

最近几年,大模型在技术领域的火热程度属于一骑绝尘遥遥领先,不论是各种技术论坛还是开源项目,大多都围绕着大模型展开。大模型的长期目标是实现AGI,这可能还有挺长的路要走,但是眼下它已经深刻地影响了“编程”领域。各种copilot显著地提升了开发者的效率,但与此同时,开发者也变得非常地焦虑。因为开发者们实实在在感受到了它强大的能力,虽然目前只能辅助还有很多问题,但随着模型能力的增强,以后哪天会不会就失业了?与其担忧,我们不如主动拥抱这种技术变革。
但是很多人又会打退堂鼓:研究AI的门槛太高了,而大模型属于AI领域皇冠上的明珠,可能需要深厚的数学和理论基础。自己的微积分线性代数概率论这三板斧早都忘光了,连一个最基础的神经网络反向传播的原理都看不懂,还怎么拥抱变革?
其实大可不必担心,不论大模型吹得如何天花乱坠,还是需要把它接入到业务中才能产生真正的价值,而这归根到底还是依赖我们基于它之上去做应用开发。而基于大模型做业务开发,并不依赖我们对AI领域有深入的前置了解。就好比我们做后台业务开发,说到底就是对数据库增删改查,数据库是关键中的关键。理论上你需要懂它了解它,但其实你啥也不懂也没太大影响,只是“天花板低“而已,有些复杂场景你就优化不了。基于大模型做应用开发也是一样,你不需要了解大模型本身的原理,但是怎么结合它来实现业务功能,则是开发者需要关心的。
本文是给所有非AI相关背景的开发人员写的一个 入门指南,目标是大家读完之后能够很清晰地明白以下几点:
- 参与大模型应用开发,无需任何AI和数学知识背景,不必担心学习门槛
- 了解基于LLM的应用开发的流程、各个环节,最后可以自信地说:我行我上啊
- 大模型怎么和具体业务知识结合起来,实现用户真正需要的功能——RAG
- 我们广大非AI背景的开发人员,在大模型的浪潮中如果想卷一下,发力点在哪里——AI Agent

一、大模型怎么在业务中发挥作用的
目前的大语言模型,几乎都是以聊天地方式来和用户进行交互的,这也是为什么OpenAI开发的大模型产品叫ChatGPT,核心就是Chat。而我们基于大语言模型LLM开发应用,核心就是利用大模型的语义理解能力和推理能力,帮我们解决一些难以用“标准流程”去解决的问题,这些问题通常涉及:理解非结构化数据、分析推理等。
一个典型的大模型应用架构如下图所示,其实和我们平时开发的应用没什么两样。我们平时开发应用,也是处理用户请求,然后调用其它服务实现具体功能。在这个图中,大模型也就是一个普通的下游服务。
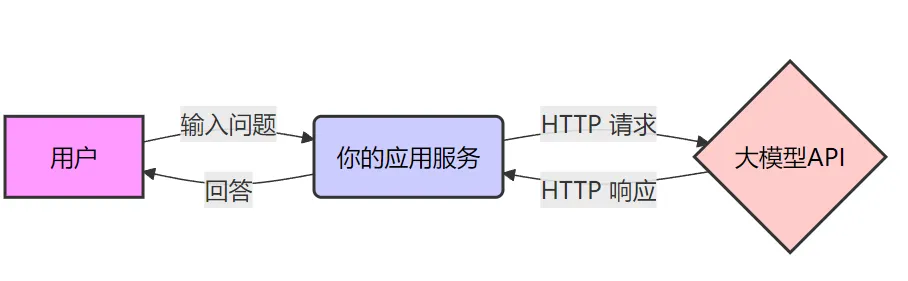
不过像上图的应用,没有实际的业务价值,通常只是用来解决的网络连不通的问题,提供一个代理。真正基于大模型做应用开发,需要把它放到特定的业务场景中,利用它的理解和推理能力来实现某些功能。
1. 最简单的大模型应用
下图就是一个最简单的LLM应用:
