


AI行业又一次走到了十字路口。高昂的算力成本,利如纸薄的定制化商业模式,让AI公司集体深陷「负利润」的窘境。
企业往往寄希望于AI的能力,实现数字化跃迁,但作为新一代基础设施,AI行业本身也遭遇了新的难题:算法从研发到落地部署都需要巨额成本的投入,且大量的算法在应用落地上并不顺利。
如果从源头来看,云计算或许就是一剂良药,因为它能提供更低成本的算力和低门槛的开发服务,算法研发能力不足的企业还能直接在云上调用云厂商提供的算法,无需重复造轮子。
作为知名的市场分析机构,Gartner早早嗅到了这一趋势,他们从2020年就开始发布《云AI开发者服务关键能力报告》,在Gartner看来,AI与云的结合将愈加密切,AI云服务的能力也将成为AI产业的重要指标。
令人欣慰的是,中国企业已经压中了这一趋势,在今年的报告里,阿里语言AI技术高居全球第二,超越亚马逊AWS、微软等企业,正式进入世界第一梯队。

也正因如此,AI行业的前景依旧被广泛看好。Gartner报告提到,到2025年,70%的新应用程序将集成AI模型,而云AI服务能降低AI应用的开发门槛。这意味着云计算将成为阵痛期AI的最大变量。
给AI兜底的,为什么会是云?
AI商业化面前的两座大山:算力成本、项目成本
早在2017年,学术界和工业界在最具影响力的AI顶会CVPR上就对深度学习的问题展开了激烈的讨论。
讨论的焦点在于,深度学习的“大数据+大算力”范式需要巨大的成本支撑,这必然成为AI商业化的最大阻力。
“深度学习确实在语音、图像识别等数据中,比传统的AI方法更精准,这也是它成为引领第三波AI浪潮的关键,只不过深度学习是把双刃剑,它对燃料(算力、数据、能耗)的消耗,尤其是对算力的需求,远超传统方法。好比以前只吃两个馒头就能活下去,现在为了活得更好,却又受到食材的限制,只能选择天天吃昂贵的和牛。虽然更有营养,但这显然不可持续。”多位AI专家告诉雷峰网。
由于AI的计算成本和能耗成本一直居高不下,在不少注重效益的研究者眼里,AI深度学习一度成了野蛮和暴力的代名词。
2012年,谷歌利用16000块芯片,让AI观看数百万段YouTube视频来识别出猫,即便如此仍错误百出,还不如人类眼睛的一瞥高效。
2016年,AlphaGo击败围棋冠军李世石的人机大战中,AlphaGo每局棋需消耗约100万瓦的电能。相比之下,人脑消耗的功率仅20瓦,只有AlphaGo的5万分之一。
2018年之后,Transformer以及Bert等催生了预训练大模型的诞生,虽然让AI的性能变得更强,但所需的算力也大幅攀升。专门搭建一个这样的集群,对于大部分中小企业来说是难以承受的。
「算力」的供不应求,让其成为整个AI领域的稀缺资源。这也是不少学术界AI大牛纷纷涌入谷歌、微软、阿里等大型科技企业的主要原因,这类企业拥有丰富的业务场景,且有近乎取之不尽的算力资源。
AI所面临的问题还不仅于此,在商业落地过程中:企业不得不为每一个场景定制专属解决方案,这无形中增加了企业的开发成本,利润也因此被压缩。
早期的创业公司都迷信于“研发SDK,先标准化,再规模化,薄利多销,以量取胜”的商业设想。但现实很骨感,当AI公司们拿着SDK冲进行业里才发现,习惯了重型定制化贴身服务的B端客户们,需要的不是单个的开发包,也不具备集成SDK的能力,他们需要的是一套定制化的解决方案。一套SDK包打天下的梦想就此破灭。
SDK走天下梦碎后,AI公司们开始从轻变重,走高度定制化解决方案的路子。但充满个性化定制的项目制模式,极易让企业滑进亏损的漩涡获客周期长、实施成本高、重人力交付……成本的高企导致利润微薄,甚至一不小心做得越多,亏得越多。
标准化美梦易碎,定制化困局难解,AI企业在商业落地上左右为难。
事实证明,由算力成本和项目成本制造的两条后腿,正在让AI步履蹒跚。
而要卸下这两条后腿,就要打破固有思路,走上一条新的道路。专家们向雷峰网分析道,顶尖高校和头部科技公司现在的探索方向就是:从基础理论层面,用创新算法让AI本身变得更精益、更聪明;在工程层面,则需要让AI研发的成本变得更低。
云计算,为什么是解开“AI成本困局”的良药
毫无疑问,AI的成本问题,算力是最大的症结之一,也是破局的最大突破口。
通过算力集群的规模化,降低单位算力成本,是一条清晰的、具有一定可行性的道路。
在早期,AI所需算力并不高,CPU足以应对。但随着深度学习时代的到来,高质量的AI算法背后往往有惊人的数据量,此时训练所需的数据,规模已远超当年,更“强悍”的GPU逐渐登上历史舞台,成为AI算力的主流。
而当深度学习逐渐加深,模型的规模越来越大,单个GPU已无法满足算力。这时候,GPU并行的算力集群就显得尤为重要。大规模的算力集群,不仅能有效降低GPU采购成本,还能通过集群优势提升计算性能。
但此时新的问题又浮现了:有资源≠天然就用得好资源。如果企业没有合理高效的资源管理,GPU并行的算力集群自身属性再强,也无法自动锻造出优质AI大模型,更无从承载一个体验尚佳的AI应用。企业如今所面对的AI算力困境,包含着众多琐碎痛点:
如果没有算力线性扩展能力,100台机器可能还比不上1台机器的性能,大量的时间就会消耗在非计算开销里。
如果没有提升资源利用率的能力,昂贵的GPU集群很容易利用率不足10%。
业务发展速度难以预测,项目来了需要快速投入,等线下购买到资源,很容易错过机会窗口。
GPU卡故障率高,企业要腾出手来处理IaaS运维等苦活、累活。
GPU几乎半年更新一代,如果随时更换成最新型号,成本居高不下,旧卡又会被闲置。
此时,云上开发AI这一方案被摆上桌面,云计算本身具有的弹性、共享性和互通性等特性正与这些痛点匹配。企业可以借助云计算随时随地按需灵活扩缩容,进而提升算力效率、降低AI研发成本,基础设施层的运维等问题也可以交由更专业的云厂商处理。
这让企业在AI领域模型越演进越复杂,算力需求越来越强的大背景下,可以扬长避短,充分利用市场上已有的技术红利去自我赋能,提升自身业务迭代效率。
以阿里云为代表的国内互联网云厂商,早已提前布局,并将这一系列技术对外服务。

