
在 Web 开发中,上传文件至服务器前的文件类型检测至关重要。这一步骤不仅能够确保服务器和用户的安全,拦截可能的恶意文件,还能保证上传的文件完整且符合预期,提高数据的合规性。同时,通过及时给予用户反馈和指导,也能提升用户体验,避免不必要的困惑。
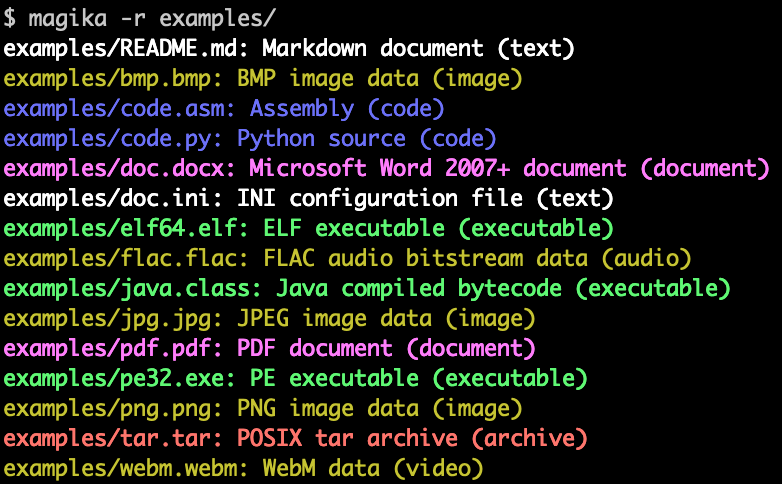
之前阿宝哥有介绍过 “JavaScript 如何检测文件的类型?”,现在我们已经进入 AI 时代,要与时俱进。接下来,阿宝哥将介绍如何利用谷歌开源的 Magika[1] 工具,实现精准的文件类型检测。
 图片
图片
Magika 简介
Magika 是一款新颖的人工智能文件类型检测工具,依靠最新的深度学习技术提供精确的检测。它采用了高度优化的定制 Keras 模型,该模型仅重约 1MB,即使在单 CPU 上运行,也能在几毫秒内实现精确的文件识别。
在对超过 100 万个文件和超过 100 种内容类型(涵盖二进制和文本文件格式)的评估中,Magika 实现了 99% 以上的精确度和召回率。Magika 被大规模使用,通过将 Gmail、云端硬盘和安全浏览文件路由到适当的安全和内容策略扫描仪,来保障 Google 用户的安全。
Magika 的特点
- 支持检测 100 多种文件类型。
- 支持 Python 命令行、Python API 和实验性 TFJS 版本等多种使用方式。
- 模型加载后(这是一次性开销),每个文件的推理时间约为 5 毫秒。
- 接近恒定的推理时间,与文件大小无关。Magika 仅使用文件字节的有限子集。
- 支持批处理:支持同时向命令行和 API 发送多个文件,Magika 将使用批处理来加快推理时间。
- 在包含 100 多种内容类型的超过 2500 万个文件的数据集上进行了训练。
- 经过大规模评估,Magika 的平均精确度和召回率达到 99% 以上,优于现有方法。
- Magika 使用每个内容类型的阈值系统来确定是否“信任”模型的预测,或者是否返回通用标签,例如“通用文本文档”或“未知二进制数据”。
- 支持三种不同的预测模式,调整对错误的容忍度:高置信度、中等置信度和最佳猜测。
Magika 的性能
 图片
图片
性能方面,Magika 凭借其 AI 模型和大型训练数据集,在包含 100 多种文件类型的 1M 文件基准测试上进行评估时,其性能比其他现有工具高出约 20%。按文件类型细分,如下表所示,我们发现文本文件的性能提升更大,包括其他工具可能难以处理的代码文件和配置文件。
 图片
图片
Magika 在线示例
Magika 支持浏览器和 Node.js 环境,你可以通过访问 Web Demo[2] 网站来体验它的功能。
 图片
图片
Magika 快速上手
安装 magika
浏览器中使用 magika
Node.js 中使用 magika
有关 Magika 的相关内容就介绍到这里,如果你想进一步了解 Magika,可以继续阅读 Magika: AI powered fast and efficient file type identification[3] 这篇文章。
参考资料
[1]Magika: https://github.com/google/magika
[2]Web Demo: https://google.github.io/magika/
[3]Magika: AI powered fast and efficient file type identification: https://opensource.googleblog.com/2024/02/magika-ai-powered-fast-and-efficient-file-type-identification.html