
北京时间6月25日凌晨,多个地区的OpenAI用户收到了一封来自官方的邮件。邮件显示:“您所使用的APl流量来自OpenAl目前不支持的地区。我们将从7月9日开始采取额外措施,阻止来自不在我们支持的国家和地区列表中的地区的APl接口。”
所谓的API,就是应用程序编程接口。开发者通过使用OpenAI的API,就能极大地简化应用开发,将OpenAI的模型直接嵌入公司的工具和产品中。
此前,国内用户使用OpenAI 的API服务基本要通过两种渠道:一种是通过代理的方式直接从OpenAI官方获取API,限制较小;另一类则是通过微软Azure来获取,但对企业资质有一定的要求。因此,国内很多的AI开发企业大多直接使用前者。而对于中国的用户来说来说,微软端的接口尚未受到影响,官方端的接口受到的影响较大。
OpenAI此番对包括中国在内的多个国家“断供”,原因何在?”断供”对中国的AI企业们有带来了怎样的影响?未来的AI是否会因此而产生分歧,走上不同的道路?
OpenAI不再Open,有意为之还是无奈之举?
事实上,出于商业角度考虑,OpenAI一直是闭源派AI,GPT-3.5、GPT-4模型的源码均没有向外公开。并且一直以来,OpenAI在ChatGPT注册和使用方面均有严格的制度,直到后来Claude等其他模型的崛起,才迫使openAI放宽了在注册方面的要求。
而针对此次断供,公司既有监管与合规角度的考量,也有竞争层面的担忧。一方面,美国财政部于6月22日发布的一份规则草案中,要求对美国在关键技术领域的投资进行监管,包括半导体、量子计算和人工智能等。因此,在美国加强对华技术投资监管的大背景下,OpenAI作为美国企业,必须遵守相关法规。
此外,新加入的董事会成员——退役美国陆军将军Paul M. Nakasone(保罗·中曾根)的网络安全背景,也可能对OpenAI的决策产生了影响,其作为网络安全领域的专家,可能推动了OpenAI在合规和数据安全方面的更严格要求。
另一方面,OpenAI对中国API的停用,折射出了美国的大模型公司们对中国AI的担忧。
从消息面来看,5月29日斯坦福大学AI团队发布了一个名为Llama3-V的多模态大模型,声称只需500美元就能训练出一个性能可与GPT4-V媲美的模型。该模型不仅在社交媒体上迅速蹿红,还一度冲上了HuggingFace(全球模型排行榜)首页。
然而,随后该模型就被证实是套壳抄袭国内清华与面壁智能共同开发的开源模型“小钢炮”MiniCPM-Llama3-V 2.5。紧接着就是该斯坦福队的两位作者在社交平台上向面壁MiniCPM团队正式道歉,并撤下模型。
早期,往往是国内的AI公司套Chatgpt的壳在国内圈钱,而现在却倒反天罡,美国的研究团队“反向套壳”中国的AI。从微观层面来看,这是部分美国AI研究者们的学术不端,然而背后却反映出一个事实:但中美之间的AI差距在逐渐缩短。
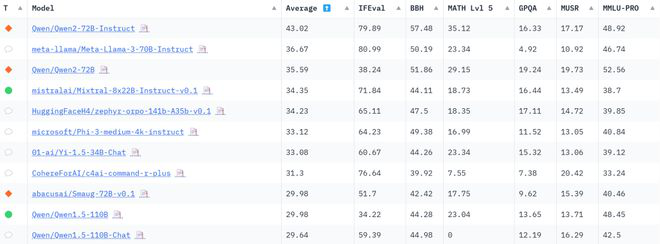
从 6月28日公布的Hugging Face 大模型排行榜单来看,阿里最新开源的 Qwen2-72B模型力压科技巨头 Meta的Llama-3模型和法国著名大模型平台 Mistralai 的Mixtral模型,成为新版开源模型排行榜第一名。同时,零一万物的Yi-1.5-34B-Chat模型处在第 7 名,Qwen1.5-110B 和 Qwen1.5-110B-Chat 分别位于榜单第10 名和第11 名——正如 Hugging Face 联合创始人兼首席执行官 Clem 所说:“中国的开源模型在整体上占主导地位。
此外,2023年公布的《北京市人工智能行业大模型创新应用白皮书》中也提到,尽管在高端芯片、基础软件等领域还存在落后,但中国的AI占据海量数据资源和应用场景优势,在产业布局方面已经展现除了更强的统筹规划能力。
由此看来,OpenAI此次断供,本质上是因为中美的AI差距的缩小让OpenAI感受到了“危机”的存在,于是便打着“合规”的幌子对中国的AI企业进行限制。毕竟大模型爆火的那段时间,中国涌现出了许多
降价打折+帮助迁移,国产大模型能否接住“泼天的富贵”?
