

引导采样 Classifier-Free Guidance(CFG)一直以来都是视觉生成模型中的关键技术。然而最近,清华大学 TSAIL 团队提出了一种极其简单的方法,实现了原生无需引导采样视觉模型的直接训练。他们在 Stable Diffusion,DiT,VAR,LlamaGen,MAR 五个截然不同的视觉架构上进行了验证,一致发现新方法性能与 CFG 相当,而采样成本减半。

- 算法名称:Guidance-Free Training (GFT)
- 论文链接:https://arxiv.org/abs/2501.15420

文生图任务中,免引导采样算法 GFT 与引导采样算法 CFG 均能大幅提升生成质量,而前者更为高效。

GFT 可通过调节采样时的「温度系数」来调节 diversity-fidelity trade-off

与此同时,GFT 算法保持了与 CFG 训练流程的高度一致,只需更改不到 10 行代码就可轻松实现。
视觉引导采样的问题与挑战
生成质量和多样性是相互牵制的关系。大语言模型(LLMs)主要通过将模型输出直接除以一个采样温度系数 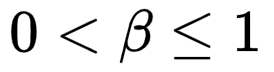 来权衡二者,可明显提高生成质量。然而,早期研究却发现这类温度采样方法对视觉生成完全不起作用。如今,视觉生成依赖引入一个新的无条件模型,用引导采样(CFG)达到类似温度采样的效果:
来权衡二者,可明显提高生成质量。然而,早期研究却发现这类温度采样方法对视觉生成完全不起作用。如今,视觉生成依赖引入一个新的无条件模型,用引导采样(CFG)达到类似温度采样的效果:
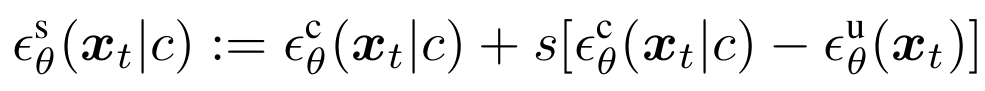
然而,CFG 中引入的无条件模型却给视觉模型训练带来了种种掣肘,因为在每一个采样步我们都需要进行有条件和无条件两次模型推理,导致计算开销倍增。此外,在对预训练模型微调或进一步蒸馏时,我们也需要分别考虑有条件和无条件两个视觉模型的训练,这又增加了模型训练的开销及算法复杂度。
