


-
何为“资源” -
不同操作都耗费什么资源 -
如何充分的利用有限的资源 -
如何合理选择显卡
-
显存和GPU等价,使用GPU主要看显存的使用? -
Batch Size 越大,程序越快,而且近似成正比? -
显存占用越多,程序越快? -
显存占用大小和batch size大小成正比?

-
显存占用 -
GPU利用率
watch --color -n1 gpustat -cpu-
显存用于存放模型,数据 -
显存越大,所能运行的网络也就越大
1*2+3 1 flop1*2 + 3*4 + 4*5 3 flop2.1 存储指标
1Byte = 8 bit1K = 1024 Byte1M = 1024 K1G = 1024 M1T = 1024 G
10 K = 10*1024 Byte1Byte = 8 bit1KB = 1000 Byte1MB = 1000 KB1GB = 1000 MB1TB = 1000 GB
10 KB = 10000 Byte-
Type:有Int,Float,Double等 -
Num: 一般是 8,16,32,64,128,表示该类型所占据的比特数目
2.2 神经网络显存占用
-
模型自身的参数 -
模型的输出
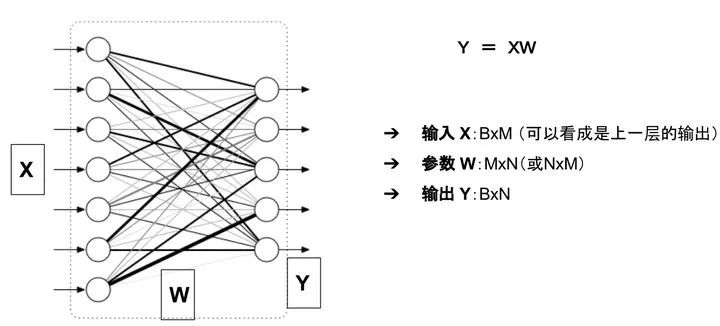
-
参数:二维数组 W -
模型的输出:二维数组 Y
2.2.1 参数的显存占用
-
卷积 -
全连接 -
BatchNorm -
Embedding层 -
… …
-
多数的激活层(Sigmoid/ReLU) -
池化层 -
Dropout -
… …
-
Linear(M->N): 参数数目:M×N -
Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K -
BatchNorm(N): 参数数目:2N -
Embedding(N,W): 参数数目:N × W
2.2.2 梯度与动量的显存占用
,因此显存占用等于参数占用的显存x2,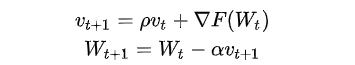
-
参数 W -
梯度 dW(一般与参数一样) -
优化器的动量(普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍)
2.2.3 输入输出的显存占用
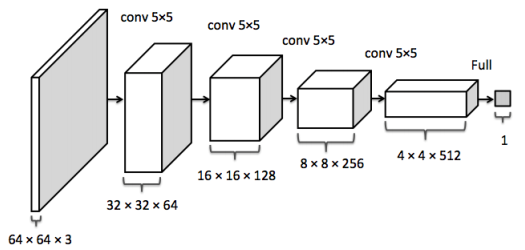
-
需要计算每一层的feature map的形状(多维数组的形状) -
需要保存输出对应的梯度用以反向传播(链式法则) -
显存占用与 batch size 成正比 -
模型输出不需要存储相应的动量信息。
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用-
输入(数据,图片)一般不需要计算梯度 -
神经网络的每一层输入输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,我们可以不要保存输入。比如ReLU,在PyTorch中,使用nn.ReLU(inplace = True) 能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。感兴趣的读者可以思考一下,这时候是如何反向传播的(提示:y=relu(x) -> dx = dy.copy();dx[y<=0]=0)
2.3 节省显存的方法
-
降低batch-size -
下采样(NCHW -> (1/4)*NCHW) -
减少全连接层(一般只留最后一层分类用的全连接层)
-
全连接层:BxMxN , B是batch size,M是输入形状,N是输出形状。 -
卷积的计算量:
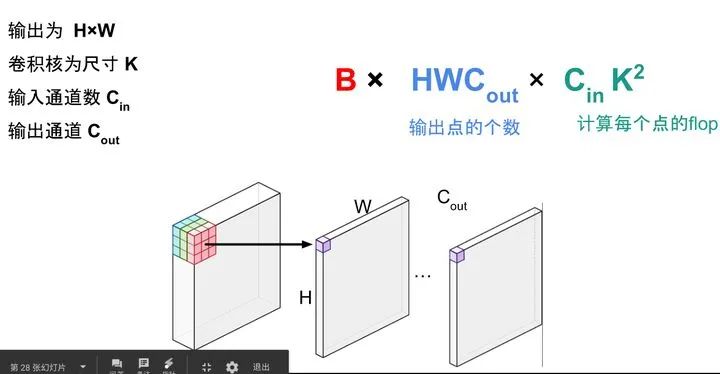
-
BatchNorm 计算量我个人估算大概是 , 欢迎指正 -
池化的计算量:
-
ReLU的计算量:BHWC
3.2 AlexNet 分析

