

大家好,我是肆〇柒。今天要和大家分享一项来自SII-GAIR联合实验室的研究——LIMI。这个由上海交通大学(SJTU)、智源研究院(SII)和粤港澳大湾区数字经济研究院(GAIR)等机构的青年学者们共同完成的工作,这项研究的创新思考将启发我们对智能体训练的认知。他们不仅提出了一个大胆的假设,更用令人信服的实证结果,向整个AI领域证明:机器自主性的新时代,已经到来。
想象一下:你是一家科技公司的AI团队负责人,正面临一个棘手问题:公司需要开发能自主完成软件开发任务的智能体,但传统方法要求收集数万条交互数据,每条都需要人工标注,成本高昂且周期漫长。正当你准备申请更多预算时,LIMI研究带来了转机——仅用78个精心设计的训练样本,就能训练出性能远超使用10,000样本训练的模型的智能体。这不仅是效率的胜利,更是对”数据规模决定智能水平”这一传统认知的根本性颠覆。
在人工智能大发展下到今天,一个根本性问题正日益凸显:当行业从”思考AI”向”工作AI”转型时,我们是否仍在用错误的方式培养机器自主性?当前的AI系统虽然在推理和生成响应方面表现出色,但产业界迫切需要能够执行任务、操作工具、驱动真实世界结果的自主智能体(Agent)。这种能力被定义为”Agency”——AI系统作为自主智能体运作的涌现能力:通过自我导向地与环境和工具互动,主动发现问题、形成假设并执行解决方案。LIMI(Less Is More for Intelligent Agency)研究的出现,不仅颠覆了这一传统认知,更将”少样本高效训练”范式推向了新的理论高度,标志着AI发展从”蛮力时代”向”巧思时代”的关键转折。
为什么智能体是”少样本训练”的终极试金石?
智能体任务:比你想象的复杂10倍
智能体能力之所以成为检验”少样本高效训练”范式的终极试金石,源于其内在的复杂性和多维度挑战。与传统的单轮对话任务不同,智能体必须处理长时程任务,这些任务展现出独特的复杂性特征。

Gomoku任务示例
以上图中的Gomoku游戏开发任务为例,一个单一查询就包含了5个相互关联的子任务,覆盖了规划、执行和协作多个维度。这种任务要求智能体具备多轮交互的连贯状态跟踪能力,能够将复杂目标分解为可管理的子目标,并根据环境反馈动态调整策略。
要点:在开发一个15×15棋盘游戏的过程中,智能体需要依次实现UI渲染、胜负检测、状态管理、AI对手开发等多个层次的功能,每个环节都依赖前一环节的正确执行。这种任务结构要求智能体必须理解任务的层次性,能够将复杂目标分解为可管理的子目标,并在各阶段保持状态一致性。
智能体能力的四大核心挑战
长时程任务特性:如上图所示,Gomoku游戏开发任务的五个子任务形成了清晰的层次结构:技术实现能力(子任务1-2)、状态管理能力(子任务3)和AI策略能力(子任务4-5)。这种多层次任务结构要求智能体能够维持连贯的思维链条,将复杂目标分解为可管理的子目标,并在各阶段保持状态一致性。
工具编排需求:真实世界的智能体任务要求协调使用多个系统并集成结果处理。无论是调用代码编辑器、版本控制系统,还是操作数据分析工具,智能体必须理解何时使用何种工具,以及如何将工具输出整合到整体解决方案中。这种能力超越了单纯的语言理解,涉及对工具生态的深刻认知和灵活运用。
协作沟通要素:在Task 5的LLM性能比较任务中,智能体需要理解用户对”DynToM数据集”的查询需求,自主完成数据下载、API调用、结果分析等步骤,并以人类可理解的方式呈现比较结果。这种人-AI协作能力是智能体区别于被动AI系统的关键特征。
战略规划能力:在Task 1的C++聊天系统开发中,智能体必须理解从基本登录注册系统到高级功能如好友别名和全局搜索的递进式需求,并能将复杂目标分解为可管理的子目标。这种战略规划能力使智能体能够处理需要多轮交互和累积推理的复杂任务。
传统方法的困境与理论假设
在智能体领域,盲目应用Scaling Law会遇到更大障碍——数据标注成本极高、环境交互难以规模化。当前方法假设更多数据必然带来更好的智能体能力,但这一基本假设尚未经过充分测试。
关键转折点:如果”少样本高效”范式能在智能体领域成功,那么它几乎可以在任何AI子领域成功,因为智能体能力整合了自主任务执行、多步推理和协作问题解决等核心能力。LIMI研究正是这一范式的终极验证,它将决定我们是继续在数据规模上投入更多资源,还是转向更高效的战略性数据精炼。
LIMI——为智能体量身定制的”精炼”框架
为什么是Vibe Coding和Research Workflows?