为了避免 CFG 引导采样导致的额外计算开销,已有的方法大多采用基于一个预训练好的 CFG 教师模型继续蒸馏的手段。但这引入了一个额外的训练阶段,可能会带来性能损失。
GFT 算法正是尝试解决这一问题。简单说,它实现了原生免 CFG 视觉模型从零训练,且有着和 CFG 相当的收敛速度,算法稳定性与采样表现。更重要的是,它足够简洁、通用。一种算法可同时用于扩散、自回归、掩码三种视觉模型。
Guidance Free Training 算法设计
GFT 完全采用了监督训练中的扩散损失函数。在训练中,其和 CFG 最大的不同是:GFT 并不显式参数化一个「有条件视觉模型」,而是将其表示为一个采样模型和一个无条件模型的线性组合:

这样在在我们训练这个「隐式」有条件模型时,我们本质上在直接训练其背后参数化好的采样模型。
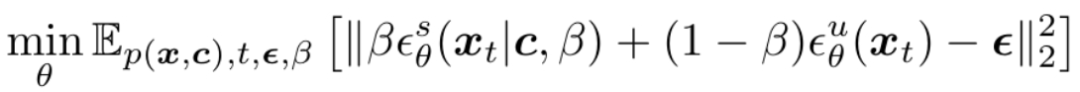
论文证明,随着线性组合系数 β(又称「伪温度系数」)的变化,其对应的采样模型将和 CFG 算法定义的采样分布一一对应。
GFT 的算法灵魂:简单、高效、兼容