-
全连接层占据了绝大多数的参数 -
卷积层的计算量最大
3.3 减少卷积层的计算量
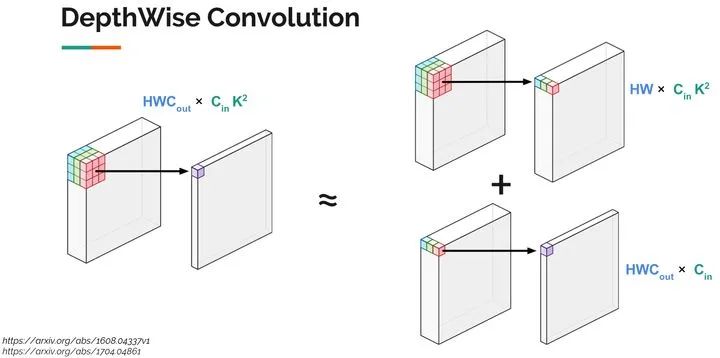
-
显存占用变多(每一步的输出都要保存) -
计算量变少了许多,变成原来的( )(一般为原来的10-15%)
3.4 常用模型 显存/计算复杂度/准确率
4.1 建议
-
时间更宝贵,尽可能使模型变快(减少flop) -
显存占用不是和batch size简单成正比,模型自身的参数及其延伸出来的数据也要占据显存 -
batch size越大,速度未必越快。在你充分利用计算资源的时候,加大batch size在速度上的提升很有限
-
增大batch size能增大速度,但是很有限(主要是并行计算的优化) -
增大batch size能减缓梯度震荡,需要更少的迭代优化次数,收敛的更快,但是每次迭代耗时更长。 -
增大batch size使得一个epoch所能进行的优化次数变少,收敛可能变慢,从而需要更多时间才能收敛(比如batch_size 变成全部样本数目)。
4.2 关于显卡选购
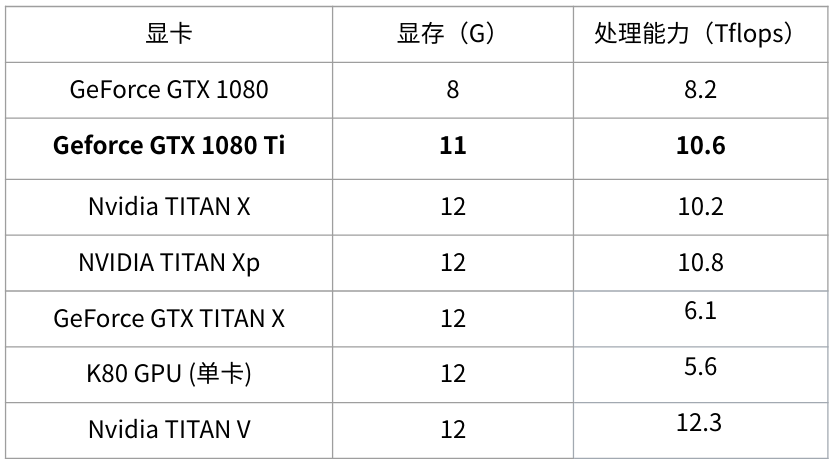
-
K80性价比很低(速度慢,而且贼贵) -
注意GTX TITAN X和Nvidia TITAN X的区别 -
tensorcore的性能目前来看还无法全面发挥出来, 这里不考虑. 其它的tesla系列像P100这些企业级的显卡这里不列了,普通消费者不会买, 而且性价比较低(一台DGX 1上百万…..)
![]()