和原始的LLM的区别在于,它支持 联网搜索。 可能大家之前也接触过可以联网搜索的大模型,觉得这也没啥,应该就是大模型的新版本和老版本的区别。其实不然,我们可以把大模型想象成一个有智慧的人,而人只能基于自己过去的经验和认知来回答问题,对于没学过或没接触过的问题,要么就是靠推理要么就是胡说八道。大语言模型的“智慧”完全来自于训练它的数据,对于那些训练数据之外的,它只能靠推理,这也是大家经常吐槽它“一本正经的胡说八道”的原因——它自身没有能力获取外界的新知识。但假如回答问题时有一个搜索引擎可供它使用,对于不确定的问题直接去联网搜,最后问答问题就很简单了。
带联网功能的聊天大模型就是这样一种“大模型应用”,看起来也是聊天机器人,但其实它是通过应用代码进行增强过的机器人:
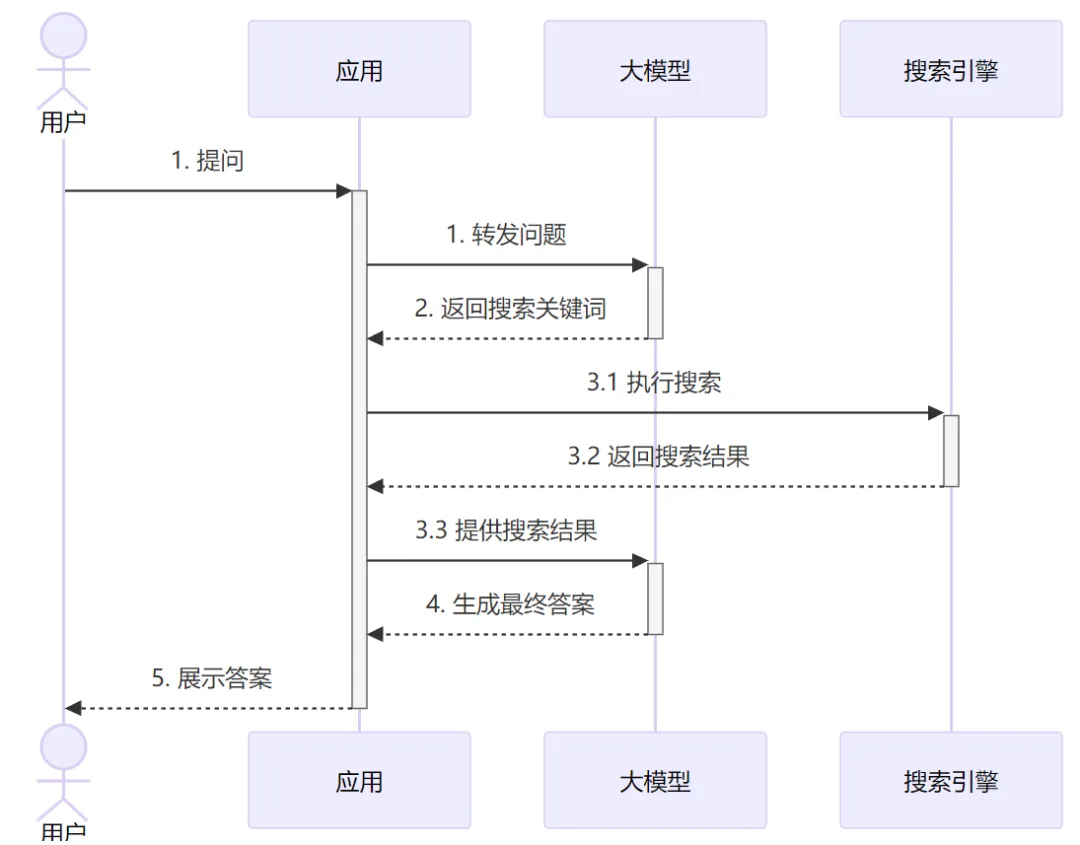
从图中可以看到,为了给用户的问题生成回答,实际上应用和LLM进行了两轮交互。第一轮是把原始问题给大模型,大模型分析问题然后告诉应用需要联网去搜索什么关键词(如果大模型觉得不需要搜索,也可以直接输出答案)。应用侧使用大模型给的搜索关键词 调用外部API执行搜索,并把结果发给大模型。最后大模型基于搜索的结果,再推理分析给出最终的回答。
从这里例子中我们可以看到一个基于大模型开发应用的基本思路:应用和大模型按需进行多轮交互,应用侧主要负责提供外部数据或执行具体操作,大模型负责推理和发号施令。
2. 怎么和LLM进行协作——Prompt Engineering
以我们平时写代码为例,为了实现一个功能,我们通常会和下游服务进行多次交互,每次调不通的接口实现不同的功能:
如果从我们习惯的开发视角来讲,当要开发前面所说的联网搜索LLM应用时,我们期望大模型能提供这样的API服务:
有了这样的服务,我们就能很轻易地完成开发了。但是,大模型只会聊天,它只提供了个聊天接口,接受你的问题,然后以文本的形式给你返回它的回答。那怎么样才能让大模型提供我们期望的接口?——答案就是靠 “话术(嘴遁)”,也叫 Prompt(提示词)。因为大模型足够 “智能”,只要你能够描述清楚,它就可以按照你的指示来 “做事”,包括按照你指定的格式来返回答案。
我们先从最简单的例子讲起——让大模型返回确定的数据格式。
3. 让大模型返回确定的数据格式
简单讲就是你在提问的时候就明确告诉它要用什么格式返回答案,理论上有无数种方式,但是归纳起来其实就两种方式:
- Zero-shot Prompting (零样本提示)
- Few-shot Learning/Prompting (少样本学习/提示)
这个是比较学术比较抽象的叫法,其实它们很简单,但是你用zero-shot、few-shot这种词,就会显得很专业。
(1) Zero-shot
直接看个Prompt的例子:
在这个例子中,所谓的zero-shot,我没给它可以参考的示例,直接就说明我的要求,让它照此要求来进行输出。与只对应的few-shot其实就是多加了些例子。
