


HubSpot 的一些最大的数据集存储在 HBase 中,这是一个开源的、分布式的、版本化的、非关系型的数据库,模仿谷歌的 BigTable。我们拥有将近 100 个生产 HBase 集群,包括亚马逊云科技两个区域的 7000 多个 RegionServer。这些集群每天能处理 2.5PB 以上的低延迟流量,由于亚马逊云科技的每个区域是由多个数据中心组成的,因此我们认为,Locality(译注:即局部性 、本地性,指将数据放在离需要者尽可能近的地方)是保持这些延迟的关键。
HBase 数据存储在 HDFS 中,默认情况下,会有 3 种方式来复制你的数据。
- 如果可能的话,第一个副本会在本地写入客户端(HBase RegionServer)。
- 第二个副本被写到与第一个副本不同机架上的主机上。
- 第三个副本被写到第二个机架上的不同主机上。
所有这些都是很好的做法,但是 HBase 数据也被分割成了连续的小块,称为区域(regions)。区域必须能迅速地在不同的主机间移动,从而在托管 RegionServer 崩溃等情况下,能够维持可用性。为了保证快速,当一个区域移动时,底层数据块不会移动。HBase 依然可以轻松地从 3 个副本主机中仍然可用的任意一个远程获得数据,从而为该区域提供数据。
在高度优化的单一数据中心中,远程主机的访问对延迟的影响微乎其微。在云中,这些副本主机可能与请求的 RegionServer 不在同一栋楼里,甚至不在同一个地区。在运行一个对延迟敏感的应用程序时,这个附加的网络跳跃会对终端用户的性能造成很大的影响。
Locality 是衡量 RegionServer 的数据在给定时间内存储在本地的百分比,这也是我们在 HubSpot 非常密切监测的一个指标。HDFS 除了具有网络延迟之外,还具有“短路读取”的特性。当数据在本地时,通过短路读取,可以使客户端(HBase)在不通过集中的 HDFS 数据节点处理的情况下,从磁盘上直接读出数据文件。这将会降低可能来自 TCP 栈或 DataNode 进程本身的延迟。
在过去的几年中,我们一直在定期进行性能测试,以确认 Locality 对延迟的影响。下面是我们最近一次测试的一些结果

所有这四个图表都有相同的时间窗口。在这个时间窗口开始时,我打乱了处理集群上的 Locality。正如你所看到的,单个 Get 延迟(左上图)没有受到很大的影响,但吞吐量(右上图)却显著地下降了。MultiGets 在延迟(左下角)和吞吐量(右下角)方面受到明显的影响。我们发现,一般来说,MultiGets 对延迟回归格外敏感,因为它们会击中多个 RegionServer,通常至少与最慢的目标一样慢。
下面是几个月前我们遇到的一个生产事故的例子:
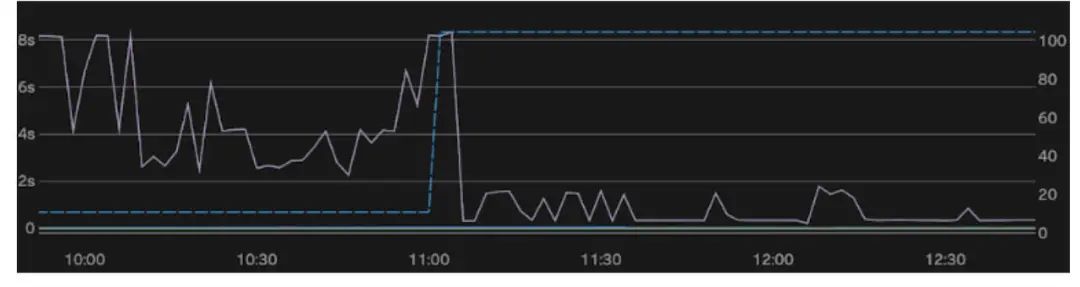
这个集群有一个相对较小的数据集,但负载较重。左轴(浅紫色)是第 99 个百分点的延迟,而右轴(蓝色虚线)是 Locality。在这次事件中 ,Locality 约为 10%,延迟在 2~8 秒之间。利用我们将在本文讨论的工具,我们在 11 点左右解决了这个问题——在短短几分钟内,我们就将 Locality 提高到 100%,并使延迟减少到不足 1 秒。
Locality 可能会因为不同的原因而下降,而所有这些原因都源于区域的移动:
- RegionServer 可能会崩溃,所以它的所有区域会随机地分布在集群中。
- Balancer 可能会移动一些区域以更好地分配请求负载。
- 你可能会扩大或缩小集群的规模,从而导致区域移动以适应新的规模。
以上三种理由在我们看来都是很普遍的。当 Locality 下降时,你有两种选择:
- 利用 Balancer 将区域移回它们有良好 Locality 的地方。这很少是一个好的选择。