阿里云张北数据中心,可容纳百万台服务器
值得一提的是,不同于AI独角兽们专注to B、to G,这批提供云AI服务的互联网云巨头,自身往往拥有海量的场景业务,可以使算力集群得到高饱和使用,分摊GPU的折旧成本,从而避免GPU集群算力闲置的问题。
这一做法,与谷歌的案例有异曲同工之妙。谷歌前CEO施密特曾谈到,谷歌搜索之所以能在竞争中占有优势,关键因素之一在于成本低。
“Google的运营成本只有微软和雅虎的几分之一,一次搜索服务的成本只有零点几美分。节省下来的钱,Google可以购买更多的服务器、提升运算性能,如此一来,在与竞争对手相同的单位价格下,Google可用更多的硬件和算法,实现更好的搜索质量。”
真正一流的技术和科技公司,最先应该做的事是利用技术实现自身的降本增效,只有把生产要素的成本降下来,才能做到真正意义上的进入行业。
这种通过降低自身生产成本,提升计算资源的利用效率,把边际效应最大化,用最低的成本,走向规模化应用,这是科技产业落地发展的最佳路径。
除了算力问题,云AI服务也可以有效降低AI应用的开发门槛。以阿里为例,其机器学习平台PAI、达摩院研发的基础算法模型以及各种训练的加速框架等,从低门槛、全链路角度出发,高效满足了AI算法的开发需求。
云厂商扛起AI产业化重担
跳出技术层面,在商业层面,云计算也在帮助AI产业加速破局。
目前国内AI产业主要有三条演进路径,从项目制出发:一条是最难获取高利润的多行业拓展模式,为了快速铺大摊子、做大规模,或者寻求业务突破而进入到金融、医疗、零售等数个领域,多线作战;一条是专注于一个垂直行业,把方案和服务做深做透,进而寻求在某一领域里实现平台化;还有一条是先聚焦于算法的打磨,做好算法的产品化,再依托云平台将算法对外服务,并用云平台的基础设施能力帮助企业研发算法。
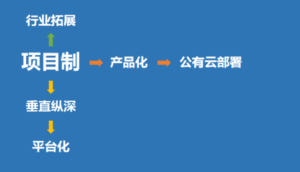
国内AI产业演进的三条路径
而以阿里云为代表的头部互联网云厂商,在AI领域正朝着最良性的第三条道路迈进。
这种模式的好处在于,基于云平台的底座,不仅可以免去大部分本地化部署的枷锁,还能提供低成本的自研算法研发,快速为算法研发能力弱的企业服务,例如达摩院研发的视觉、语音、NLP等算法就在阿里云上对外服务。同时,云上的计算、存储、网络、机器学习平台等还能为具备算法研发能力的企业提供AI研发和落地的全链路支持。
这条将云与AI完美结合的路径,已经初有成效。以毫末智行为例,这家公司将算法训练任务放到阿里云上,利用后者的对象存储OSS和小文件存储CPFS,可实现海量数据冷热分层存储和高效的数据流通,基于弹性GPU实例在机器学习平台PAI上进行云上分布式模型训练,吞吐性能提升110%,模型成熟度在短时间内大幅提高。据介绍,这样的训练效率最高可提升70%,整体成本降低约20%。
过去十几年里,云计算凭借在算力成本和商业上的双重优势,以DNA复制般的速度进入到各行各业,如今,其在通用计算领域中已被验证过的价值正在被复制到AI领域,助力AI冲破落地瓶颈,实现万千普惠。
Gartner也毫不掩饰对这一趋势的预判,其最新的AI云服务报告指出,到2025年,人工智能软件市场规模将达到1348亿美元,而云AI服务是其中不可或缺的核心推力之一。
事实上,回顾半个多世纪里人工智能产业一路走来的潮起潮落,每一次低谷崛起都伴随着某一新变量带来的突破。如今,云计算正在成为眼下被寄予厚望的最大变量,这一次,将AI产业推向正轨的责任被使命般地交到了云厂商的肩上。
![]()