

今天给大家分享神经网络中的一个关键概念,激活函数
激活函数是神经网络中的核心组件之一,其主要作用是在每个神经元中为输入信号提供非线性变换。如果没有激活函数,神经网络将充当简单的线性模型。
激活函数的作用
激活函数的引入使得神经网络可以学习和表示复杂的非线性关系,从而解决一些线性模型无法处理的问题。
 图片
图片
- 非线性化
神经网络的每一层通常是线性运算(如线性变换),如果不加入激活函数,整个网络将只是线性模型的堆叠,无论多少层都仍是线性的。
激活函数通过引入非线性因素,使网络能够逼近任意复杂的非线性函数。 - 控制神经元的激活
激活函数对输入信号进行处理后输出,控制着每个神经元的激活程度。
某些激活函数会将输出压缩到一定范围内,从而使网络的输出更加稳定。 - 梯度传递
在反向传播中,激活函数还会影响梯度的传递。
合适的激活函数能够使梯度在网络中有效传播,避免梯度消失或爆炸的问题(如 ReLU 激活函数在深度网络中有显著优势)。
常见的激活函数
下面,我们一起来看一下神经网络中常见的激活函数。
1.Sigmoid
Sigmoid 是一种 S 形曲线函数,将输入压缩到 (0,1) 之间,通常用于二分类问题。
 图片
图片

优点
- 将输入值映射到 (0, 1) 范围内,非常适合二分类问题中的概率输出。
缺点
- 容易出现梯度消失问题,在反向传播中,当输入较大或较小时,导数趋近于零,使得梯度传递较慢,导致深层网络的训练效率降低。
- 不以零为中心,导致梯度更新不平衡。
2.Tanh
Tanh 是 Sigmoid 的改进版本,输出范围在 (-1, 1),对称于零。
 图片
图片
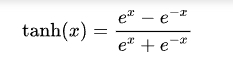
优点
- 输出范围在 (-1, 1) 之间,使得正负值更加均衡,适合用作隐藏层的激活函数。
- 零点对称,可以更好地解决梯度消失问题,收敛速度比 Sigmoid 更快。
缺点
- 在输入值较大或较小时,依然存在梯度消失的问题,导致深层网络的训练困难。
3.ReLU
ReLU 是最常用的激活函数之一,对正数直接输出,对负数输出零。
 图片
图片
优点
- 简单高效,且在正数区梯度始终为 1,能够缓解梯度消失问题。
- 计算速度快,常用于深层神经网络。
缺点
- 存在“死亡神经元”问题,输入为负时输出为零,可能导致某些神经元永远不被激活。
4.Leaky ReLU
Leaky ReLU 是 ReLU 的改进版,负数区域的输出为输入的一个小比例,以解决“死亡神经元”问题。
 图片
图片
其中 是一个很小的正数,通常取 0.01。
优点
- 保留负数区域的小梯度,减少神经元死亡的风险。
- 保持 ReLU 的大部分优势。
缺点
- 引入了一个额外的参数 ,需要手动设置。
5.PReLU
PReLU 是 Leaky ReLU 的变体,负区域的斜率参数 可以在训练中自动学习。
 图片
图片
优点
- 负区域的斜率参数 可学习,模型能够自动适应数据特性。
缺点
- 增加了模型复杂性和计算成本,因为需要学习额外的参数。
6.ELU
ELU 是 ReLU 的另一种改进版本,ELU 在正值区域与 ReLU 相同,但在负值区域应用指数函数进行变换。
 图片
图片

优点
- 在负区域输出接近零,有助于加快收敛。
- 可以减少梯度消失的现象。
缺点
- 计算开销较高,不如 ReLU 高效。
7.Swish
Swish 是一种平滑的激活函数,常常在深层网络中表现优于 ReLU 和 Sigmoid。
 图片
图片
![]()
其中 是 Sigmoid 函数。
优点
- 平滑且输出无界,有更好的梯度流动性质,性能上往往优于 ReLU。
- 在深层神经网络中表现良好,可以提高模型准确性。
缺点
- 计算量大于 ReLU,尤其在大规模神经网络中。
8.Softmax
Softmax 通常用于多分类任务的输出层,将输出值归一化到 [0, 1] 范围,总和为 1,可以理解为概率分布。
 图片
图片

优点
- 将输出值转换为概率,便于多分类任务。
- 可以通过最大值索引确定类别。
缺点
- 仅适合用于输出层,而不适合隐藏层。
- 对输入值的极端变化敏感。