

注意力是 Transformer 架构的关键部分,负责将每个序列元素转换为值的加权和。将查询与所有键进行点积,然后通过 softmax 函数归一化,会得到每个键对应的注意力权重。
尽管 SoftmaxAttn 中的 softmax 具有广泛的用途和有效性,但它并非没有局限性。例如,softmax 函数有时会导致注意力集中在少数几个特征,而忽略了其他信息。
近来,一些研究探索了 Transformer 中 softmax 注意力的替代方案,例如 ReLU 和 sigmoid 激活函数。最近,来自苹果的研究者重新审视了 sigmoid 注意力并进行了深入的理论和实验分析。
该研究证明:从理论上讲,与 softmax 注意力相比,具有 sigmoid 注意力的 Transformer 是通用函数逼近器,并且受益于改进的正则化。

- 论文地址:https://arxiv.org/pdf/2409.04431
- 项目地址:https://github.com/apple/ml-sigmoid-attention
- 论文标题:Theory, Analysis, and Best Practices for Sigmoid Self-Attention
该研究还提出了一种硬件感知且内存高效的 sigmoid 注意力实现 ——FLASHSIGMOID。FLASHSIGMOID 在 H100 GPU 上的推理内核速度比 FLASHATTENTION2 提高了 17%。
跨语言、视觉和语音的实验表明,合理归一化的 sigmoid 注意力与 softmax 注意力在广泛的领域和规模上性能相当,而之前的 sigmoid 注意力尝试无法实现这一点。
此外,该研究还用 sigmoid 内核扩展了 FLASHATTENTION2,将内核推理挂钟时间减少了 17%,将现实世界推理时间减少了 8%。
论文作者 Jason Ramapuram 表示:如果想让注意力快 18% 左右,你不妨试试 Sigmoid 注意力机制。他们用 Sigmoid 和基于序列长度的常量标量偏置取代了注意力机制中的传统 softmax。

Sigmoid 注意力
假设 为向量 n 的输入序列,每个向量是 d 维。接着研究者定义了三个可学习权重矩阵
为向量 n 的输入序列,每个向量是 d 维。接着研究者定义了三个可学习权重矩阵 、
、 以及
以及 。这三个矩阵用于计算查询
。这三个矩阵用于计算查询 ,键
,键 ,以及值
,以及值 。可以得到如下公式:
。可以得到如下公式:

根据先前的研究,自注意力可以简写为:

其中 Softmax 函数将输入矩阵的每一行进行了归一化。该研究将 Softmax 做了以下替换:
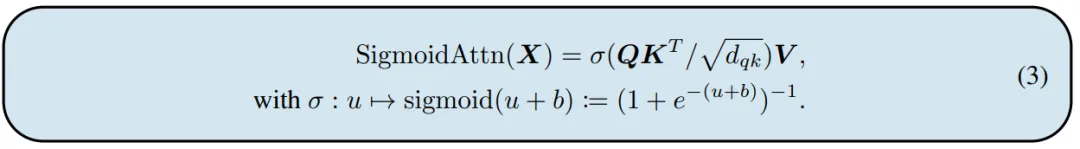
实际上,将 作为输出序列,可以得到:
作为输出序列,可以得到:

将多个 SigmoidAttn 输出进行组合,得到多个头的形式,如下所示:

Sigmoid 注意力理论基础
该研究对 SigmoidAttn 进行了分析,分析的目的主要有两个:(1)证明当 SigmoidAttn 取代 SoftmaxAttn 时,Transformer 架构仍然是一个通用函数逼近器;(2)通过计算 SigmoidAttn 的 Lipschitz 常数来恢复其规律性。
具有 Sigmoid 注意力的 Transformer 是通用逼近器吗?
经典 Transformer 可以将连续的序列到序列函数近似到任意精度,这一特性称为通用近似特性 (UAP,Universal Approximation Property)。UAP 非常受欢迎,因为它证明了架构的通用性和表示能力。由于 SigmoidAttn 修改了 Transformer 架构,因此从理论上保证这种修改不会影响表示能力并保留 UAP 的性能至关重要。该研究通过以下定理提供此保证。

结果表明,即使使用 SigmoidAttn,一系列 transformer 块也可以实现上下文映射。
Sigmoid 注意力的正则性
与神经网络中的任何层一样,SigmoidAttn 的正则性值得研究,因为它可以深入了解相应网络的鲁棒性及其优化的难易程度。
SigmoidAttn 正则性定理为:

