AI 的未来究竟在哪里。
本文部分观点:
1、 AI 时代序幕刚拉开,AI 目前还处于初级阶段,犹如法拉第刚刚发现了交流电,还未能从技术上升为科学。
2、以深度学习为代表的 AI 研究这几年取得了诸多令人赞叹的进步,但部分也是运气的结果,其真正原理迄今无人知晓。
3、在遇到瓶颈后,深度学习有三个可能突破方向:深度学习的根本理解、自监督学习和小样本学习、知识与数据的有机融合。
4、AI 在当下最大的机会:用 AI 解决科学重要难题(AI for Science)。
虽然有人把当下归为第三波甚至是第四波 AI 浪潮,乐观地认为 AI 时代已经到来,但我的看法要谨慎一些:AI 无疑具有巨大潜力,但就目前我们的能力,AI 尚处于比较初级的阶段,是技术而非科学。这不仅是中国 AI 的问题,也是全球 AI 共同面临的难题。
这几年深度学习的快速发展,极大改变了 AI 行业的面貌,让 AI 成为公众日常使用的技术,甚至还出现了一些令公众惊奇的 AI 应用案例,让人误以为科幻电影即将变成现实。但实际上,技术发展需要长期积累,目前只是 AI 的初级阶段,AI 时代才刚开始。
如果将 AI 时代和电气时代类比,今天我们的 AI 技术还是法拉第时代的电。法拉第通过发现电磁感应现象,从而研制出人类第一台交流电发电机原型,不可谓不伟大。法拉第这批先行者,实践经验丰富,通过大量观察和反复实验,手工做出了各种新产品,但他们只是拉开了电气时代的序幕。电气时代的真正大发展,很大程度上受益于电磁场理论的提出。麦克斯维尔把实践的经验变成科学的理论,提出和证明了具有跨时代意义的麦克斯维尔方程。
如果人们对电磁的理解停留在法拉第的层次,电气革命是不可能发生的。试想一下,如果刮风下雨打雷甚至连温度变化都会导致断电,电怎么可能变成一个普惠性的产品,怎么可能变成社会基础设施?又怎么可能出现各种各样的电气产品、电子产品、通讯产品,彻底改变我们的生活方式?
这也是 AI 目前面临的问题,局限于特定的场景、特定的数据。AI 模型一旦走出实验室,受到现实世界的干扰和挑战就时常失效,鲁棒性不够;一旦换一个场景,我们就需要重新深度定制算法进行适配,费时费力,难以规模化推广,泛化能力较为有限。
这是因为今天的 AI 很大程度上是基于经验。AI 工程师就像当年的法拉第,能够做出一些 AI 产品,但都是知其然,不知其所以然,还未能掌握其中的核心原理。
那为何 AI 迄今未能成为一门科学?
答案是,技术发展之缓慢远超我们的想象。回顾 90 年代至今这二十多年来,我们看到的更多是 AI 应用工程上的快速进步,核心技术和核心问题的突破相对有限。一些技术看起来是这几年兴起的,实际上早已存在。
以自动驾驶为例,美国卡耐基梅隆大学的研究人员进行的 Alvinn 项目,在 80 年代末已经开始用神经网络来实现自动驾驶,1995 年成功自东向西穿越美国,历时 7 天,行驶近 3000 英里。在下棋方面,1992 年 IBM 研究人员开发的 TD-Gammon,和 AlphaZero 相似,能够自我学习和强化,达到了双陆棋领域的大师水平。
 (1995 年穿越美国项目开始之前的团队合照)
(1995 年穿越美国项目开始之前的团队合照)
不过,由于数据和算力的限制,这些研究只是点状发生,没有形成规模,自然也没有引起大众的广泛讨论。今天由于商业的普及、算力的增强、数据的方便获取、应用门槛的降低,AI 开始触手可及。
但核心思想并没有根本性的变化。我们都是试图用有限样本来实现函数近似从而描述这个世界,有一个 input,再有一个 output,我们把 AI 的学习过程想象成一个函数的近似过程,包括我们的整个算法及训练过程,如梯度下降、梯度回传等。
同样的,核心问题也没有得到有效解决。90 年代学界就在问的核心问题,迄今都未得到回答,他们都和神经网络、深度学习密切相关。比如非凸函数的优化问题,它得到的解很可能是局部最优解,并非全局最优,训练时可能都无法收敛,有限数据还会带来泛化不足的问题。我们会不会被这个解带偏了,忽视了更多的可能性?
