

在智能营销场景下,比如美团的满减优惠券,淘宝的购物红包等,需要形成系统化的营销决策。基于此类场景,快手为了实施更细粒度的营销决策,提出了一种新的多元因果森林模型。基于快手亿级别的用户量,快手社区科学部设计了资源分配并行算法,高效产出智能营销决策。为了解决多元因果模型的评估问题,该研究利用随机匹配的思想,提供了一个供业界参考的方法。最后,通过线下仿真实验和线上真实 A/B 实验,验证了 LBCF 算法的有效性,该技术已经申请中国发明专利,并在快手智能营销业务中获得广泛应用。
异质性因果效应 (HTE) 是因果推断理论需要解决的核心问题,其概念最初来源于医疗领域。HTE 是指对于同一种干预手段,对不同受众的影响因人而异,在计算广告、个性化治疗、个性化教育以及公共政策等领域都有广泛的应用。为理解其概念,举个智能营销领域的例子,对于同一补贴力度的营销手段,某些受众会立即转化,而某些受众可能根本不会转化,如何准确区分出这些受众便是 HTE 需要解决的问题。近年来,学术界不断涌现新的 HTE 方法,其中斯坦福大学经济学教授 Susan Athey 等人提出的因果森林模型【1】因其良好的可解释性和出色的效果在业界获得逐步认可。

- 论文链接:https://arxiv.org/abs/2201.12585
- 论文代码:https://github.com/www2022paper/WWW-2022-PAPER-SUPPLEMENTARY-MATERIALS
大规模智能营销算法
多元因果森林模型
智能营销要研究的核心问题是,用户对不同补贴额度的转化效果差异有多大?这些不同的补贴额度可以被看作是因果推断中的 treatments,所以场景驱使研究者去研究用户在不同 treatments 下的转化效果,即需要多元因果模型。以树为基础的模型具有良好的解释性并且在机器学习中展现了很好的效果,在本文中,该研究主要考虑以树模型为基础的 HTE 预估方法。该方法可以应用于任何需要预估 HTE 的领域,本文仅以智能营销场景为例进行阐释。
本文提出的多元因果森林模型,模型结构如图 2(示意的例子),该模型结构有两个优点:第一,单一一个模型能够同时处理任意种干预手段,否则,几种干预手段就需要维护相应数量的二元因果森林模型;第二,HTE 的定义要求各干预手段对应一致的特征子空间,该模型结构保证了这一点,这对准确估计 HTE 至关重要。
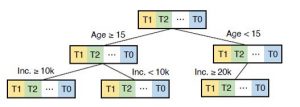
图 2 多元因果森林模型 (注:图 2 中的 Age,Inc. 等数据仅为了示意说明)
为此,该研究重新设计了因果森林的分裂准则,在每一次对树节点进行分裂时,不但强调不同节点间的异质性,即节点间分裂(Inter Split),同时也强调节点内不同干预手段的异质性,即节点内分裂(Intra Split)。从计算复杂度来说,在寻找一个树节点的特征分裂点时,Inter Split 可以快速一次性预先计算出分裂所需数据,而 Intra Split 依赖于树节点间分裂的结果,因此 Intra Split 每次都需要重新计算分裂数据,极其低效。为了平衡算法的效率和效果,该研究采用了两步走的分裂算法:
- 第一步通过 Inter Split 选择 top N 个备选特征分裂点;
- 第二步通过 Intra Split 从 N 个备选中选择一个最终的特征分裂点。
资源分配并行算法
解决了用户弹性的预估问题之后,在智能营销领域输出营销决策时,我们经常需要去回答,在有限的资源约束下如何去实现最优分配。为此,该研究把智能营销中的资源分配问题建模成了有约束的整数规划数学模型,如图 3。但是,快手亿级别的用户量导致决策变量数目巨大,很多目前开源的求解器不能满足性能的需求,会存在内存溢出等问题。

图 3 整数规划数学模型
为此,该研究设计了可并行的 Dual Gradient Bisection(DGB)算法,如图 4。该算法在不损失解质量的情况下,实现了亿级用户量的分钟级求解。限于篇幅,这里简单描述下求解思路,详细的可以参阅论文和附录 code。
- 第一步,利用线性松弛技术,把图 3 的整数规划数学模型简化成易于求解的线性规划问题,可以证明松弛后的线性规划问题的解集至多只在预算临界处有一个非整数解。
- 第二步,通过拉格朗日乘子把有约束问题转化为无约束问题。
- 第三步, 由于该问题满足强对偶条件,研究者对该问题进行对偶转化,由此得到了一个关于拉格朗日乘子的单变量分段函数,并且可以证明该分段函数为闭区间上的凸函数。
- 第四步,通过图 4 的 DGB 算法,研究者可以在并行系统上高效求出。
- 第五步,代回对偶问题,便可依次求解出所有决策变量的值。

图 4 可并行的 DGB 算法
多元因果模型评估
因为无法观测到因果模型的反事实结果(Counterfactual Outcome),因此,如何评估因果模型的线下效果成了业界亟待解决的问题,常用的评估方法有 AUUC/Qini Curve 等,但这些更适合评估二元因果模型;对于多元因果模型的预估结果,也只能是先把多元结果拆解成许多二元结果,之后再进行分别评估。
本文利用随机控制实验 (RCT) 数据,基于 Treatment Matching 的思想,提供了整体收益对比的方法。核心方法是:在 RCT 数据中找出 Policy Treatment 和 RCT Treatment 匹配的那些样本,需要指出的是,对于这些匹配样本,我们是可以观测到其真实结果的。其次,可以证明这些匹配样本的均值是其各列期望的好的估计。最后,利用各列的期望值,我们可以计算出多元因果模型的整体收益,收益越高,模型越好。
效果展示
为了公平的对比算法效果,首先,该研究利用 Ye Tu 等人在 WWW 2021 公开的仿真数据集【2】,与业界主流的以树为基础的因果模型进行了线下对比,如图 5,横轴是数据集噪声的强弱,纵轴是研究者关注的核心指标的收益,可以看出,LBCF 效果最好,CT.ST 和 CF.DT 次之。
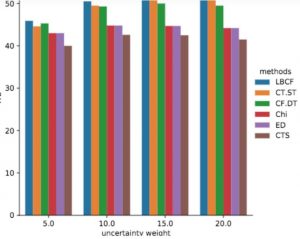
图 5 线下仿真实验
进一步,该研究在快手的真实智能营销场景下部署了 LBCF 算法,进行了两周的 A/B 实验,如图 6,结果也证明了该算法的有效性,与 CT.ST 和 CF.DT 算法相比,收益分别提高了 0.92 和 2.48 个百分点。

图 6 线上 A/B 实验
总结
在本文中,快手的研究者们提出了一种新的 HTE 预估方法——多元因果森林模型,并且结合高效的整数规划求解算法,效果显著优于业界常用的几种树模型方法。同时,对于业界棘手的因果效应离线评估问题,研究者们也创新地给出了一个可行的解决方案。研究者们希望本文的工作能够引起机器学习爱好者们的关注,以更广泛地应用因果推断技术在各自的实际业务中。