结果证明,SigmoidAttn 的局部 Lipschitz 常数远低于 SoftmaxAttn 的最差局部 Lipschitz 常数。
FLASHSIGMOID:硬件感知实现
现代架构上的注意力计算往往会受到内存访问 IO 的限制。FLASHATTENTION 和 FLASHATTENTION2 通过优化 GPU 内存层次结构利用率来加速注意力计算。得益于这些方法提供的速度提升,该研究开发了 SigmoidAttn 的硬件感知实现 ——FLASHSIGMOID,采用了三个核心思路:
- Tiling:注意力分而治之的方法:与 FLASHATTENTION 和 FLASHATTENTION2 类似,FLASHSIGMOID 并行处理输入部分以计算块中的注意力输出,有效地组合部分结果以生成最终的注意力输出。
- 内核融合:与 FLASHATTENTION 和 FLASHATTENTION2 一样,FLASHSIGMOID 将 SigmoidAttn 的前向和后向传递的计算步骤实现为单个 GPU 内核,通过避免高带宽内存 (HBM) 上的中间激活具体化,最大限度地减少内存访问并提高内存效率。
- 激活重计算:sigmoid 注意力的向后传递需要 sigmoid 激活矩阵,如果在 GPU HBM 上具体化,则会导致执行速度变慢和内存效率低下。FLASHSIGMOID 通过仅保留查询、键和值张量来解决这个问题,以便在向后传递期间重新计算 sigmoid 激活矩阵。尽管增加了 FLOPs,但事实证明,与具体化和保留注意力矩阵的替代方法相比,这种方法在挂钟时间上更快,并且内存效率更高。
实验
为了实验验证 SigmoidAttn,该研究在多个领域进行了评估:使用视觉 transformer 进行监督图像分类、使用 SimCLR 进行自监督图像表示学习、BYOL(Bootstrap Your Own Latent)和掩码自动编码器 (MAE) 以及自动语音识别 (ASR) 和自回归语言建模 (LM)。
该研究还在 TED-LIUM v3 上验证了 ASR 的序列长度泛化,在所有这些领域和算法中,该研究证明 SigmoidAttn 的性能与 SoftmaxAttn 相当(图 2 和 21),同时提供训练和推理加速。


该研究得出以下观察结果:
SigmoidAttn 对于没有偏置的视觉任务是有效的(MAE 除外),但依赖于 LayerScale 以无超参数的方式匹配基线 SoftmaxAttn(图 9-a)的性能。除非另有说明,否则为 SoftmaxAttn 呈现的所有结果也公平地添加了 LayerScale。
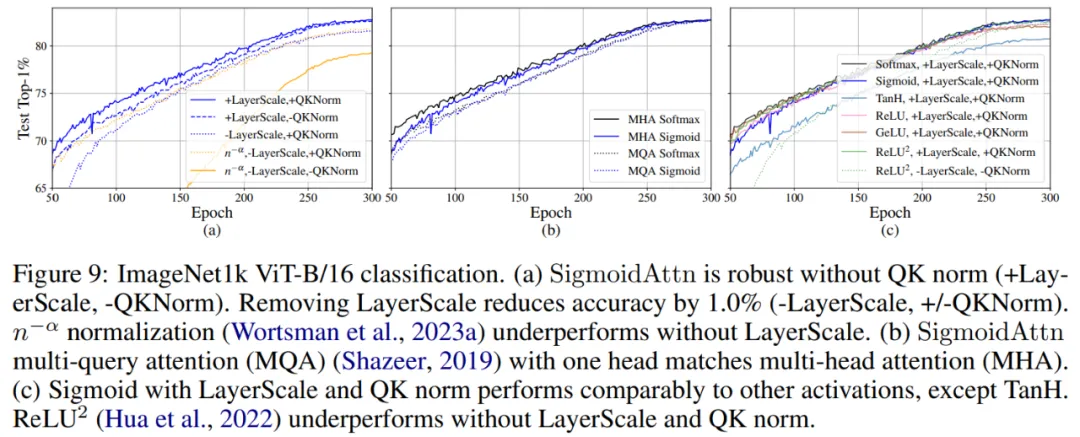
LM 和 ASR 对初始范数 较为敏感。需要通过 (a) 相对位置嵌入进行调整;(b) 适当初始化 b 以实现相同效果 —— 允许使用任何位置嵌入。
较为敏感。需要通过 (a) 相对位置嵌入进行调整;(b) 适当初始化 b 以实现相同效果 —— 允许使用任何位置嵌入。
感兴趣的读者可以阅读论文原文,了解更多研究内容。