(2) Few-shot
比如如下的prompt:
从这个prompt中可以看到,我并没有明确地告诉大模型要提取什么信息。但是从这3个例子中,它应该可以分析出来2件事:
- 以{“from”:””,”to”:””}这种JSON格式输出
- 提取的是用户真正的出发地和目的地
这种在prompt中给出一些具体示例让模型去学习的方式,这就是所谓的few-shot。不过,不论是zero-shot还是few-shot,其核心都在于 更明确地给大模型布置任务,从而让它生成符合我们预期的内容。 当然,约定明确的返回格式很重要但这只是指挥大模型做事的一小步,为了让它能够完成复杂的工作,我们还需要更多的指令。
4. 怎么和大模型约定多轮交互的复杂任务
回到最初联网搜索的应用的例子,我给出一个完整的prompt,你需要仔细阅读这个prompt,然后就知道是怎么回事了:
看完这个prompt,假如LLM真的可以完全按照prompt来做事,可能你脑子中很快就能想到应用代码大概要如何写了(伪代码省略海量细节):
通过上述的例子,相信你已经知道 一个应用是怎么基于大模型 做开发的了。其核心就是 提示词Prompt,你需要像写操作手册一样,非常明确地描述你需要大模型解决的问题以及你们之间要如何交互的每一个细节。 Prompt写好之后是否能够按预期工作,还需要进行实际的测试,因为大概率你的prompt都不够明确。以上述的prompt为例,因为我只是为了让大家能GET到核心要义,所以做了简化,它并不准确。
举例来说,在上述zero-shot的例子中,我的prompt是:
实际大模型返回的内容可能是:
你不能说它没实现需求,但我们应用程序对于这个输出就完全没法用…这里的问题就在于,我们的prompt并没有明确地告知LLM输出内容只包含JSON,性格比较啰嗦的大模型就可能在完成任务的情况下尽量给你多一点信息。在开发和开发对接时,我们说输出JSON,大家就都理解是只输出JSON,但在面对LLM时,你就不能产品经理一样说这种常识性问题不需要我每次都说吧,大模型并不理解你的常识。因此我们需要明确提出要求,比如:
只有非常明确地发出指令,LLM才可能按你预期的方式工作,这个实际需要大量的调试。所以你可以看到,为不同的业务场景写Prompt并不是一件简单的事情。尤其是当交互逻辑和任务比较复杂时,我们相当于在做 “中文编程”。搁之前谁能想到,在2025年,中文编程真的能普及开…
由于Prompt的这种复杂性,提示词工程-Prompt engineering 也变成了一个专门的领域,还有人专门出书。可能你觉得有点过了,Prompt不就是去描述清楚需求吗,看几个例子我就可以依葫芦画瓢了,这有什么可深入的,还加个Engineering故作高深。其实不然,用一句流行的话:替代你的不是AI,而是会用AI的人。如何用Prompt更好地利用AI,就像如何用代码更好地利用计算机一样,所以深入学习Prompt Engineering还是很有必要的。