毋庸讳言,以深度学习为代表的 AI 研究这几年取得了诸多令人赞叹的进步,比如在复杂网络的训练方面,产生了两个特别成功的网络结构,CNN 和 transformer。基于深度学习,AI 研究者在语音、语义、视觉等各个领域都实现了快速的发展,解决了诸多现实难题,实现了巨大的社会价值。
但回过头来看深度学习的发展,不得不感慨 AI 从业者非常幸运。
首先是随机梯度下降(SGD),极大推动了深度学习的发展。随机梯度下降其实是一个很简单的方法,具有较大局限性,在优化里面属于收敛较慢的方法,但它偏偏在深度网络中表现很好,而且还是出奇的好。为什么会这么好?迄今研究者都没有完美的答案。类似这样难以理解的好运气还包括残差网络、知识蒸馏、Batch Normalization、Warmup、Label Smoothing、Gradient Clip、Layer Scaling…尤其是有些还具有超强的泛化能力,能用在多个场景中。
再者,在机器学习里,研究者一直在警惕过拟合(overfitting)的问题。当参数特别多时,一条曲线能够把所有的点都拟合得特别好,它大概率存在问题,但在深度学习里面这似乎不再成为一个问题…虽然有很多研究者对此进行了探讨,但目前还有没有明确答案。更加令人惊讶的是,我们即使给数据一个随机的标签,它也可以完美拟合(请见下图红色曲线),最后得出拟合误差为 0。如果按照标准理论来说,这意味着这个模型没有任何偏差(bias),能帮我们解释任何结果。请想想看,任何东西都能解释的模型,真的可靠吗,包治百病的良药可信吗?
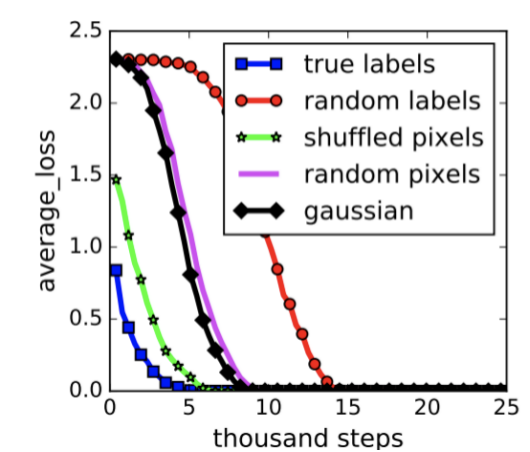 (Understanding deep learning requires rethinking generalization. ICLR, 2017.)
(Understanding deep learning requires rethinking generalization. ICLR, 2017.)
说到这里,让我们整体回顾下机器学习的发展历程,才能更好理解当下的深度学习。
机器学习有几波发展浪潮,在上世纪 80 年代到 90 年代,首先是基于规则(rule based)。从 90 年代到 2000 年代,以神经网络为主,大家发现神经网络可以做一些不错的事情,但是它有许多基础的问题没回答。所以 2000 年代以后,有一批人尝试去解决这些基础问题,最有名的叫 SVM(support vector machine),一批数学背景出身的研究者集中去理解机器学习的过程,学习最基础的数学问题, 如何更好实现函数的近似,如何保证快速收敛,如何保证它的泛化性?