- 在本地重写数据,使用“高度压实”(major compaction)。
HBase 中的数据最初被写到内存中。当内存中的数据达到一定的阈值时,它就会被刷到磁盘上,从而形成不可变的 StoreFile。由于 StoreFile 是不可变的,所以更新和删除不会对数据进行直接的修改。取而代之的是,它们和其他新的数据一起,被写入到新的 StoreFile 中。久而久之,你就会创建很多 StoreFile,在读取时,这些更新需要跟旧数据进行协调。这种即时的审核会减慢读取速度,因此会执行后台维护任务来合并 StoreFile。这些任务被称为“压实”(compaction),它们被分成两种类型:轻度(minor)压实和高度(major)压实。
轻度压实只是将较小的、相邻的 StoreFile 合并成较大的 StoreFile,以减少在许多文件之间寻找数据的需要。高度压实则是重写一个区域内的所有 StoreFile,将所有更新和删除的数据合并成一个 StoreFile。
回到 Locality 的定义,我们的目标是确保新的托管服务器对 StoreFile 中的每个块都有一个本地副本。通过现有的工具,做到这一点的唯一方法是重写数据,这要经过上述的块放置策略。要做到这一点,高度压实会非常重要,因为它们涉及重写所有数据。不幸的是,它们也是非常昂贵的:
- 压实必须读取整个区域的数据,过滤掉不相干的数据,然后重写数据。
- 读取数据包括解压和解码,这需要 CPU。过滤也需要 CPU。写入数据需要对新数据进行编码和压实,而这需要更多的 CPU。
- 写入数据还涉及 3 倍的复制。因此,对 10GB 的区域进行压实会导致 10GB 的读取 + 30GB 的写入。
无论我们的 Locality 目标是什么,这种成本都会在每一个高度压实中体现出来,而且会对长尾延迟产生影响。通常,你只想在非工作时间运行高度压实操作,以尽量减少对终端用户的影响。然而 ,Locality 在高峰期有最大的影响,所以这意味着在你等待非高峰期压实工作开始时,可能会有几个小时的痛苦。
就 Locality 而言,还有一个隐藏的成本——很有可能只有某个区域的部分 StoreFile,有非常糟糕的 Locality。一个高度压实会压实所有的 StoreFile,因此,如果一个 10GB 的区域中只有 1GB 是非本地的,那么从 Locality 的角度来看,这就是浪费了 9GB 的努力。
下面是我们的一个集群的图表,我们试图通过压实来修复 Locality :
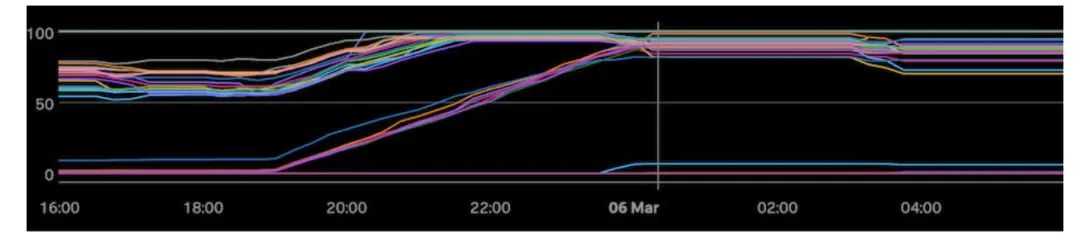
这张图显示了一个相对较大的 HBase 集群,每条线是集群中单个 Regionserver 的 Locality。在我们耗尽时间之前,我们花了大约 6 个小时,才慢慢将 Locality 提高到一个只有 85% 左右的峰值。几个小时后,发生了一起事件,使我们的部分工作毁于一旦,而按照集群的负载方式,我们要等到第二天晚上才能继续运行压实操作。
多年来,上述情景一再出现。当我们的规模变大时,我们发现,压实并不能很好地对 SLO 进行足够快的 Locality 修复。我们的相隔更好的办法。
我在 HBase 上断断续续地试用了好几年,而用压实来解决 Locality 的做法总是令人失望。我很久以前就了解过诸如 HDFS Balancer 和 Mover 之类的工具,它们可以进行低级别的块移动。如果有一个类似的工具,可以利用低级别的块移动来解决 Locality 问题,这将会很有吸引力,原因有以下几点:
- 你只是把字节从一个主机移到另一个主机,不需要处理压实、编码或昂贵的过滤。
- 你在做 1-1 的转移,而不是写新的块。因此,3 倍的复制成本并没有发挥作用。
- 你可以专门选择只移动非本地块的复制,而不去考虑其他所有的块。