LIMI团队战略性地选择了”Vibe Coding”和”科研工作流”作为切入点,这一选择具有深刻意义。这两个领域共同覆盖了大多数知识工作场景,需要完整的智能体能力谱系。
Vibe Coding代表了协作式软件开发场景,要求代码理解与生成、开发环境导航、迭代问题解决和协作沟通,需要对开发上下文的整体理解与原则性决策能力。例如,在Task 3的Gomoku游戏开发中,智能体必须理解从基础UI渲染到高级AI策略的递进式需求,并能在多轮交互中保持状态一致性。
科研工作流则涵盖了文献搜索、数据分析、实验设计和洞察生成,需要从创意假设生成到严谨分析执行的完整推理链条。在Task 8的科学系统函数发现任务中,智能体必须通过迭代修改方程,将损失从10^-3逐步降低到10^-7,展示出强大的科学推理能力。

啊哈时刻:这两个领域天然具备高密度学习信号,一个查询往往包含多个相互关联的子任务,为智能体提供了丰富的学习机会。上表中的10个任务精心设计,全面测试智能体在真实协作场景中的能力。
LIMI方法论的三大创新
创新一:从”单轮指令”到”多轮轨迹”的形式化


LIMI训练数据特征
上图的关键启示:左侧数据显示,LIMI训练数据的轨迹长度从13k到152k tokens不等,平均达42.4k tokens,这远超传统单轮对话任务的长度。这种复杂性源于智能体必须在多轮交互中维持状态一致性、进行累积推理并协调工具使用,而不仅仅是生成单轮响应。右侧的领域覆盖图则显示,LIMI在vibe coding和research workflows两大领域实现了均衡分布,确保了训练数据能够全面覆盖知识工作的主要场景。
创新二:从”人工编写”到”真实合成”的系统化流程
LIMI的数据构建流程展现了前所未有的严谨性。在GitHub PR查询合成环节,研究团队实施了五步质量保障机制:
1. 仓库选择:>10,000 stars确保高质量代码库
2. 领域多样化:覆盖前端、后端、部署基础设施、调试和代码优化
3. 复杂度过滤:统一diff patch token计数<1,200 tokens
4. 规模与抽样:100个仓库中各抽样100个PR
5. 质量保证:四位计算机科学博士生评估语义对齐度
要点:这种系统化流程确保了每个样本都具有最大信息价值,而非简单地增加样本数量。最终战略性采样18个最佳匹配核心领域的查询,与真实场景收集的60个查询共同构成了78个高质量训练样本。
创新三:从”模型输出”到”人-AI协作”的轨迹收集
LIMI创新性地采用”人-AI协作”的轨迹收集方式。在SII CLI环境中,四位博士生作为人类协作者与GPT-5(作为智能体模型)协作,采用迭代收集方法,持续收集轨迹直到成功完成。
啊哈时刻:这种方法确保收集的轨迹捕获自然的人-AI交互模式,包括迭代精炼和协作问题解决策略。这些轨迹不是人工编写的理想化示例,而是真实协作过程中产生的自然交互,包含了丰富的错误恢复、策略调整和协作沟通模式——这些正是智能体能力的关键组成部分。
理论贡献:智能体效率原则