那时候,研究者非常强调理解,好的结果应该是来自于我们对它的深刻理解。研究者会非常在乎有没有好的理论基础,因为要对算法做好的分析,需要先对泛函分析、优化理论有深刻的理解,接着还要再做泛化理论…大概这几项都得非常好了,才可能在机器学习领域有发言权,否则连文章都看不懂。如果研究者自己要做一个大规模实验系统,特别是分布式的,还需要有工程的丰富经验,否则根本做不了,那时候没有太多现成的东西,更多只是理论,多数工程实现需要靠自己去跑。
但是深度学习时代,有人做出了非常好的框架,便利了所有的研究者,降低了门槛,这真是非常了不起的事情,促进了行业的快速发展。今天去做深度学习,有个好想法就可以干,只要写上几十行、甚至十几行代码就可以跑起来。成千上万人在实验各种各样的新项目,验证各种各样新想法,经常会冒出来非常让人惊喜的结果。
但我们可能需要意识到,时至今日,深度学习已遇到了很大的瓶颈。那些曾经帮助深度学习成功的好运气,那些无法理解的黑盒效应,今天已成为它进一步发展的桎梏。
AI 的未来究竟在哪里?下一代 AI 将是什么?目前很难给出明确答案,但我认为,至少有三个方向值得重点探索和突破。
第一个方向是寻求对深度学习的根本理解,破除目前的黑盒状态,只有这样 AI 才有可能成为一门科学。具体来说,应该包括对以下关键问题的突破:
- 对基于 DNN 函数空间的更全面刻画;
- 对 SGD(或更广义的一阶优化算法)的理解;
- 重新考虑泛化理论的基础。
第二个方向是知识和数据的有机融合。
人类在做大量决定时,不仅使用数据,而且大量使用知识。如果我们的 AI 能够把知识结构有机融入,成为重要组成部分,AI 势必有突破性的发展。研究者已经在做知识图谱等工作,但需要进一步解决知识和数据的有机结合,探索出可用的框架。之前曾有些创新性的尝试,比如 Markov Logic,就是把逻辑和基础理论结合起来,形成了一些有趣的结构。
第三个重要方向是自监督学习和小样本学习。
我虽然列将这个列在第三,但却是目前值得重点推进的方向,它可以弥补 AI 和人类智能之间的差距。
今天我们经常听说 AI 在一些能力上可以超越人类,比如语音识别、图像识别,最近达摩院 AliceMind 在视觉问答上的得分也首次超过人类,但这并不意味着 AI 比人类更智能。谷歌 2019 年有篇论文《on the Measure of intelligence》非常有洞察力,核心观点是说,真正的智能不仅要具有高超的技能,更重要的是能否快速学习、快速适应或者快速通用?
按照这个观点,目前 AI 是远不如人类的,虽然它可能在一些方面的精度超越人类,但可用范围非常有限。这里的根本原因在于:人类只需要很小的学习成本就能快速达到结果,聪明的人更是如此——这也是我认为目前 AI 和人类的主要区别之一。
有一个很简单的事实证明 AI 不如人类智能,以翻译为例,现在好的翻译模型至少要亿级的数据。如果一本书大概是十几万字,AI 大概要读上万本书。我们很难想象一个人为了学习一门语言需要读上万本书。
另外有意思的对比是神经网络结构和人脑。目前 AI 非常强调深度,神经网络经常几十层甚至上百层,但我们看人类,以视觉为例,视觉神经网络总共就四层,非常高效。而且人脑还非常低功耗,只有 20 瓦左右,但今天 GPU 基本都是数百瓦,差了一个数量级。著名的 GPT-3 跑一次,碳排放相当于一架 747 飞机从美国东海岸到西海岸往返三次。再看信息编码,人脑是以时间序列来编,AI 是用张量和向量来表达。
也许有人说,AI 发展不必一定向人脑智能的方向发展。我也认为这个观点不无道理,但在 AI 遇到瓶颈,也找不到其他参照物时,参考人脑智能可能会给我们一些启发。比如,拿人脑智能来做对比,今天的深度神经网络是不是最合理的方向?今天的编码方式是不是最合理的?这些都是我们今天 AI 的基础,但它们是好的基础吗?
应该说,以 GPT-3 为代表的大模型,可能也是深度学习的一个突破方向,能够在一定程度上实现自学习。大模型有些像之前恶补了所有能看到的东西,碰到一个新场景,就不需要太多新数据。但这是一个最好的解决办法吗?我们目前还不知道。还是以翻译为例,很难想象一个人需要装这么多东西才能掌握一门外语。大模型现在都是百亿、千亿参数规模起步,没有一个人类会带着这么多数据。
所以,也许我们还需要继续探索。
说到这里,也许有些人会失望。既然我们 AI 还未解决上面的三个难题,AI 还未成为科学,那 AI 还有什么价值?