通过 dfsadmin -setBalancerBandwidth,可以实时地编辑块传输带宽,而且可以很好地根据集群的大小进行扩展。
在这个项目中,我希望能看到我们能不能开发出相似的产品,从而提高低延时应用的 Locality。
为了建立我们自己的块 Mover,我必须采取的第一步是了解移动块、读取块和计算 Locality 的所有各种组件。这一节有点深奥,所以如果你只想了解我们的解决方案和结果,请跳到下一节。
Balancer 和 Mover 的核心是 Dispatcher。这两个工具都将 PendingMove 对象传递给 Dispatcher,Dispatcher 处理在远程 DataNodes 上执行 replaceBlock 调用。HBase 集群的典型块大小为 128MB,而区域通常为多个 GB。因此,一个区域可能有十几个到几百个块,一个 RegionServer 可能承载 50 到数百个区域,而一个集群可能有数百或数千个 RegionServer。Dispatcher 的工作是并行地执行许多这样的 replaceBlock 调用,当远程 DataNode 进行数据拷贝时,它会追踪进度。这个 Dispatcher 不会处理所选定的要移动的副本,因此我必须创建一个流程来检测低 Locality 区域,并将这些区域转化为 PendingMove 对象。
远程 DataNode 从 Dispatcher 接收 replaceBlock 调用,其中包括 blockId、源和目标。然后,数据通过代理 DataNode 从源头流向目标。
当目标 DataNode 完成接收块时,它会通过 RECEIVED_BLOCK 状态更新来通知 NameNode。该状态更新包括对用于托管该块的 DataNode 的引用。NameNode 会更新其内存中的块记录,并将旧的 DataNode 标记为 PendingDeletion。在这一点上,调用获取块的 Locality 将包括新的和旧的 DataNode。
当下一次旧的 DataNode 报告时,NameNode 会回应:“谢谢,现在请删除这个块。” 当 DataNode 完成删除块时,它再次向 NameNode 发出 DELETED_BLOCK 状态更新。当 NameNode 收到这个更新时,该块被从其内存记录中删除。在这一点上,对块 Locality 的调用将只包括新的 DataNode。
HBase 在打开每个 StoreFile 时都会创建一个持久的 DFSInputStream,用于服务该文件的所有 ReadType.PREAD 读取。当 STREAM 读入时,它会打开额外的 DFSInputStream,但 PREAD 对延迟最为敏感。当一个 DFSInputStream 被打开时,它获取文件前几个块的当前块位置。在读取数据的时候,利用这些块的位置来决定从何处获取块数据。
如果 DFSInputStream 试图从一个崩溃的 DataNode 提供数据,该 DataNode 将被添加到一个 deadNode 列表,并将其排除在将来的数据请求之外。然后 DFSInputStream 将从 deadNodes 列表以外的其他块位置之一重试。如果 DFSInputStream 试图从不再提供块服务的 DataNode 中获取块,也会出现类似的过程。在这种情况下,ReplicaNotFoundException 将被抛出,并且该 DataNode 也同样被添加到 deadNode 列表中。
一个单一的 StoreFile 可以从几 KB 到十几 GB 不等。由于块的大小为 128MB,这意味着一个单一的 StoreFile 可能有数百个块。如果一个 StoreFile 具有较低的 Locality (本地副本很少),这些块就会分散在集群的其余部分。随着 DataNode 被添加到 deadNode 列表中,你会越来越有可能遇到一个所有位置都在 deadNode 列表中的块。在这一点上,DFSInputStream 会回退(默认为 3 秒),并从 NameNode 重新获取所有块的位置。