在实际部署中,由于 GFT 算法在设计上可以与 CFG 训练方法保持了高度对齐,这使得其可以最低成本被部署实现(<10 行代码),甚至不需要更改已有代码的训练超参数。

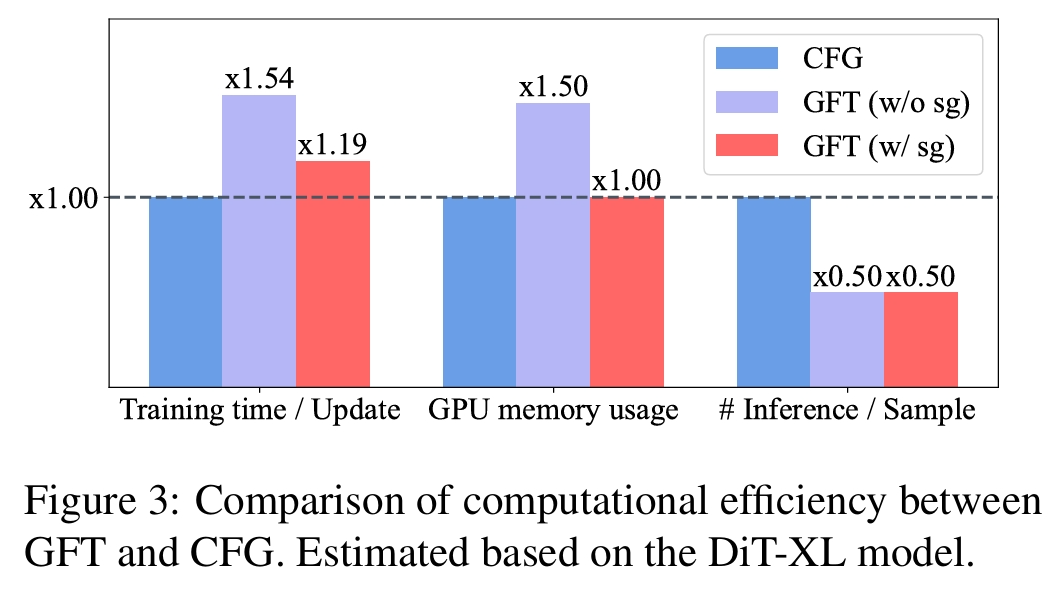
GFT 训练也非常高效,与 CFG 相比,它不需要任何额外的内存开销,只需增加约 20% 的训练时间,即可节约 50% 的采样成本。
此外,GFT 高度通用。不仅仅适用于扩散视觉模型,对于自回归、掩码这类离散视觉模型也同样适用:
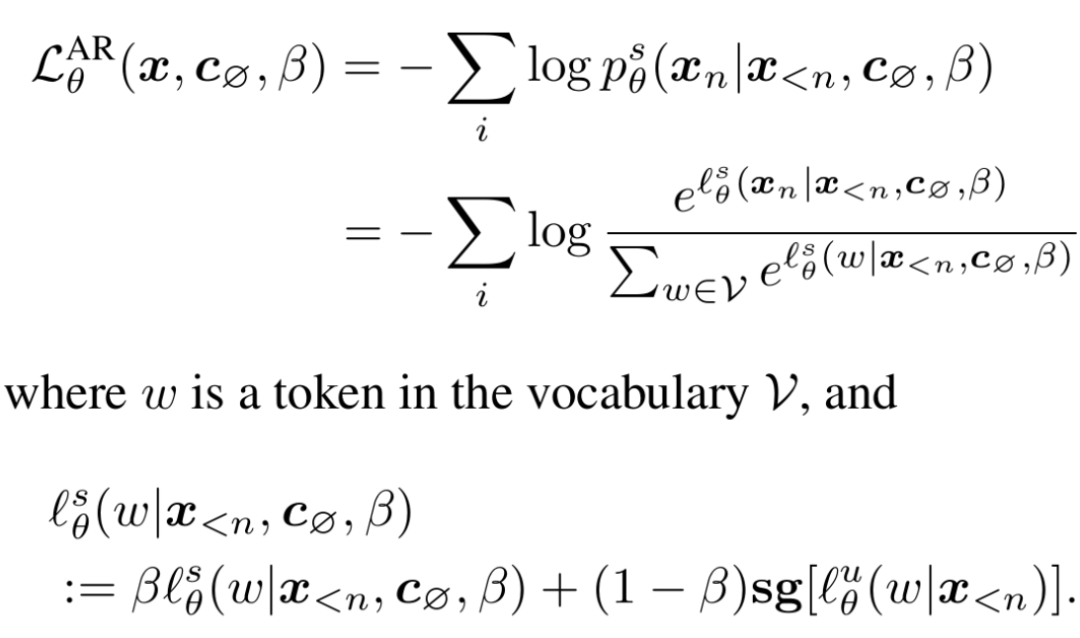
实验验证
GFT 在扩散模型 DiT、Stable Diffusion,自回归模型 VAR,LlamaGen,掩码扩散模型 MAR 五个截然不同的模型上面分别进行了实验验证。
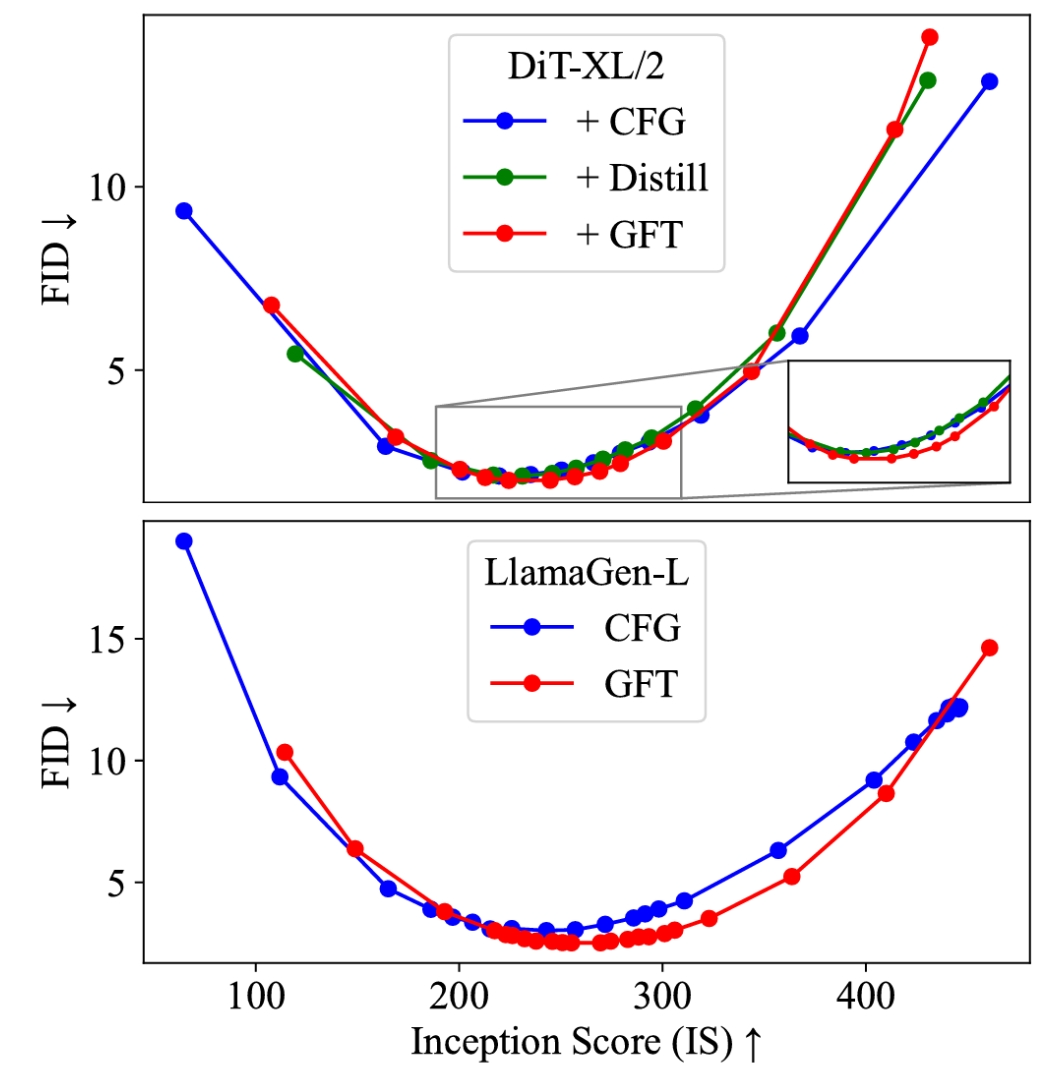
首先,研究者测试了 GFT 作为一个微调算法,把当下已有的 CFG 预训练模型转换为免引导采用模型的能力。发现在 FID 指标上,GFT 可以做到无损转换。