技术本身就拥有巨大价值,像互联网就彻底重塑了我们的工作和生活。AI 作为一门技术,当下一个巨大的机会就是帮助解决科学重点难题(AI for Science)。AlphaFold 已经给了我们一个很好的示范,AI 解决了生物学里困扰半个世纪的蛋白质折叠难题。
我们要学习 AlphaFold,但没必要崇拜。AlphaFold 的示范意义在于,DeepMind 在选题上真是非常厉害,他们选择了一些今天已经有足够的基础和数据积累、有可能突破的难题,然后建设一个当下最好的团队,下决心去攻克。
我们有可能创造比 AlphaFold 更重要的成果,因为在自然科学领域,有着很多重要的 open questions,AI 还有更大的机会,可以去发掘新材料、发现晶体结构,甚至去证明或发现定理…AI 可颠覆传统的研究方法,甚至改写历史。
比如现在一些物理学家正在思考,能否用 AI 重新发现物理定律?过去数百年来,物理学定律的发现都是依赖天才,爱因斯坦发现了广义相对论和狭义相对论,海森堡、薛定谔等人开创了量子力学,这些都是个人行为。如果没有这些天才,很多领域的发展会推迟几十年甚至上百年。但今天,随着数据越来越多,科学规律越来越复杂,我们是不是可以依靠 AI 来推导出物理定律,而不再依赖一两个天才?
以量子力学为例,最核心的是薛定谔方程,它是由天才物理学家推导出来的。但现在,已有物理学家通过收集到的大量数据,用 AI 自动推导出其中规律,甚至还发现了薛定谔方程的另外一个写法。这真的是一件非常了不起、有可能改变物理学甚至人类未来的事情。
我们正在推进的 AI EARTH 项目,是将 AI 引入气象领域。天气预报已有上百年历史,是一个非常重大和复杂的科学问题,需要超级计算机才能完成复杂计算,不仅消耗大量资源而且还不是特别准确。我们今天是不是可以用 AI 来解决这个问题,让天气预报变得既高效又准确?如果能成功,将是一件非常振奋人心的事情。当然,这注定是一个非常艰难的过程,需要时间和决心。
AI 的当下局面,是对我们所有 AI 研究者的考验。不管是 AI 的基础理论突破,还是 AI 去解决科学问题,都不是一蹴而就的事情,需要研究者们既聪明又坚定。如果不聪明,不可能在不确定的未来抓住机会;如果不坚定,很可能就被吓倒了。
但更关键的是兴趣驱动,而不是利益驱动,不能急功近利,这些年深度学习的繁荣,使得中国大量人才和资金涌入 AI 领域,快速推动了行业发展,但也催生了一些不切实际的期待。像 DeepMind 做了 AlphaGo 之后,中国一些人跟进复制,但对于核心基础创新进步来说意义相对有限。
既然 AI 还不是一门科学,我们要去探索没人做过的事情,很有可能失败。这意味着我们必须有真正的兴趣,靠兴趣和好奇心去驱动自己前行,才能扛过无数的失败。我们也许看到了 DeepMind 做成了 AlphaGo 和 AlphaFold 两个项目,但可能还有更多失败的、无人听闻的项目。
在兴趣驱动方面,国外研究人员值得我们学习。像一些获得图灵奖的顶级科学家,天天还在一线做研究,亲自推导理论。还记得在 CMU 读书的时候,当时学校有多个图灵奖得主,他们平常基本都穿梭在各种 seminar(研讨班)。我认识其中一个叫 Manuel Blum,因为密码学研究获得图灵奖,有一次我参加一个 seminar,发现 Manuel Blum 没有座位,就坐在教室的台阶上。他自己也不介意坐哪里,感兴趣就来了,没有座位就挤一挤。我曾有幸遇到过诺贝尔经济学奖得主托马斯·萨金特,作为经济学者,他早已功成名就,但他 60 岁开始学习广义相对论,70 岁开始学习深度学习,76 岁还和我们这些晚辈讨论深度学习的进展…也许这就是对研究的真正热爱吧。
说回国内,我们也不必妄自菲薄,中国 AI 在工程方面拥有全球领先的实力,承认 AI 还比较初级并非否定从业者的努力,而是提醒我们需要更坚定地长期努力,不必急于一时。电气时代如果没有法拉第这些先行者,没有一个又一个的点状发现,不可能总结出理论,让人类迈入电气时代。
同样,AI 发展有赖于我们以重大创新为憧憬,一天天努力,不断尝试新想法,然后才会有一些小突破。当一些聪明的脑袋,能够将这些点状的突破联结起来,总结出来理论,AI 才会产生重大突破,最终上升为一门科学。
我们已经半只脚踏入 AI 时代的大门,这注定是一个比电气时代更加辉煌、激动人心的时代,但这一切的前提,都有赖于所有研究者的坚定不移的努力。
内容来源:作者:金榕 阿里巴巴达摩院副院长、原密歇根州立大学终身教授
![]()