除非有一个更系统的问题,否则所有这些错误处理将导致暂时性的延迟增加,但不会引起客户端的异常。不幸的是,延迟的影响是明显的(尤其是 3 秒的回退),所以这里还有改进的空间。
在 RegionServer 上打开 StoreFile 时,RegionServer 会调用 NameNode 自身来获取该 StoreFile 中的所有块位置。这些位置被累积到每个 StoreFile 的 HDFSBlockDistribution 对象中。这些对象被用来计算 localityIndex,并通过 JMX、RegionServer 的 Web UI 和管理界面报告给客户。RegionServer 本身也将 localityIndex 用于某些与压实有关的决策,并且它将每个区域的 localityIndex 报告给 HMaster。
HMaster 是 HBase 进程,运行 HBase 自身的 Balancer。Balancer 试图根据许多成本函数来平衡整个 HBase 集群中的区域:读取请求、写入请求、存储文件数量、存储文件大小等等。它试图平衡的一个关键指标是 Locality。
Balancer 的工作方式是通过对集群成本的计算,假装将一个区域移动到一个随机的服务器,再对集群成本进行重新计算。若成本降低,则接受这个移动。否则,尝试不同的移动。为了通过 Locality 进行平衡,你不能简单地使用 RegionServers 报告的 localityIndex,因为你需要能够计算出,如果一个区域移动到一个不同的服务器 ,Locality 成本会是多少。所以 Balancer 也维护它自己的 HDFSBlockDistribution 对象的缓存。
在了解了现有组件之后,我就开始了一项新的守护程序的工作,我们亲切地称之为 LocalityHealer。通过深入研究 Mover 工具之后,我想出了一个设计来实现守护程序的工作方式。这项工作的关键在于两个部分:
- 发现哪些区域需要愈合。
- 将这些区域转换为 Dispatcher 的 PendingMoves。
HBase 提供了一个 Admin#getClusterMetrics() 方法,可以对集群的状态进行轮询。返回值包括一堆数据,其中之一是集群中每个区域的 RegionMetrics。这个 RegionMetric 包括一个 getDataLocality() 方法,而这正是我们想要监控的。因此,这个守护进程的第一个组成部分是一个监控线程,它不断地轮询哪些 getDataLocality() 低于我们阈值的区域。
一旦我们知道哪些区域是我们需要愈合的,我们就有一个复杂的任务,就是把它变成一个 PendingMove。一个 PendingMove 需要一个块、一个源和一个目标。到目前为止,我们所拥有的是一个区域的列表。每个区域由 1 个或多个列族组成,每个列族有 1 个或多个 StoreFile。因此,下一步是在 HDFS 上递归搜索该区域的目录,寻找 StoreFile。对于每个 StoreFile,我们得到当前块的位置,为每个块选择一个副本作为源,并为每个块创建一个 PendingMove,目标是当前托管的 RegionServer。我们之所以选择移动源,是为了保证我们遵循了 BlockPlacementPolicy,并且最大限度地降低了在不同机架之间的网络流量。
一旦我们把所有生成的 PendingMoves 移交给 Dispatcher,就只需要等待它完成。当它完成后,我们再等待一个宽限期,让我们的 Locality 监视器注意到更新的 Locality 指标,然后重复这整个过程。这个守护进程一直持续这个循环,直到它关闭。如果 Locality 是 100%(现在经常是这样),那么在监视器线程发现下降之前,它会一直闲置。