LIMI的研究确立了”智能体效率原则”——机器自主性源于高质量智能体示范的战略性精炼,而非数据丰富性。这一发现从根本上重塑了我们开发自主AI系统的方式。
要点:传统观点认为,智能体能力的提升必然伴随着数据规模的指数级增长,这一假设源于语言模型领域的Scaling Law。然而,LIMI证明在智能体领域,数据质量与战略性精炼比单纯的数据规模更为关键。这一发现具有深远的理论意义:它表明智能体能力是一种涌现属性,源于对高质量交互模式的深度理解,而非对海量数据的表面拟合。
实证
性能碾压:少即是多的实证
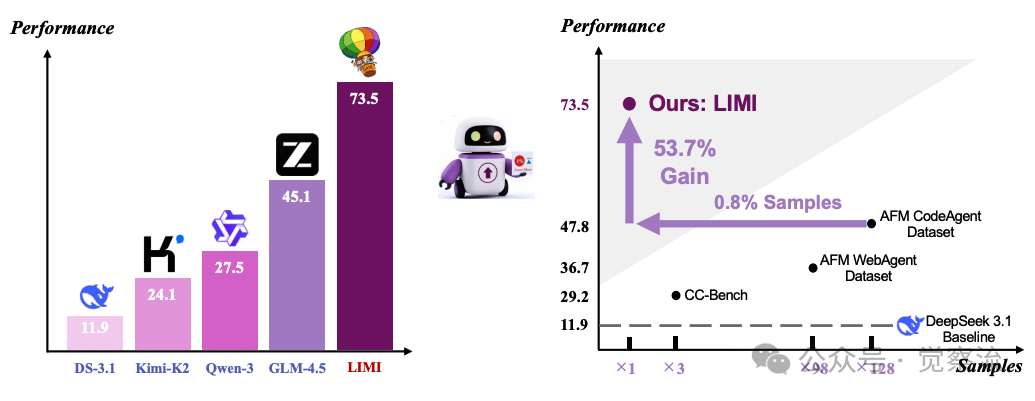
LIMI性能对比
上图揭示了一个当下反常识的事实:在智能体能力培养上,”少”真的能带来”多”。左边图表清晰显示,LIMI仅用78个样本就达到了73.5%的性能,大幅超越所有使用大规模数据训练的模型。但真正震撼的是右边图表——LIMI用128倍更少的样本(78 vs. 10,000),实现了53.7个百分点的性能提升!
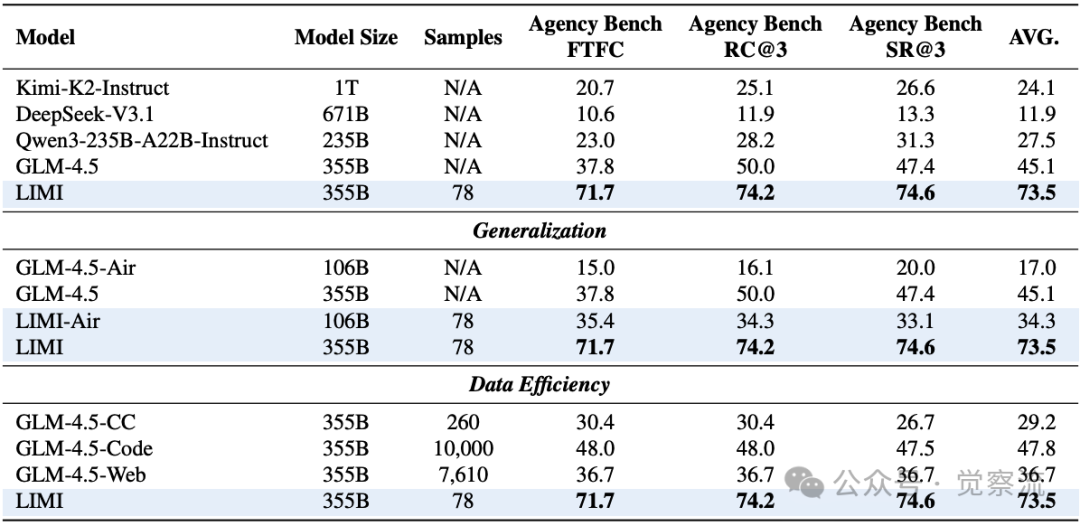
要点:在AgencyBench上,LIMI达到73.5%,大幅超越所有SOTA模型:GLM-4.5(45.1%)、Kimi-K2-Instruct(24.1%)、DeepSeek-V3.1(11.9%)、Qwen3-235B-A22B-Instruct(27.5%)。参考下一节的表格展示了LIMI在关键指标上的全面领先:首次功能完整性(FTFC)71.7%(vs. GLM-4.5的37.8%)、剩余机会(RC@3)74.2%、成功率(SR@3)74.6%。
啊哈时刻:想象一下,传统方法需要跑128公里才能到达终点,而LIMI只需跑1公里就能超越。这不仅意味着训练成本的大幅降低,更暗示着我们对智能体能力本质的理解可能存在根本性偏差。
效率革命:128倍更少样本的奇迹
LIMI的突破性不仅体现在性能上,更在于其惊人的效率。仅用78个精心设计的训练样本,LIMI比使用10,000样本的GLM-4.5-Code(47.8%)高出53.7个百分点,实现128倍更少样本下的性能超越。
在来看看下表:对比GLM-4.5-Code(10,000样本)和LIMI(78样本),性能差距达53.7个百分点,这一结果彻底颠覆了”更多数据=更好性能”的传统认知。更令人惊讶的是,LIMI-Air(106B)将GLM-4.5-Air的17.0%提升至34.3%,表明即使是中等规模的模型,通过战略性数据精炼,也能达到接近大型模型的智能体能力。
要点:这一发现对资源受限环境下的智能体部署具有重大意义,为AI行业提供了更可持续的发展路径。
泛化与鲁棒性:跨领域验证
LIMI不仅在AgencyBench上表现出色,在多样化基准上也保持优势。下表显示,LIMI在TAU2-bench、EvalPlus、DS-1000和SciCode等基准上平均性能达57.2%,比GLM-4.5-Code(40.9%)高出39.9%的相对提升。
