
虽然大型语言模型(LLM)在文本分析和生成任务上的性能非常强大,但在面对包含数字的问题时,比如多位数乘法,由于模型内部缺乏统一且完善的数字分词机制,会导致LLM无法理解数字的语义,从而胡编乱造答案。
目前LLM还没有广泛应用于科学领域数据分析的一大阻碍就是数字编码问题。
最近,熨斗研究所(Flatiron Institute)、劳伦斯伯克利国家实验室、剑桥大学、纽约大学、普林斯顿大学等九个研究机构联合发布了一个全新的数字编码方案xVal,只需一个token即可对所有数字进行编码。

论文链接:https://arxiv.org/pdf/2310.02989.pdf
xVal通过将专用token([NUM])的嵌入向量按数值缩放来表示目标真实值,再结合修改后的数字推理方法,xVal策略成功使模型在输入字符串数字到输出数字之间映射时端到端连续,更适合科学领域的应用。
在合成和真实世界数据集上的评估结果显示,xVal比现有的数字编码方案不仅性能更好,而且更节省token,还表现出更好的插值泛化特性。
数字编码新突破
标准的LLM分词方案并没有对数字和文本进行区分,也就无法对数值进行量化。
之前有工作按照科学计数法的形式,以10为基底,将所有数字映射到有限的原型数字(prototype numerals)集合中,或是计算数字embedding之间的余弦距离来反映数字本身的数值差异,已经成功用于解决线性代数问题,诸如矩阵乘法等。
不过对于科学领域中的连续或平滑问题,语言模型仍然无法很好地处理插值和分布外泛化问题,因为将数字编码为文本后,LLM在编码和解码阶段本质上仍然是离散的,很难学习近似连续函数。
xVal的思路是对数值大小进行乘法(multiplicatively)编码,并在嵌入空间中将其定向到可学习的方向,极大地改变了Transformer架构中处理和解释数字的方式。
xVal使用单个token进行数字编码,具有token效率的优势以及最小的词典足迹(vocabulary footprint)。
结合修改后的数字推理范式,Transformer模型值在输入数字和输出字符串的数字之间的映射时是连续的(平滑),当近似的函数是连续或平滑时,可以带来更好的归纳偏差(inductive bias)。
xVal: 连续数字编码
xVal没有对不同的数字使用不同的token,而是直接沿着嵌入空间中特定可学习方向嵌入数值。

假设输入字符串中同时包含数字和文本,系统首先会对输入进行解析,提取出所有的数值,然后构造出一个新的字符串,其中数字被替换为[NUM]占位符,再将[NUM]的嵌入向量与其所对应的数值相乘。
整个编码过程可以用于遮罩语言建模(MLM)和自回归(AR)生成。
基于层归一化的隐式归一化(Implicit normalization via layer-norm)
在具体实现中,第一个Transformer块中的xVal的乘法嵌入(multiplicative embedding)之后需要加上位置编码向量,以及层归一化(layer-norm),基于输入样本对每个token的嵌入进行归一化。
当位置嵌入与[NUM]标记的嵌入不共线(collinear)时,标量值可以通过非线性重缩放函数(non-linear rescaling)进行传递。
假设u为[NUM]的嵌入,p为位置嵌入,x是被编码的标量值,为了简化计算可以假定u · p=0,其中∥u∥ =∥p∥ = 1,可以得到

即x的值被编码为与u同方向,并且该属性在训练后仍然可以保持。

这种归一化特性意味着xVal的动态范围比其他基于文本的编码方案的动态范围更小,在实验中设定为[-5, 5]以作为训练前的预处理步骤。
数值推理
xVal定义了在输入数值中连续的嵌入,但如果使用多分类任务作为输出和训练算法时,考虑到从输入数值到输出数值之间的映射,则模型作为一个整体不是端到端连续的,需要在输出层单独对数字进行处理。

根据Transformer语言模型中的标准实践,研究人员定义了一个token head,输出词汇表token的概率分布。
因为xVal使用[NUM]对数字进行替换,所以head不携带任何关于数值的信息,所以需要引入了一个具有标量输出的新number head,通过均方误差(MSE)损失进行训练,以恢复与[NUM]相关联的具体数值。
给定输入后,首先观察token head的输出,如果生成的token为[NUM],则查看number head来填充该token的值。
在实验中,由于Transformer模型在推断数值时是端到端连续的,所以当插值到未见过的数值时表现得更好。
实验部分
对比其他数字编码方法
研究人员将XVAL的性能与其他四种数字编码进行了比较,这些方法都需要先将数字处理为±ddd E±d的形式,然后再根据格式调用单个或多个token来确定编码。

不同方法对于编码每个数字所需要的token数量、词汇表数量都有很大不同,但总体来看,xVal的编码效率是最高的,并且词汇表尺寸也最小。
研究人员还在三个数据集上对xVal进行评估,包括合成的算术运算数据、全球温度数据和行星轨道模拟数据。
学习算术
即使对于最大的LLM来说,「多位数乘法」也仍然是一个极具挑战的任务,例如GPT-4在三位数乘法问题上仅能达到59%的zero-shot准确率,在四位数和五位数乘法问题上的准确率甚至只有4%和0%

