

想象一下,你身处一个陌生的小镇,即使一开始周围的环境并不熟悉,你也可以四处探索,并最终在大脑中绘制出一张环境地图,里面包含建筑物、街道、标志等相互之间的位置关系。这种在大脑中构建空间地图的能力是人类更高级认知类型的基础:例如,有理论认为,语言是由大脑中类似地图的结构编码的。
然而, 即使是最先进的人工智能和神经网络,也无法凭空构建这样的地图。
计算生物学助理教授、Heritage Medical 研究所研究员 Matt Thomson 说:「有一种感觉是,即使是最先进的人工智能模型,也不是真正的智能。它们不能像我们一样解决问题;不能证明未经证实的数学结果,也不能产生新的想法。」
「我们认为,这是因为它们无法在概念空间中导航;解决复杂问题就像在概念空间中移动,就像导航一样。人工智能做的更像是死记硬背 —— 你给它一个输入,它给你一个回应。但它无法综合不同的想法。」
最近,Thomson 实验室的一篇新论文发现,神经网络可以使用一种叫做「预测编码」的算法来构建空间地图 。该论文于 7 月 18 日发表在《自然 – 机器智能》(Nature Machine Intelligence)杂志上。

- 论文地址:https://www.nature.com/articles/s42256-024-00863-1