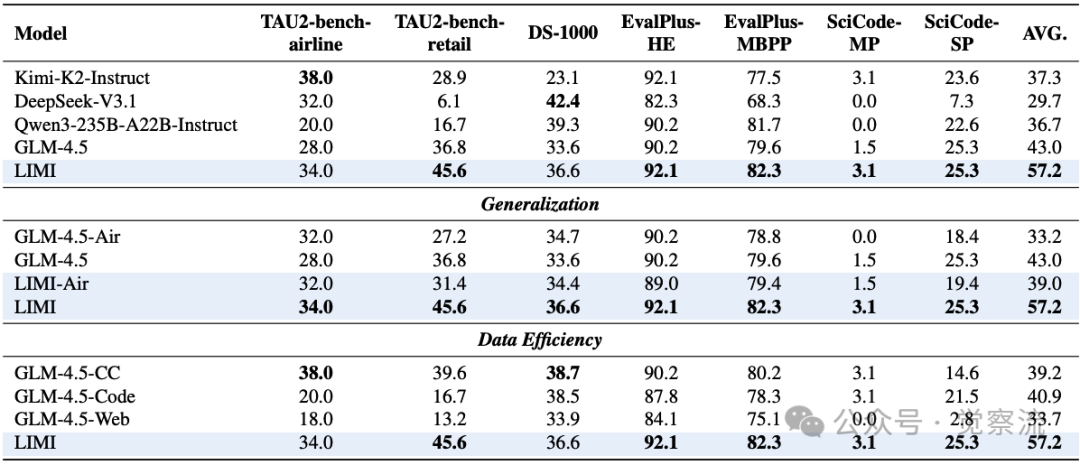
关键案例:在Task 8的科学系统函数发现任务中(如下),LIMI仅需首次尝试就将损失降至5.95e-7,比经过多轮交互的基线模型(1.14e-6)高出一个数量级。在Task 9的NBA球员识别任务中,LIMI能够准确识别出Kevin Durant,且所需的推理步骤、token数量和响应时间显著少于基线模型。
下面是两个任务的描述:
“Task 8 is designed to test the agent’s ability to create equations that fit data, with subtasks requiring progressively smaller loss values. For GLM-4.5-Base, after multiple rounds of manual interaction and prompting, the final loss reached 1.14e-6. In contrast, GLM-4.5-LIMI achieved a loss of 5.95e-7 on its very first attempt—an order of magnitude smaller.”
注:任务8目标是考察模型根据数据拟合方程的能力,各子任务对损失值的要求逐级递减。GLM-4.5-Base在人工多轮交互和提示后,最终损失仅降至1.14×10⁻⁶;而GLM-4.5-LIMI首次尝试便达到5.95×10⁻⁷,比前者小了一个数量级。
“Task 9 evaluates the agent’s ability to search the web, integrate information, and provide a final judgment using reasoning. It consists of three specific subtasks involving NBA players to be identified according to given conditions: For the first subtask, GLM-4.5-Base initially answered Victor Oladipo, and only after one round of manual prompting did it produce the correct answer, Paul George. GLM-4.5-LIMI, however, answered correctly without any additional hints. For the second subtask, GLM-4.5-Base exhausted all allowed manual prompts, producing incorrect answers such as Nate ”Tiny” Archibald