因此,这个守护进程是运行的,并且保证所有 RegionServer 上的 DataNode 都会为这个 RegionServer 上的全部区域托管一个块副本。但 DFS InputStream 仅在开始时或者在特定的条件下才能获得块的位置,而在每一个 StoreFile 中都有一个持久的 DFS InputStream。实际上,如果你继续追踪,你也许会发现,如果块不断地移动,我们将会发现很多 ReplicaNotFoundException。这实际上是一种痛苦,最好能避免。
当我在三月份最初构建这个系统时,就已经决定使用回调函数来刷新 HBase 中的读取数据。我对 HBase 最熟悉,这也是阻力最小的方法。我为 HMaster 和 RegionServer 推送了新的 RPC 端点到我们的内部分叉。当 LocalityHealer 处理完一个区域的所有 StoreFile 后,它就会调用这些新的 RPC。RegionServer 的 RPC 特别棘手,需要进行一些复杂的锁定。最后,它所做的是重新打开存储文件,然后在后台透明地关闭旧的存储文件。这个重新打开的过程将创建一个新的 DFSInputStream,其中有正确的块位置,并更新报告的 Locality 值。
自那以后,这个部署的系统取得了非常大的成功,但是我们目前正在进行一次重大的版本升级,需要让它在新版本中工作。结果发现这个问题要复杂得多,所以我决定尝试为这部分设计一种不同的方法。本博客的其余部分提到了新的 v2 方法,该方法自 10 月份以来已经全面部署。
在调查我们的主要版本升级时,我发现 HDFS-15199 为 DFSInputStream 添加了一个特性,可以在打开时周期性地重新读取块位置。这似乎正是我想要的,但是在阅读实现时,我意识到,重新获取是直接建立在读取路径上的,并且无论是否需要,它都会发生。对于这个问题的最初目标,即每隔几小时刷新一次位置,这似乎很好,但我最多只需要每隔几分钟刷新一次。在 HDFS-16262 中,我采纳了这个想法,并使其成为异步的和有条件的。
现在,DFSInputStream 将只在有 deadNode 或任何非本地块的情况下重新获取块的位置。重新获取的过程发生在任何锁之外,而新的位置会被快速地与锁交换到位。这对读取的影响应该非常小,特别是相对于 DFSInputStream 中现有的锁的语义。通过使用异步方法,我觉得它可以在 30 秒的计时器上进行刷新,这样我们就能够很快地适应块移动。
这种异步刷新块位置的新方法,意味着一堆 DFSInputStream 在不同的时间都会影响到 NameNode。如果 Locality 良好,请求的数量应该是零或接近零。一般来说,当你运行 LocalityHealer 的时候,你可以期望你的整体集群的 Locality 几乎一直在 98% 以上。所以在正常情况下,我是不会担心这个问题的。我所关心的一件事是,如果我们发生了一个完全的故障,并且 Locality 几乎为零,那会是什么样子。
我们倾向于分割大型集群,而不是让它们变得过于庞大,所以我们最大的集群有大约 350k 个 StoreFile。在最坏的情况下,所有这些文件每 30 秒就会向 NameNode 发出一次请求。这意味着大约 12000 次 / 秒。我有一种预感,这不会是一个大问题,因为这些数据完全在内存中。我们用 8 个 CPU 和足够的内存来运行我们的 NameNode,以覆盖块的容量。
