


在最近的研究中,视觉-语言-动作(VLA,vision-language-action)模型的输入基本都是2D数据,没有集成更通用的3D物理世界。
此外,现有的模型通过学习「感知到动作的直接映射」来进行动作预测,忽略了世界的动态性,以及动作和动态之间的关系。
相比之下,人类在思考时会引入世界模型,可以描绘除对未来情景的想象,从而对下一步的行动进行规划。
为此,来自马萨诸塞州大学阿默斯特分校、MIT等机构的研究人员提出了3D-VLA模型,通过引入一类全新的具身基础模型(embodied foundation models),可以根据生成的世界模型无缝连接3D感知、推理和行动。

项目主页:https://vis-www.cs.umass.edu/3dvla/
论文地址:https://arxiv.org/abs/2403.09631
具体而言,3D-VLA构建在基于3D的大型语言模型(LLM)之上,并引入一组交互token来参与具身环境中。
为了将生成能力注入模型,淦创团队训练了一系列具身扩散模型,并将其对齐到LLM中以预测目标图像和点云。
为了对3D-VLA模型进行训练,通过从现有的机器人数据集中提取大量的3D相关信息来构建出一个大规模的3D具身指令数据集。
实验结果表明,3D-VLA显着提高了在具身环境中推理、多模态生成和规划的能力,展示出其在现实世界中的应用潜力。
三维具身指令调整数据集(3D Embodied Instruction Tuning Dataset)
得益于互联网上数十亿规模的数据集,VLM在各种任务中表现出了非凡的性能,百万级的视频动作数据集也为机器人控制的具身VLM奠定了基础。
但当前的数据集大多不能在机器人操作中提供深度或3D标注和精确控制,需要包含3D空间推理和交互:如果没有3D信息,机器人很难理解和执行需要3D空间推理的命令,比如「把最远的杯子放在中间的抽屉里」。

为了弥补这一差距,研究人员构建了一个大规模的3D指令调优数据集,该数据集提供了足够的「3D相关信息」以及「相应的文本指令」以训练模型。
研究人员设计了一个pipeline从现有的具身数据集中提取3D语言动作对,获得点云、深度图、3D边界框、机器人的7D动作和文本描述的标注。
3D-VLA基础模型
3D-VLA是一个用于在具身环境(embodied environment)中进行三维推理、目标生成和决策的世界模型。
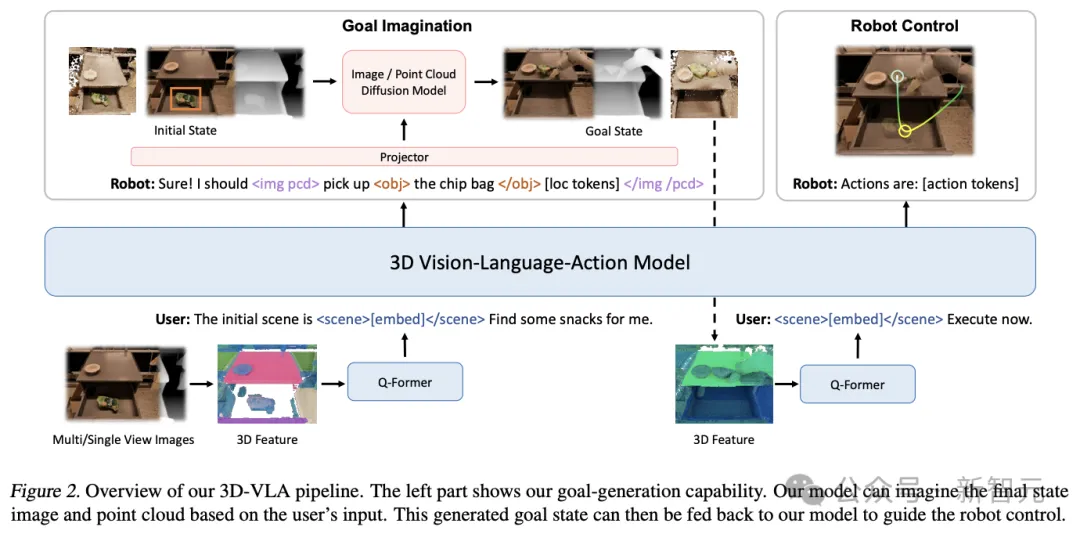
首先在3D-LLM之上构建主干网络,并通过添加一系列交互token来进一步增强模型与3D世界交互的能力;再通过预训练扩散模型并使用投影来对齐LLM和扩散模型,将目标生成能力注入3D-VLA
骨干网络
在第一阶段,研究人员按照3D-LLM的方法开发3D-VLA基础模型:由于收集到的数据集没有达到从头开始训练多模态LLM所需的十亿级规模,因此需要利用多视图特征生成3D场景特征,使得视觉特征能够无缝集成到预训练VLM中,不需要自适应。
同时,3D-LLM的训练数据集主要包括对象(objects)和室内场景,与具体设置不直接一致,所以研究人员选择使用BLIP2-PlanT5XL作为预训练模型。
在训练过程中,解冻token的输入和输出嵌入,以及Q-Former的权重。
交互tokens
为了增强模型对3D场景的理解与环境中的交互,研究人员引入了一组全新的交互tokens
首先,输入中加入了object tokens,包含解析句子中的对象名词(如<obj> a chocolate bar </obj> [loc tokens] on the table),这样模型就能更好地捕捉到被操作或提及的对象。
其次,为了更好地用语言表达空间信息,研究人员设计了一组位置token <loc0-255>,用 AABB 形式的六个标记来表示三维边界框。
第三,为了更好地进行动态编码,框架中引入了<scene></scene>来包含静态场景的嵌入:通过对场景token进行组合,3D-VLA 可以理解动态场景,并管理交错三维场景和文本的输入。
通过扩展代表机器人动作的专用标记集,进一步增强了该架构。机器人的动作有 7 个自由度,用 <aloc0-255>、<arot0-255> 和 <gripper0/1> 等离散token来表示手臂的预定绝对位置、旋转和抓手张开度,每个action由 <ACT SEP> token进行分隔。
注入目标生成能力
人类能够对场景的最终状态进行预先可视化(pre-visualize),以提升动作预测或决策的准确性,也是构建世界模型的关键方面;在初步实验中,研究人员还发现提供真实的最终状态可以增强模型的推理和规划能力。
但训练MLLM来生成图像、深度和点云并不简单:
首先,视频扩散模型并不是为具身场景量身定制的,比如Runway在生成「打开抽屉」的未来帧时,场景中会发生视图变化、对象变形、怪异的纹理替换以及布局失真等问题。
并且,如何将各种模态的扩散模型整合到一个单一的基础模型中仍然是一个难题。
所以研究人员提出的新框架,首先根据图像、深度和点云等不同形式对具体的扩散模型进行预训练,然后在对齐阶段将扩散模型的解码器对齐到3D-VLA的嵌入空间。