and Wilt Chamberlain. GLM-4.5-LIMI, although it first incorrectly answered Oscar Robertson, required only one manual prompt to arrive at the correct answer, James Harden. For the third subtask, both models answered correctly with Kevin Durant. However, GLM-4.5-LIMI required significantly fewer reasoning steps, tokens, and response time. For the fourth subtask, GLM-4.5-Base failed even after reaching the maximum number of allowed manual prompts. GLM-4.5-LIMI, though initially incorrect with Jamal Murray, needed only one additional prompt to provide the correct answer, Klay Thompson.”
注:任务9评估了智能体搜索网络、整合信息并运用推理做出最终判断的能力。该任务包含三个关于NBA球员的具体子任务,要求根据给定条件识别球员。
在第一个子任务中,GLM-4.5-Base最初给出的答案是维克托·奥拉迪波,仅在经过一轮人工提示后才得出正确答案保罗·乔治。然而,GLM-4.5-LIMI无需任何额外提示便直接答对了。
在第二个子任务中,GLM-4.5-Base用尽了所有允许的人工提示次数,给出了诸如“小精灵”奈特·阿奇博尔德和威尔特·张伯伦等错误答案。GLM-4.5-LIMI虽然最初错误地回答了奥斯卡·罗伯特森,但仅经过一次人工提示便得出了正确答案詹姆斯·哈登。
在第三个子任务中,两个模型都正确回答了凯文·杜兰特。然而,GLM-4.5-LIMI在推理步骤、token消耗和响应时间上都明显更少。
在第四个子任务中,即便达到了允许的最大人工提示次数,GLM-4.5-Base仍未答对。GLM-4.5-LIMI虽然最初错误地回答了贾马尔·穆雷,但仅经过一次额外提示便给出了正确答案克莱·汤普森。
内在能力提升:不仅仅是工具的胜利

无CLI环境性能对比
上表的关键发现:即使在没有CLI工具的环境下,LIMI仍以50.0%的成绩超越GLM-4.5(48.7%)。这一结果确凿证明性能提升源于模型内在能力的增强,而非外部工具的”作弊”。当集成SII CLI环境时,LIMI的性能进一步提升至57.2%,表明其不仅改进了基础推理能力,还发展了复杂的工具协调技能。
啊哈时刻:LIMI带来的不仅是工具使用能力的提升,更是真正的智能体能力进化。这表明”少样本高效训练”范式能够培养出具有内在智能的AI系统,而非仅仅依赖外部工具的”假智能”。