从对比实验来看,其他数字编码通常也能很好地解决多位数乘法问题,不过xVal的预测结果相比P10和FP15来说更稳定,不会产生异常预测值。
为了提升任务难度,研究人员使用随机二叉树,使用加法、减法和乘法的二元运算符组合固定数量的操作数(2、3或4)构造出了一个数据集,其中每个样本都是一个算术表达式,例如((1.32 * 32.1) + (1.42-8.20)) = 35.592
然后根据每个数字编码方案的处理要求对样本进行处理,任务目标是计算等式左侧的表达式,即等式右侧为掩码。
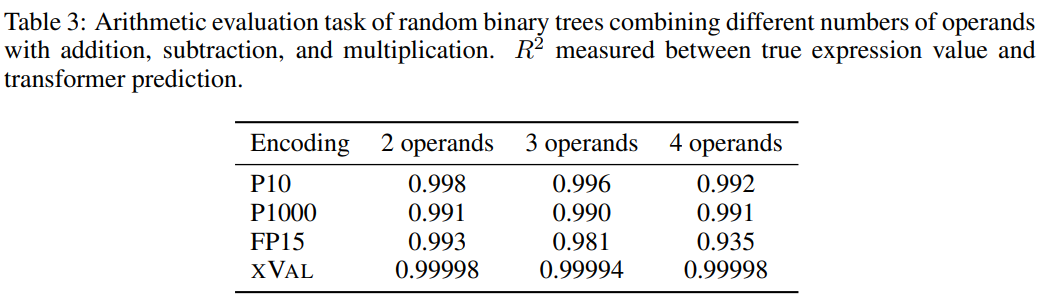
从结果来看,xVal在这个任务上表现得非常好,不过单靠算术实验不足以完全评估语言模型的数学能力,因为算术运算中的样本通常是短序列,底层数据流形是低维的,这些问题并没有突破LLMs在计算上的瓶颈,而现实世界中的应用更复杂。
温度预测
研究人员使用ERA5全球气候数据集的子集用作评估,简单起见,实验中只关注地表温度数据(ERA5中的T2m),然后对样本进行划分,其中每个样本包括2-4天的地表温度数据(一化后具有单位方差)以及来自60-90个随机选择的报告站的纬度和经度。
对坐标的纬度的正弦和经度的正弦和余弦编码,从而保持数据的周期性,然后使用同样的操作对24小时和365天周期中位置进行编码。

坐标(coords)、起点(start)和数据(data)对应于报告站坐标、第一个样本的时间和标准化温度数据,然后使用MLM方法来训练语言模型。
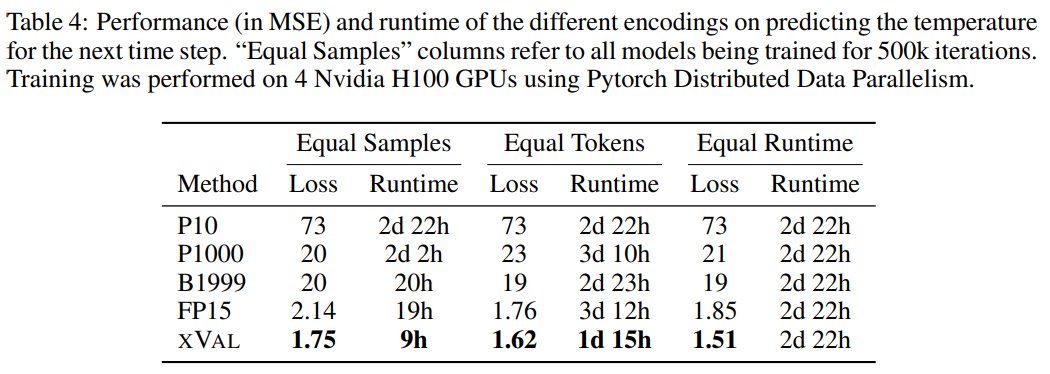
从结果来看,xVal的性能最好,同时计算所需时间也显著降低。

这项任务也说明了基于文本编码方案的缺点,模型可以利用数据中的虚假相关性,即P10、P1000和B1999具有预测归一化温度±0.1的趋势,主要原因是该数字在数据集中出现的频率最高。
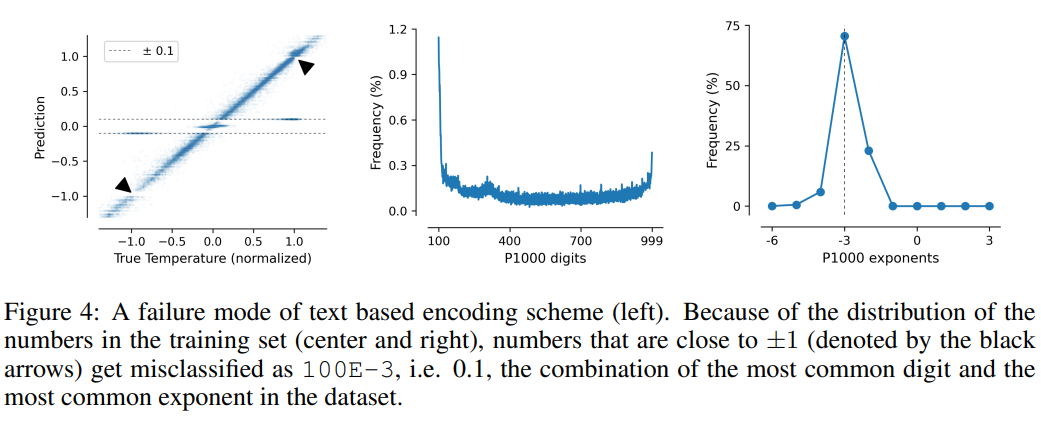
对于P1000和P10方案来说,二者的编码输出平均分别约为8000和5000个token(相比之下,FP15和xVal平均约为1800个token),模型的不良性能可能是由于长距离建模的问题。