然而,对于真正自研的国产大模型来说,OpenAI禁用国内接口,就意味着市场上会空出一部分的顾客需求,这次的封禁反倒成了机会。
市场层面,AI概念股6月26日全面反弹,文生视频概念股、多模态AI、AIGC概念、算力租赁等领涨。
消息层面,国内的大模型公司们打出了“降价+搬家”的组合拳,想要接下这波送上门的订单:
6月25日,北京智谱华章科技公司便正式推出“OpenAI API用户特别搬家计划”,向开发者提供OpenAI迁移培训及专属搬家顾问,并为开发者提供1.5亿Token。
随后,阿里云官方表示,面对OpenAI断供国内API用户,通义千问已经做好承接准备。阿里将提供“阿里云百炼专属迁移服务”。
百度智能云千帆则推出“故乡的云·国产大模型普惠计划”,提供零成本SDK迁移工具和迁移专家服务,帮助国内API用户零成本切换大模型平台。
腾讯云也发布大模型迁移企业用户专属福利,截止7月31日24点前,新迁移企业用户可免费获得腾讯混元大模型1亿Tokens。腾讯云提供混元Pro、Standard等模型,用户可以任意选择。
针对此次断供带来的影响,在浙江大学计算机系统结构实验室研究员陈天楚认为,现有头部应用多是基于自研模型或国产模型开发,OpenAI的API服务不可用,对应用开发造成的影响并不算大,目前接入国内头部模型的API,在中文日常任务上的服务都不差。
因此,对于国内那些自主研发底层模型的公司来说,OpenAI的封杀令,可以说是一份“大礼”。毕竟多数开发者的AI需求用国产AI模型也同样可以满足,并且国产AI往往更贴近中文的应用环境,在文言文和方言等特定领域的表现优于chatgpt。
AI下半场,中国AI将走向何处?
事实上,中国被限制的远不止大模型接口。从早期对半导体、光刻机等底层硬件的限制,再到如今对应用端软件的禁用,美国对中国的AI发展一直怀有敌意。
AI作为下一个20年全球化竞争的核心赛道之一,也是中美科创竞争的关键核心战场之一。在过去的科技领域,美国长期处于优势地位,也让美国在上一轮的竞争中有了躺着赚钱的实力。作为下一个20年国际化竞争的核心赛道,AI代表的不仅是下一代的效率革命,也是国家实力的体现,中国AI产业的强势崛起,无疑让美国感受到了威胁。
从这个角度来看,OpenAI封禁中国的API,就是希望借此阻碍中国AI产业的发展,防止中国成为全球AI产业的领跑者,从而维护自身的技术优势,去抢占下半场竞争的主导权。
然而,中国的发展是并不以其他国家的意志为转移。
目前,中国AI产业的发展优势与全面深层次的布局已经形成了体系化系统化的领先。数据显示,截至2019年我国人工智能专利申请数量超过11万项,超过美国的8万项,稳居世界第一。2018年到2021年,全球共新增申请了65万件人工智能相关专利,中国美国和日本申请量位列前三,而其中中国有44.5万件,占比68.5%。
专利数量的丰富度背后则是中国市场应用场景的丰富度。无论是在布局广度还是深度方面,均已形成了明显的竞争优势。同时中国AI行业普遍有着明显的原创性,占据着大部分创新应用的主导权,叠加场景应用的加速落地,后续发展势头依然强劲。
以大模型为例,2023年,如火如荼的“百模大战”推动了国产大模型的技术进步。2024年,“百模大战”走向结束,头部大模型初创六强浮出水面(智谱AI、MiniMax、月之暗面、百川智能、零一万物、面壁智能),与百度文心、阿里通义、讯飞星火、字节豆包、腾讯混元、华为盘古、昆仑万维天工AI等巨头大模型构成第一阵营“十三太保”,宣告着大模型的基础阶段竞争已告一段落,接下来将大模型进入“落地赛阶段”。
如今,不论是AI大厂还是初创公司的大模型都将重点放在了“落地”上。不同基础大模型、垂直大模型正在差异化发展,在各自擅长的领域形成特长。如百川智能强调语言认知能力,以及医疗等场景优势;kimi长文本优势凸显;智谱AI除了技术强大外,对开发者门槛低强调普惠理念……
在这样的关键时刻,位于中间层的钉钉、字节扣子、阿里云等平台推出了“模型可选”模式,基于开放模式,让开发者可以选取最合适应用场景的大模型,并可无缝切换、快速迁移,类似于大模型的“分发入口”,这也意味着,用户的选择更多,基础大模型的竞争只会更加激烈。毕竟丰厚的迁移优惠固然能够吸引开发者,但是最终能否让开发者留下来并长期使用,还是取决于AI大模型的性能如何。
从6月24日极客公园大模型评测报告的数据来看,目前的AI模型在人文科目方面的表现不错,但在数学,物理等学科方面表现不佳,其中9款大模型产品中仅有GPT-4o、文心一言 4.0 和豆包在数学科目上获得了60分以上的成绩。

由此看来,国产大模型还需要在数理方面在算法优化、数据训练上持续发力,不断提升自身的能力,以更好地适应复杂多变的知识考查和应用场景。新一轮的竞争不再仅仅只是围绕着算力和价格,围绕垂直化领域应用的综合较量,只会更加激烈,更加精彩。
因此,对于大部分国产AI公司来说,OpenAI“断供”相当于主动让出市场,给中国AI提供了一个继续自主创新和研发的契机。
如何把握住这个契机,接住这波“泼天的富贵”,会是各大厂商接下去需要重点考虑的问题。
![]()