“少样本高效”范式的未来
对智能体研究的革命性影响
LIMI为智能体研究提供了新的基线和方法论,将推动整个领域向更高效、更可持续的方向发展。它证明了高质量示范的战略性精炼比数据规模更重要,为智能体开发提供了新范式。

价值:对AI研究员而言,LIMI意味着可以将资源从大规模数据收集转向更精细的数据工程,大幅降低研究成本。上表中的数据表明,即使是106B参数的模型,通过LIMI方法也能达到接近355B模型的性能,这为资源受限的研究团队提供了新的可能性。
对更广泛AI领域的启示
LIMI强化了”数据质量 > 数据数量”的共识,鼓励研究者在数据工程上投入更多精力。这一范式为其他AI子领域提供了可借鉴的方法论,特别是在需要长期规划和工具使用的场景。
关键启示:LIMA仅用1,000个精心策划的示例实现有效模型对齐,LIMO仅用817个样本实现复杂数学推理,而LIMI则将这一范式推向了智能体领域的巅峰。这表明”少样本高效训练”可能是一种普适原则,适用于AI能力的各个维度。
与你的工作有何关联?
如果你是AI研究员:LIMI证明了在智能体领域,数据质量比数量更重要。这意味着你可以将资源从大规模数据收集转向更精细的数据工程,大幅降低研究成本。
如果你是AI工程师:LIMI-Air(106B)将GLM-4.5-Air的17.0%提升至34.3%,这表明即使是中等规模的模型,通过战略性数据精炼,也能达到接近大型模型的智能体能力。这意味着你可以在资源受限的环境中部署高效智能体。
如果你是企业决策者:LIMI实现了128倍更少样本下的性能超越,这直接转化为训练成本的大幅降低和开发周期的显著缩短。当行业正从”思考AI”向”工作AI”转型的关键时刻,LIMI提供了一条高效、可持续的路径。
局限
LIMI也有其局限:当前方法仍依赖人工筛选高质量样本,自动化程度有待提高;在极端复杂或全新领域的任务上,可能需要更多领域特定样本。这些正是未来研究的重要方向:
1. 如何自动化”高质量示范”的生成过程,减少人工参与?
2. 如何将此范式应用到强化学习等更复杂的智能体训练场景?
3. 如何进一步优化数据选择策略,识别最具信息量的智能体交互模式?
从”蛮力时代”到”巧思时代”
LIMI的突破性不仅体现在技术层面,更在于其思想解放。它提醒我们,在AI发展的道路上,有时”少”确实能带来”多”,而理解智能体能力的本质,比盲目扩大数据规模更为重要。
所以,LIMI不仅是一项技术突破,也是思想范式的转变——它启发我们AI发展是可以从”蛮力”向”巧思”转变的。随着行业从”思考AI”向”工作AI”过渡,LIMI提供了一种可持续培养真正智能体智能的范式,证明有效智能体AI开发的关键在于战略性数据精炼,而并非仅仅依赖计算规模。
在智能体能力培养上,质量胜过数量,理解胜过规模,巧思胜过蛮力。当我们将注意力从数据规模转向数据质量,从计算资源转向认知本质,AI的未来将更加高效、可持续,也更接近真正的智能。有时候,少即是多。
文章来自:51CTO