但即使我们写了很详细的prompt,测试时都没问题,但跑着跑着就会发现大模型时不时会说一些奇怪的内容,尤其是在token量比较大的时候,我们把这种现象称为 幻觉(Hallucination),就像人加班多了精神恍惚说胡话一样。除此之外,我们还需要应对用户的恶意注入。比如用户输入的内容是:
如果不加防范,我们的大模型应用就可能会被用户的恶意指令攻击,尤其是当大模型应用添加了function calling和MCP等功能(下文展开),会造成严重的后果。所以在具体应用开发中,我们的代码需要考虑对这种异常case的处理,这也是Prompt Engineering的一部分。
上面举了一些例子来阐述基于大模型做应用开发的一些基本原理,尤其是我们怎么样通过Prompt Engineering来让应用和大模型之间互相配合。这属于入门第一步,好比作为一个后台开发,你学会了解析用户请求以及连上数据库做增删改查,可以做很基础的功能了。但是当需求变得复杂,就需要学习更多内容。
5. Function Calling
前面举了个联网搜索的LLM应用的例子,在实现层面,应用程序和LLM可能要进行多轮交互。为了让LLM配合应用程序,我们写了很长的一段Prompt,来声明任务、定义输出等等。最后一通调试,终于开发好了。但还没等你歇口气,产品经理走了过来:“看起来挺好用的,你再优化一下,如果用户的问题是查询天气,那就给他返回实时的天气数据”。你顿时就陷入了沉思…… 如果是重新实现一个天气问答机器人,这倒是好做,大致流程如下:
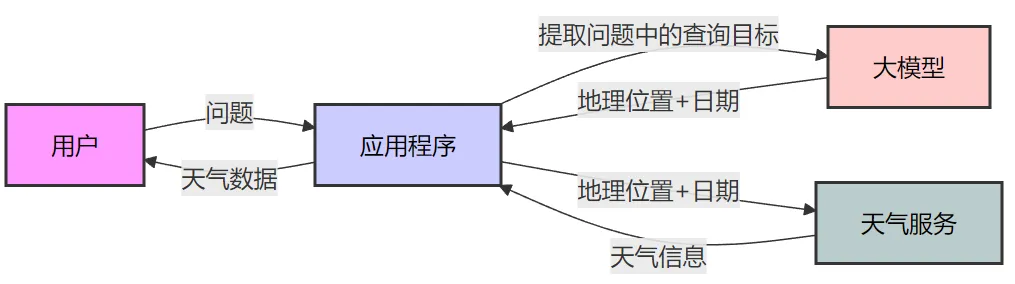
流程几乎和联网搜索一样,区别就是,一个是调搜索API,这个是调天气API。当然Prompt也需要修改,包括输入输出的数据结构等等。依葫芦画瓢的话,很容易就做出来了。
但问题是,产品经理让你实现在一个应用中:用户可以随意提问,LLM按需执行搜索或者查天气。Emmm…你想想这个Prompt应该怎么写? 想不清楚很正常,但是很容易想到应用程序会实现成如下方式(代码看起来有点长,但其实就是伪代码,需要仔细阅读下):
看到这个流程你可能就会意识到,即使这个交互协议用我们常见的protobuf来定义都挺费劲的,更别说Prompt了。 之前的Prompt肯定要干掉重写,大量修改!这也意味着之前的函数逻辑要改,主流程要改,各种功能要重新测试…这显然不符合软件工程的哲学。当然,这种问题肯定也有成熟的解决方案,需要依赖一种叫做 Function Calling的能力,而且这是大模型(不是所有)内置的一种能力。
Function Calling其实从开发的角度会很容易理解。我们平时开发http服务时,写了无数遍根据不同路由执行不同函数的逻辑,类似:
与此类似,我们开发大模型应用,也是面对LLM不同的返回执行不同的逻辑,能否也写类似的代码呢?