- 代码地址:https://github.com/jgornet/predictive-coding-recovers-maps
在研究生 James Gornet 的带领下,两人在游戏《我的世界》(Minecraft)中构建了环境,将树木、河流和洞穴等复杂元素融入其中。他们录制了玩家随机穿越该区域的视频,并利用视频训练了一个配备预测编码算法的神经网络。
他们发现,神经网络能够学习 Minecraft 世界中的物体彼此之间是如何组织的,并且能够「预测」在空间中移动时会遇到的环境。

预测编码算法与 Minecraft 游戏的结合成功地「教会」了神经网络如何创建空间地图,并随后使用这些空间地图来预测视频的后续帧,结果预测图像与最终图像之间的均方误差仅为 0.094%。
更重要的是,研究小组「打开」了神经网络(相当于检查内部结构),发现各种物体的表征是相对于彼此进行空间存储的。换句话说,他们看到了存储在神经网络中的 Minecraft 环境地图。
神经网络可以导航人类设计者提供给它们的地图,例如使用 GPS 的自动驾驶汽车,但这是人类首次证明神经网络可以创建自己的地图。这种在空间上存储和组织信息的能力最终将帮助神经网络变得更加「聪明」,使它们能够像人类一样解决真正复杂的问题。
这个项目展示了人工智能真正的空间感知能力,而这在 OpenAI 的 Sora 等技术中仍然看不到,后者存在一些奇怪的故障。
James Gornet 是加州理工学院计算与神经系统(CNS)系的学生,该系涵盖神经科学、机器学习、数学、统计学和生物学。
「CNS 项目确实为 James 提供了一个地方,让他从事其他地方不可能完成的独特工作,」Thomson 说。「我们正在采用一种生物启发的机器学习方法,让我们能够在人工神经网络中反向设计大脑的特性,我们希望反过来了解大脑。在加州理工学院,我们有一个非常容易接受这类工作的社区。」
执行预测编码的神经网络
受预测编码推理问题中隐式空间表示的启发,研究者开发了一个预测编码智能体的计算实现,并研究了该智能体在探索虚拟环境时学习到的空间表示。
他们首先使用 Minecraft 中的 Malmo 环境创建了一个环境。物理环境的尺寸为 40 × 65 格单位,囊括了视觉场景的三个方面:一个山洞提供了一个全局视觉地标,一片森林使得视觉场景之间具有相似性,而一条带有桥梁的河流则限制了智能体如何穿越环境(图 1a)。
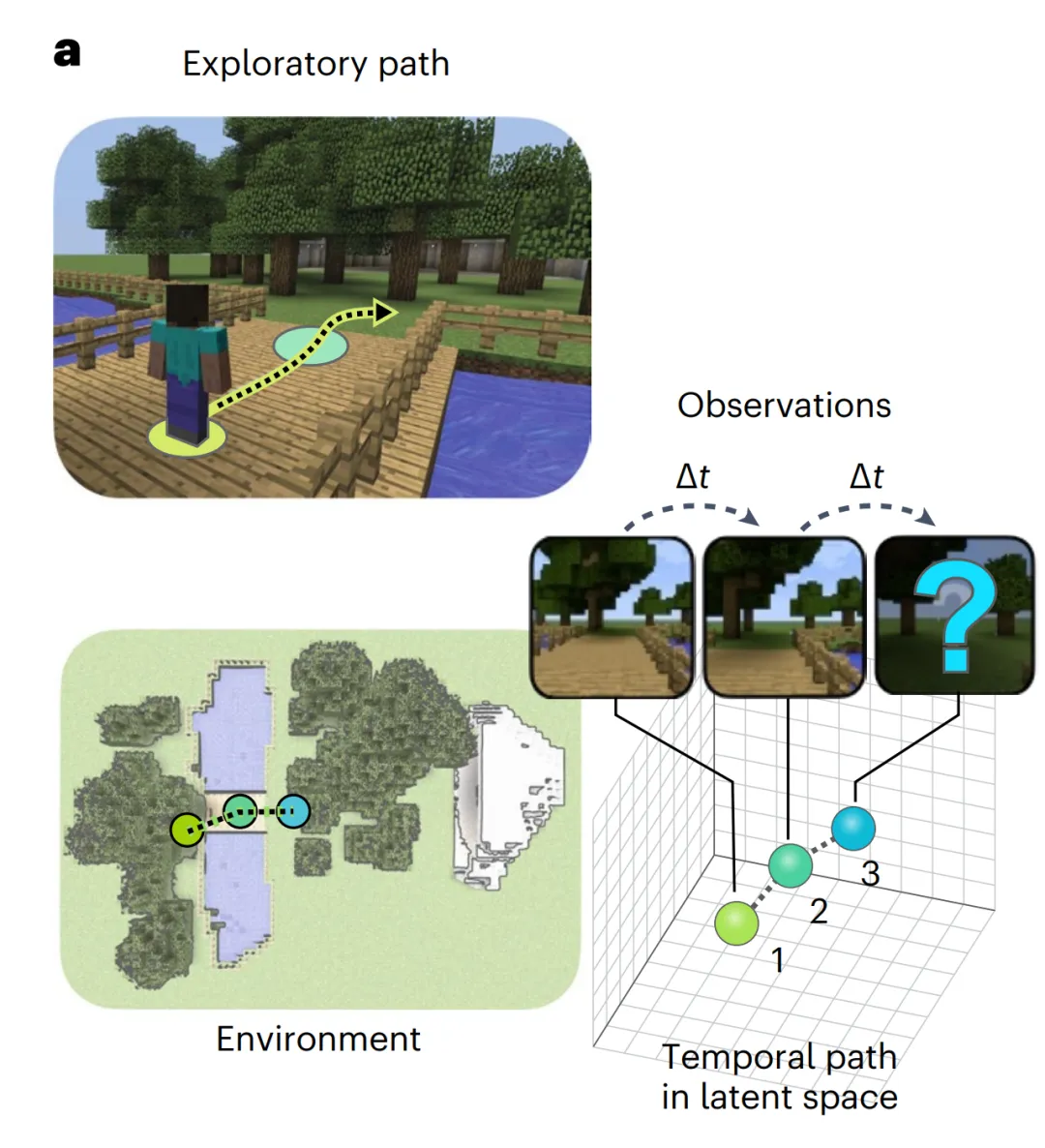
智能体遵循路径,路径由 A* 搜索确定,以找到随机取样位置之间的最短路径,并接收每条路径上的视觉图像。