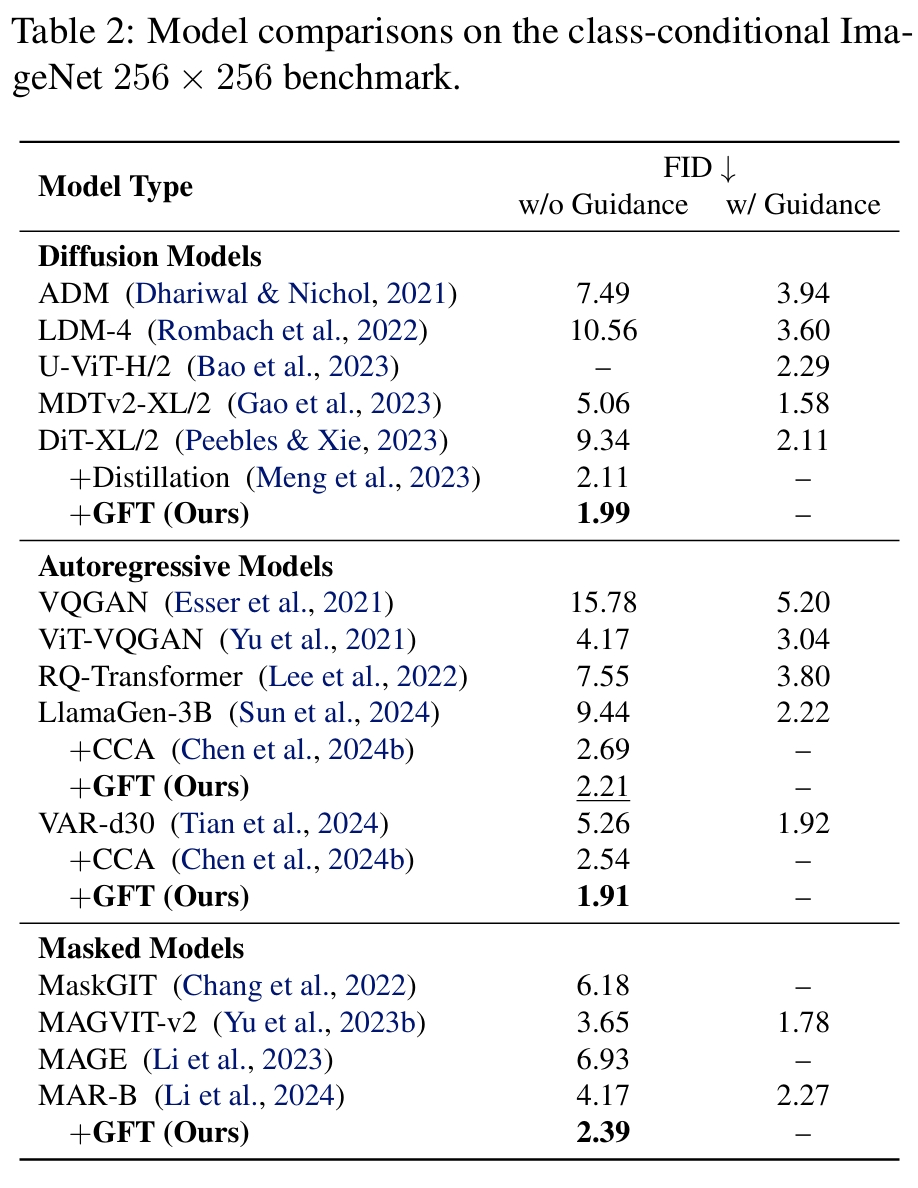
随后、研究者测试了 GFT 作为一个预训练算法,和 CFG 训练的比较(相同训练步)。
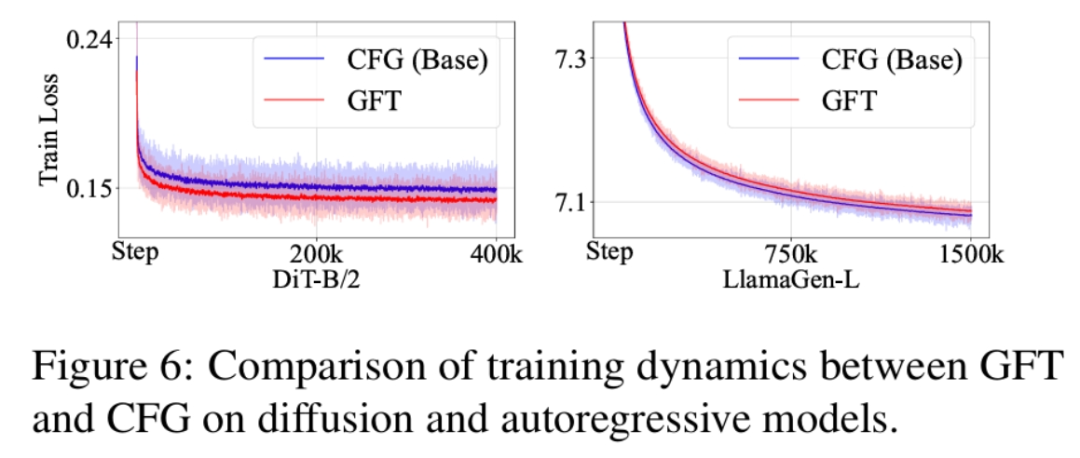
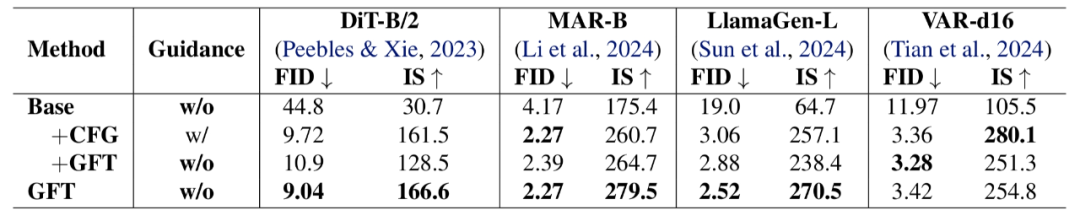
结果表明,GFT 训练出的免引导采用模型能力与 CFG 模型持平甚至更优。连损失函数收敛曲线也基本重合。
最后,论文还在不同模型上测试了 GFT 对于采样质量和多样性权衡曲线的控制能力。
作者介绍
本文有两位共同一作。陈华玉、清华大学计算机系四年级博士生。主要研究方向为强化学习与生成式模型。曾在 ICML/NeurIPS/ICLR 国际会议上发表多篇学术论文。是开源强化学习算法库「天授」的主要作者(Github 8k 星标)。导师为朱军教授。
姜凯、清华大学 TSAIL 团队实习生,主要研究方向为视觉生成模型。导师为陈键飞副教授。
文章来自:51CTO