HDFS 有一个内置的 NNThroughputBenchmark,可以准确地模拟出我所期望的工作负载。我首先在我们的 QA 环境中对一个 4 块 CPU 的 NameNode 进行了测试,使用了 500 个线程和 50 万个文件。这个单一的负载测试实例能够推动 22k req/s,但 NameNode 上仍有 30%-40% 的 CPU 闲置时间。这比我们最坏的情况下的两倍还多,而且非常有希望。
我很好奇 prod 能做什么,所以我在一个 8 块 CPU 的 NameNode 上运行它。它很容易就能推送 24k req/s,但我注意到 CPU 几乎是闲置的。在我使用的测试主机上,我已经达到了该基准的最大吞吐量。我在另一台主机上针对同一个 NameNode 启动了另一个并发测试,看到总吞吐量跃升至超过 40k req/s。我继续扩大规模,最终在超过 60k req/s 时停止。即使在这个水平上,闲置的 CPU 仍然超过 30%~45%。我相信,对我们的 NameNode 来说,这样的负载不会有任何问题。
早期部署的 locality healer 在运行时确实产生了一些小麻烦。这都要追溯到我之前提到的 ReplicaNotFoundException,它有时会导致昂贵的回退。当我第一次做这个工作时,我提交了 HDFS-16155,它增加了指数回退,使我们能够将 3 秒减少到 50 毫秒。这对解决这个问题很有帮助,使它变得非常容易管理,而且为了长期改善 Locality 也是值得的。
作为我对 HDFS-16262 调查的一部分,我学到了更多的东西,说明了当一个块被替换后,这个过程是无效的。我在描述上面的组件时简要介绍了这一点,同时也让我意识到,我可以完全消除这种痛苦。如果我可以在 NameNode 发出的“请删除此块”的消息周围增加一个宽限期呢?这个想法的结果就是 HDFS-16261,在那里我实现了这样一个宽限期。
有了这个特性,我在我们的集群上配置了一个 1 分钟的宽限期。这让 DFSInputStream 中的 30 秒刷新时间有足够的时间来刷新块的位置,然后再把块从它们的旧位置上移走。这就消除了 ReplicaNotFoundException,以及任何相关的重试或昂贵的回退。
这里的最后一块拼图是更新我提到的 localityIndex 指标,以及 Balancer 自己的缓存。这一部分由 HBASE-26304 覆盖。
对于 Balancer,我利用了 RegionServer 每隔几秒钟向 HMaster 报告它们的 localityIndex 这一事实。这被用来建立你在调用 getClusterMetrics 时查询的 ClusterMetrics 对象,并且它也被注入到 Balancer 中。这个问题的解决方法很简单:在注入新的 ClusterMetrics 时,将其与现有的进行比较。对于任何区域,其报告的 localityIndex 发生了变化,这是一个很好的信号,表明我们的 HDFSBlockDistribution 缓存已经过期。把它作为一个信号来刷新缓存。
接下来是确保 RegionServer 首先报告正确的 localityIndex。在这种情况下,我决定从支持 PREAD 读取的底层持久化 DFSInputStream 中导出 StoreFile 的 HDFSBlockDistribution。DFSInputStream 公开一个 getAllBlocks 方法,我们可以轻松地将其转换为 HDFSBlockDistribution。以前,StoreFile 的块分布是在 StoreFile 打开时计算的,而且从未改变。现在我们从底层的 DFSInputStream 派生出来,随着 DFSInputStream 本身对块移动的反应(如上所述),这个值会随着时间自动改变。
首先,我要让数据来说明问题。我们在 3 月中旬开始向一些问题较多的集群推出 LocalityHealer,并在 5 月初完成向所有集群的推出。
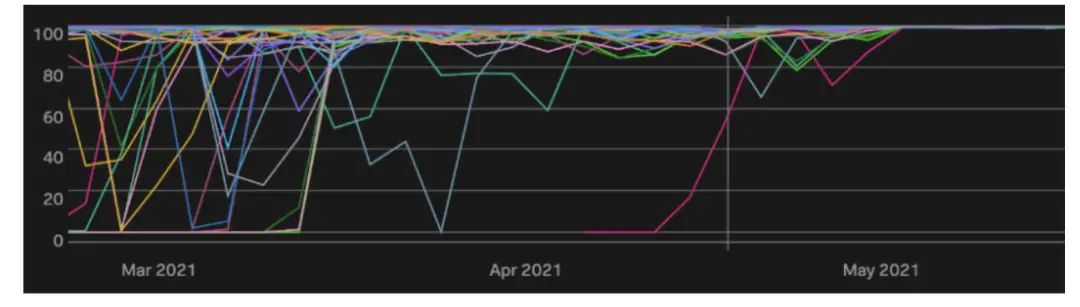