实验结果
3D-VLA是一个多功能的、基于3D的生成式世界模型,可以在3D世界中执行推理和定位、想象多模态目标内容,并为机器人操作生成动作,研究人员主要从三个方面对3D-VLA进行了评估:3D推理和定位、多模态目标生成和具身行动规划。
3D推理和定位
3D-VLA在语言推理任务上优于所有2D VLM方法,研究人员将其归因于3D信息的杠杆作用,3D信息为推理提供了更准确的空间信息。
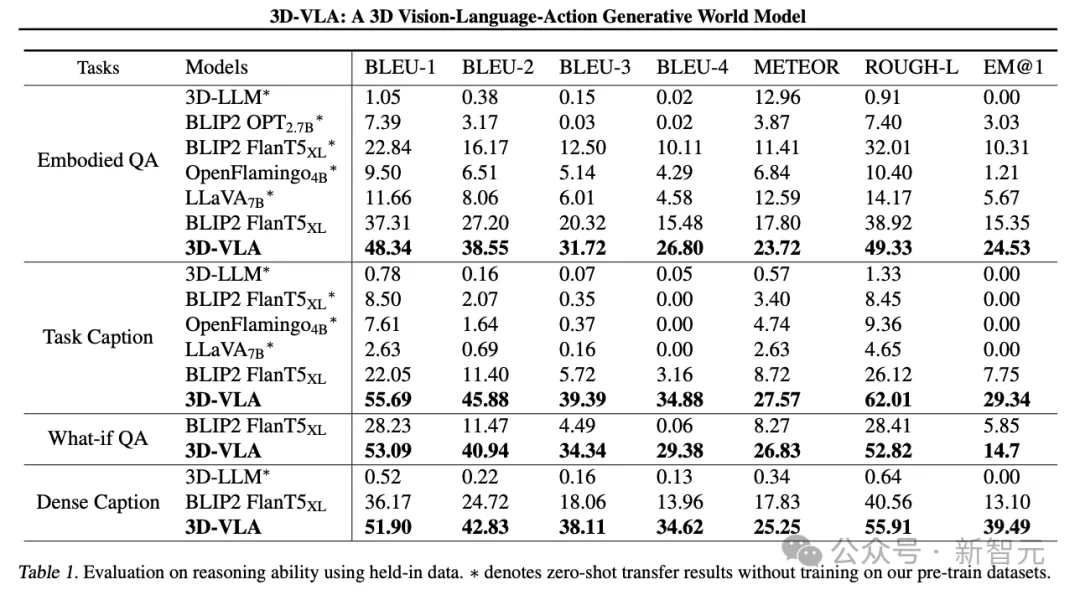
此外,由于数据集中包含一组3D定位标注,3D-VLA学习定位相关对象,有助于模型更专注于关键对象进行推理。
研究人员发现3D-LLM在这些机器人推理任务中表现不佳,证明了在机器人相关的3D数据集上收集和训练的必要性。