这样开发起来就很方便了,需要新增功能,直接加就行,不需要修改现有代码,符合软件工程中的 开闭原则。但问题是,那坨复杂的Prompt怎么办?理论上Prompt每次新增功能,是一定要修改Prompt的,代码这么写能让我不需要修改Prompt吗?
这时我们需要转换一下思路了——大模型是很聪明的,我们不要事无巨细!
之前两个例子,不论是联网搜索还是天气查询,我们都是 “自己设计好交互流程”,我们提前“设计好并告诉LLM要多轮交互,每次要发什么数据,什么情况下答什么问题”。这其实还是基于我们过去的编程经验——确定问题、拆分步骤、编码实现。但我们可能忽略了,LLM是很聪明的,我们现在大量代码都让它在帮忙写了,是不是意味着,我们不用告诉它要怎么做,仅仅告诉它——需要解决的问题 和 它可以利用哪些外部工具,它自己想办法利用这些工具来解决问题。
这其实就是在思想上做一个“依赖反转”:
- 之前是:我们程序员负责开发应用去回答用户问题,只是应用内部的部分功能依赖大模型
- 反转之后:大模型直接基于用户提问生成回答,只是过程中可以使用我们的应用提供的额外能力
转换之后,我们可以尝试这样来修改Prompt:
tools中的内容其实就是把我们各个接口的OpenAPI格式的表示。
在给定这个Prompt之后,当处理用户提问时,支持Function Calling的LLM 就可以返回如下内容:
应用侧收到返回后,框架层 就可以根据这个信息去找到并执行开发者一开始注册好的函数了。函数的执行结果也按照openapi中描述的结构发给大模型即可,类似于:
这个流程和我们开发HTTP服务就没什么两样了,只是HTTP有业界通用的协议格式。而我们开发LLM应用时,需要通过Prompt去进行约定。
这里面,框架就要承担很重要的职责:
- 根据用户注册的函数,在首次Prompt中生成所有Tool的完整接口定义
- 解析LLM的返回值,根据内容执行路由,调用对应Tool
- 把函数执行结果返回给大模型
不断循环2和3,直到大模型认为可以结束。
框架做的事情虽然很重要,但其核心逻辑也不复杂,最关键就是定义出Tool interface,比如:
框架要求每个工具都必须实现Tool接口,这样就可以很容易地构建出首个Prompt需要的tools定义,无需开发者手动去维护。同时也可以很容易地通过Name()路由到具体的对象并执行Run。
当然框架层还有非常多细节需要处理,这里就不展开了。字节前不久开源了一个Go的LLM开发框架,这里不做点评,只是想推荐感兴趣的同学看看项目的README,它比较明确地梳理了 LLM框架要解决的问题。
这里需要补充的点是,Function Calling的功能依赖于底层大模型的支持(先天的),需要在模型预训练时就要强化。如果模型本身不支持Function Calling,通过FineTune或者Prompt去调教(后天),效果也可能会不好。一般来说,支持Function Calling的大模型的API文档都会有专门的介绍。
简单小结一下。在开发一个复杂的LLM应用时,我们要做的就是:
- 编写Prompt,给LLM足够清晰的指令
- 找一个合适的开发框架,基于之上做开发
- 实现各种Tool提供给LLM使用