为了进行预测编码,作者构建了一个编码器 – 解码器卷积神经网络,编码器采用 ResNet-18 架构,解码器采用转置卷积的 ResNet-18 架构(图 1b)。编码器 – 解码器架构使用 U-Net 架构将编码的潜在单元传递到解码器中。多头注意力处理编码潜在单元序列,以编码过去的视觉观察历史。多头注意力有 h = 8 个头。对于维度为 D = C × H × W 的编码潜在单元,在高度 H、宽度 W 和通道 C 的情况下,单个头部的维度为 d = C × H × W/h。
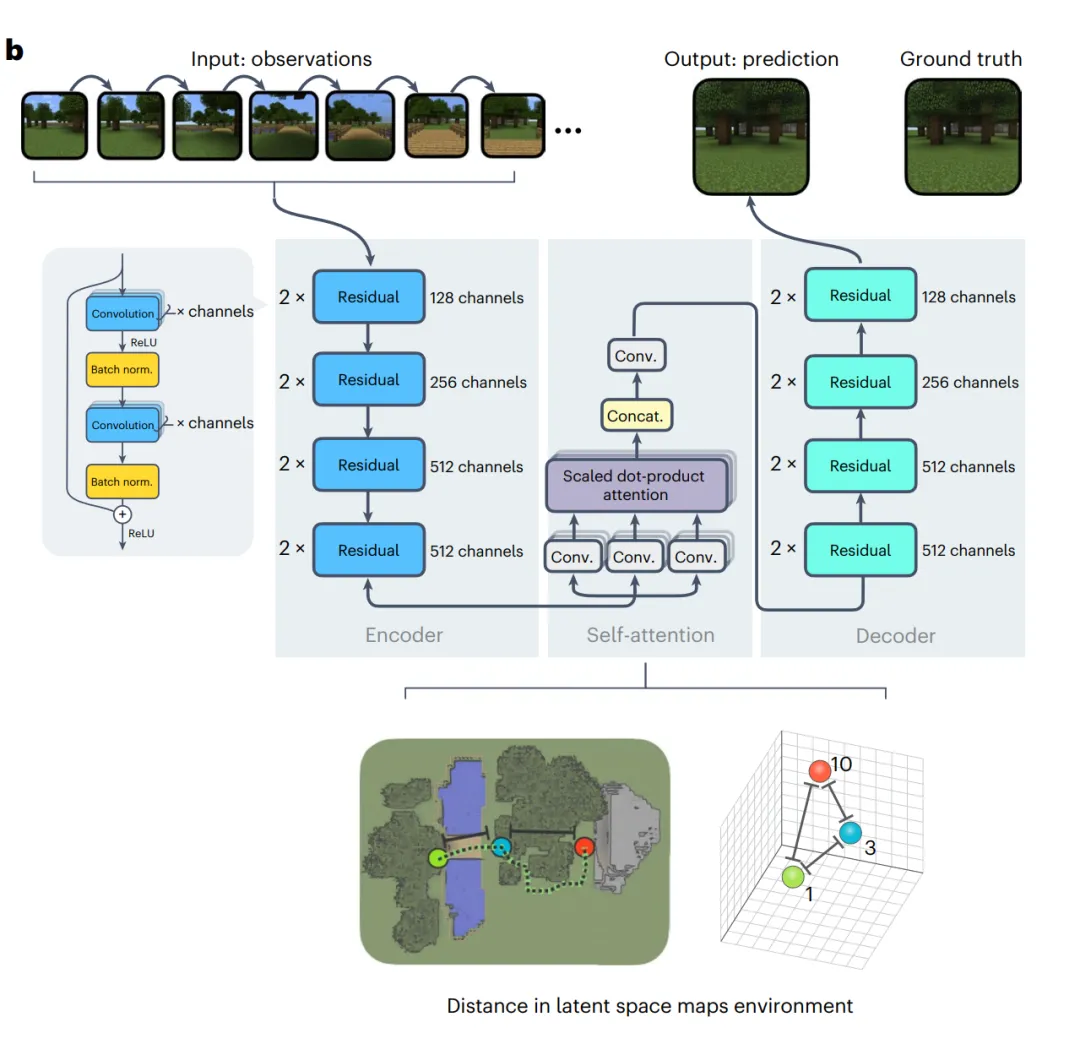
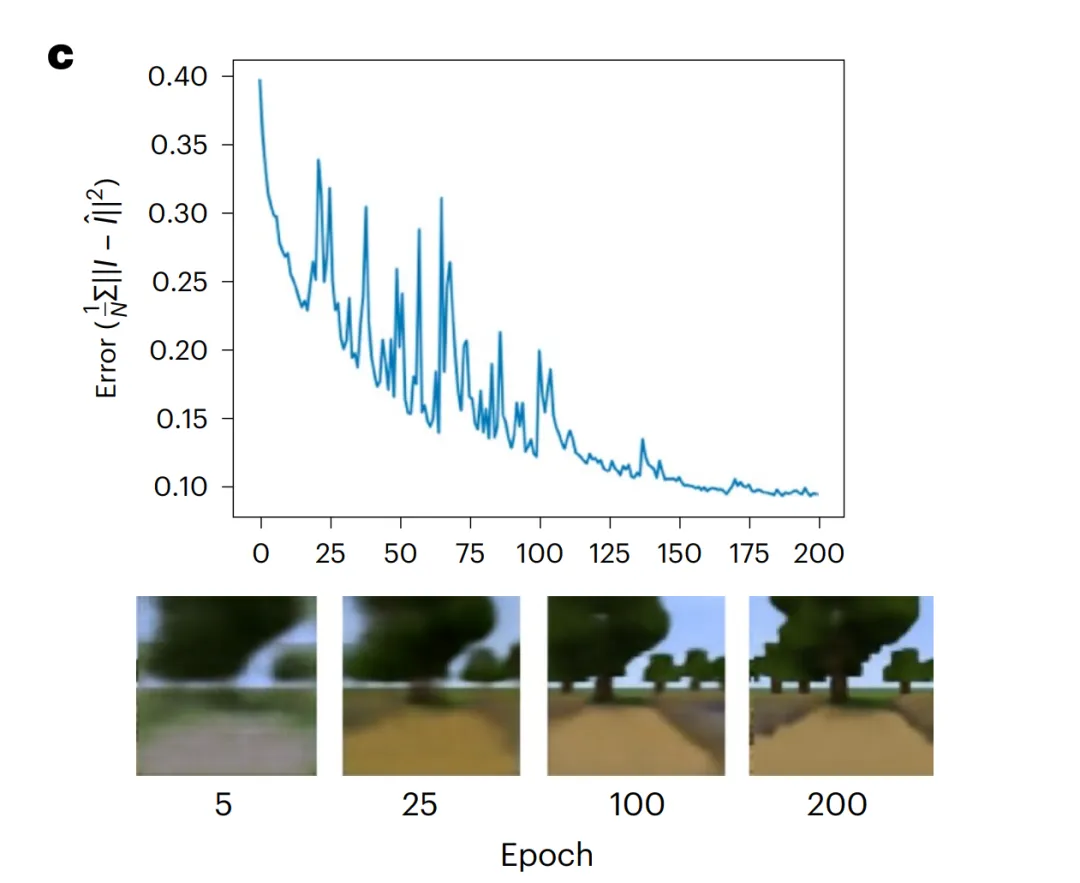
预测编码器通过最小化实际观测值与预测观测值之间的均方误差来近似预测编码。预测编码器在 82,630 个样本上进行了 200 个 epoch 训练,使用了具有 Nesterov 动量的梯度下降优化,权重衰减为 5 × 10^(-6),学习率为 10^(-1),并通过 OneCycle 学习率调度进行调整。优化后的预测编码器预测图像与实际图像之间的均方误差为 0.094,具有良好的视觉保真度(图 1c)。
更多细节请参见原论文。