并且3D-VLA在定位性能方面表现出明显优于2D基线方法,这一发现也为标注过程的有效性提供了令人信服的证据,有助于模型获得强大的3D定位能力。
多模态目标生成
与现有的零样本迁移到机器人领域的生成方法相比,3D-VLA在大多数指标方面实现了更好的性能,证实了使用「专门为机器人应用设计的数据集」来训练世界模型的重要性。
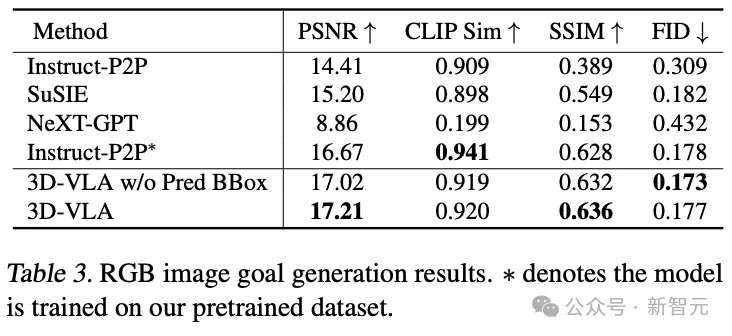
即使在与Instruct-P2P*的直接比较中,3D-VLA也始终性能更优,结果表明,将大型语言模型集成到3D-VLA中可以更全面、更深刻地理解机器人操作指令,从而提高目标图像生成性能。
此外,当从输入提示符中排除预测的边界框时,可以观察到性能略有下降,证实了使用中间预测边界框的有效性,可以帮助模型理解整个场景,允许模型将更多的注意力分配到给定指令中提到的特定对象,最终增强其想象最终目标图像的能力。
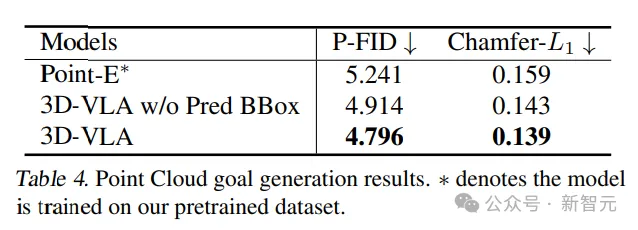
点云生成的结果对比中,具有中间预测边界框的3D-VLA性能最好,证实了在理解指令和场景的背景下结合大型语言模型和精确对象定位的重要性。
具身行动规划
3D-VLA在RLBench动作预测中的大多数任务中超过了基线模型的性能,显示了其具有规划能力。
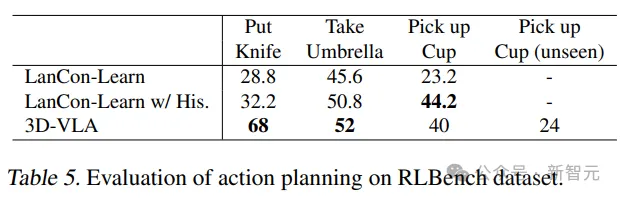
值得注意的是,基线模型需要用到历史观察、对象状态和当前状态信息,而3D-VLA模型只通过开环控制执行。
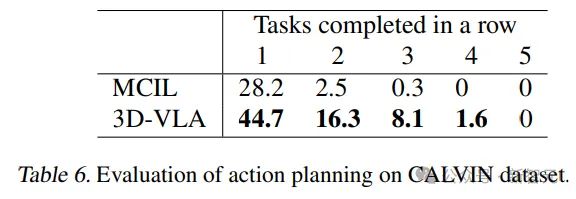
此外,模型的泛化能力在捡杯(pick-up-cup)任务中得到了证明,3D-VLA在CALVIN中也取得了较好的结果,研究人员将这种优势归因于定位感兴趣的对象和想象目标状态的能力,为推断动作提供了丰富的信息。
文章来自:51CTO