该图表显示了从 2021 年 3 月 1 日到 2021 年 6 月 1 日,我们所有生产集群的第 25 百分点的 Locality 值。在 3 月之前,我们看到许多下降到 90% 以下,一些集群持续下降到几乎 0%。随着我们开始推出 LocalityHealer,这些下降变得不那么频繁和严重。一旦 LocalityHealer 被完全推出,它们就完全被消除了。
我们喜欢把 Locality 保持在 90% 以上,但注意到当 Locality 低于 80% 时,真正的问题就开始显现出来。另一种看问题的方法是,在一个区间内 ,Locality 低于 80% 的 RegionServer 的数量。
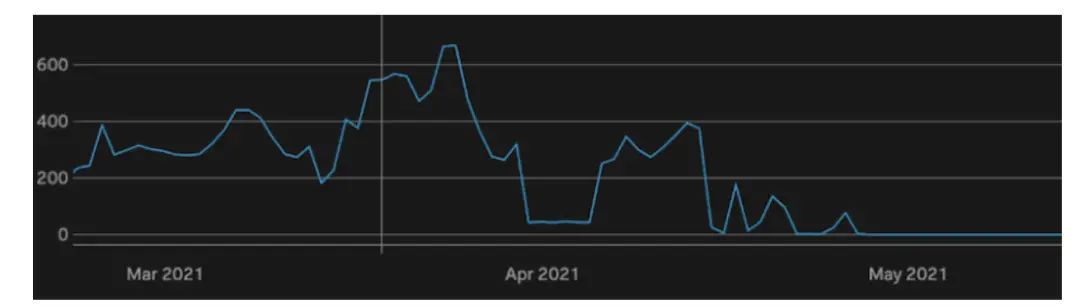
这张图显示了与上面相同的时间段,你可以看到我们曾经有数百个服务器在任何特定时刻都低于 80% 的 Locality。从 5 月初开始,这个数值一直为 0,并保持到今天。
这些图表最好的一点是它是自动的。遗憾的是,由于 Locality ,我们没有警报量的指标标准,但 HBase 团队的任何人都可以告诉你,他们曾经几乎每天都会因为某个集群的 Locality 而被呼唤。这一直是一个令人讨厌的警报,因为你唯一能做的就是启动需要数小时才能完成的高度压实。随着时间的推移,我们降低了 Locality 警报的敏感性,以避免警报疲劳,但这对集群的稳定性产生了负面影响。
有了 LocalityHealer,我们就不再考虑 Locality 问题了。我们可以使我们的警报非常敏感,但它们永远不会发出。Locality 总是接近 100%,我们可以专注于其他的操作问题或价值工作。
这里还有一个关于仅承载 15TB 的特定集群的示例。你可以看到在时间线的开始附近,棕色的线是一个新的服务器,它以 Locality 为 0 启动。在时间耗尽之前,压实花了大约 7 个小时才达到大约 75% 的 Locality。那天晚上晚些时候,增加了更多的服务器,但对它们开始压实为时已晚(由于其他任务,如备份,在凌晨运行)。

当我们在第二天达到流量高峰时,HBase 团队被一个产品团队呼唤,他们遇到了超时的问题,导致客户出现 500 毫秒的情况。此时,HBase 团队有两个选择:
启动压实,这将进一步增加延迟,并需要 8 个小时以上的时间来解决这个问题。
试试新部署的 LocalityHealer,它还没有作为一个守护进程运行。
他们选择了后者,这使得整个集群的 Locality 在 3 分钟内达到 100%。放大来看,你可以看到下面的影响。
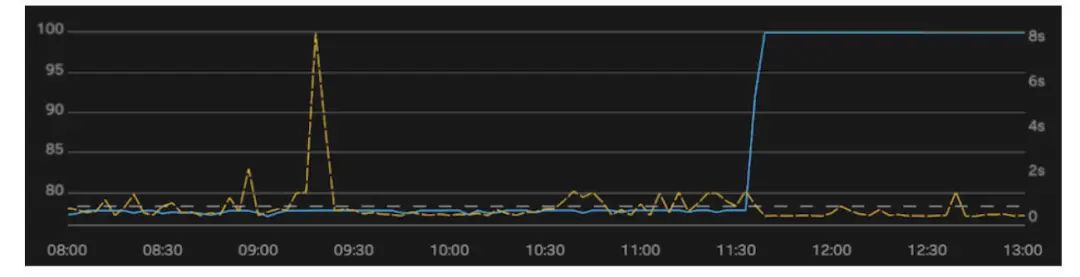
在本例下,我通过绘制单个平均位置(左轴,蓝线)来总结第一个图表。我把集群的第 99 个百分点的延迟叠加在一起(右轴,黄线)。在整个上午,我们看到了越来越多的超时(500 毫秒,用灰色虚线表示)。我们知道,当我们达到流量高峰时,这将变得非常关键,所以在 11:30 运行了 LocalityHealer。Locality 跃升至 100% 后,立即减少了延迟波动和超时的情况。
LocalityHealer 改变了 HubSpot 在管理快速增长的集群的关键性能指标方面的游戏规则。我们目前正在努力将这项工作贡献给开源社区,在 HBASE-26250 这个总的问题下。
这就是我们的数据基础设施团队每天都在处理的工作。
作者介绍:
Bryan Beaudreault,HubSpot 首席工程师。曾在 HubSpot 领导过多个团队,包括创建数据基础设施团队,并带领 HubSpot 在高度多租户的云环境下,在多个数据存储中实现了 99.99% 的正常运行时间。后来回到产品方面,致力于为 HubSpot 即将推出的一款产品实现对话自动化。
![]()