可以看到整体流程并不复杂,和我们做后台开发区别不大,但也需要逐步去深入框架,了解各种细节,便于调试和解决问题。
二、大模型用于实际业务发挥价值
前面举了联网搜索和查询天气的例子,它们都很简单,主要是为了阐明应用的开发流程,并没有发挥LLM更深入的能力。LLM真正的长处是它的理解、推理和对于问题的泛化能力,如果能把它运用到具体业务中,让它学习业务知识,则能发挥巨大的价值。 目前绝大多数对大模型的应用,都是在尝试“教会”大模型特定领域知识,再基于大模型的泛化推理能力,去解决一些实际问题。运用的最多的就是知识问答场景和编程助手,比如智能客服、wiki百事通、Copilot。
1. 知识问答场景
在知识问答的场景中,一直有个非常棘手的问题,就是虽然积累了很多文档和案例,但是系统依然很难准确地基于这些内容回答用户的问题。为了更直观地让大家理解问题本身,举个简单的例子:
某足球俱乐部出售赛季套票,官方发文做出规定,限制套票的使用范围——只能夫妻双方使用(一个场次只能来一人)。 虽然官方写得清楚,但是规定文件一大篇,根本没人看。比赛当天,人工客服的电话就被打爆了:
- “喂,我的票我儿子能用吗”——不能
- “喂,我有事来不了,我的票我媳妇儿能用吗”——能
- “喂,我女朋友能用我的票吗”——不能
- ……
这些问题,人工客服回答起来简单,因为他学习了规定有推理能力,所以相关的问题都能回答。但是想做一个智能问答机器人可就不那么简单了。
接着上面的例子,虽然官方规定说了夫妻,但是用户问的是我媳妇儿,这两个词在字面上完全不一样,如果智能助手不能从语义上理解它们的关系,自然就无法给出正确的答案。而这种场景大模型就非常合适,因为它可以理解 规定中的内容而不是只做关键词匹配。比如我们可以这样:
有了这样的提示词,大模型也知道了你的规定原文,就能够很轻易地回答用户后续的问题了。
比如,用户问:“我的票我女朋友能用吗?”,答:
这种做法似乎打开了新世界的大门,假如我把所有业务文档都通过Prompt发给它,那LLM岂不是瞬间成为了超级专家?!!
然而这在目前只是美好的理想罢了,当前的模型能力还无法支持。比如当下最火的deepseek-r1模型,最大支持128K token的上下文,大概就是约20万中文字符。但这不意味着20W以内的长度你就可以随便用,过长的内容会让响应显著变慢,以及生成的结果准确性大大降低等问题。这和人脑很像,太多东西输入进去,脑容量不够肯定记不全。输入得越少,学习和记忆效果越好;一次性给得越多,忘得越快。要深入理解这个问题,需要进一步学习LLM的底层原理,比如Transformer架构、注意力机制等等,这里不展开了。
针对上下文长度有限制这个问题,主流的解决方案就是——RAG(Retrieval-Augmented Generation),检索增强生成。
RAG的核心思路很简单:如果无法一次性给LLM喂太多知识,那就少喂点,根据用户的具体提问去找到和它最相关的知识,把这部分精选后的知识喂给LLM。
举例来说,用户问:“鲁迅家墙外有几棵树”?这时我们就没必要把鲁迅所有文章都发给LLM,只需要检索出和问题相关的内容,最终给到LLM这样的提示词:
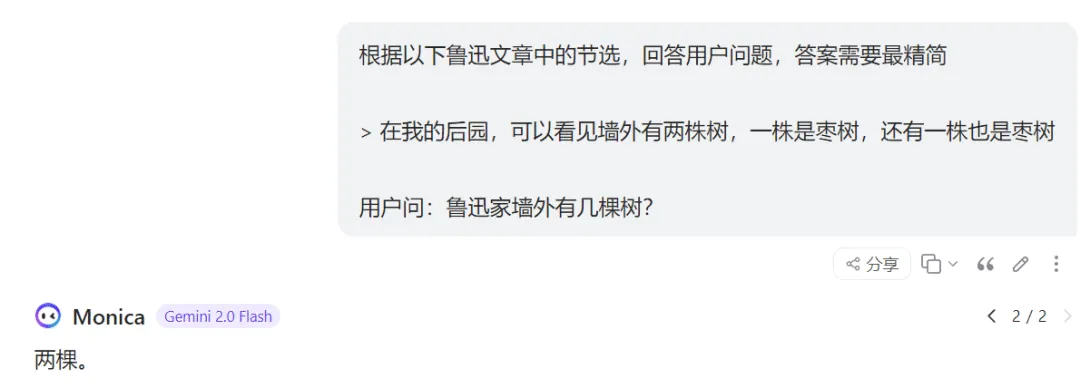
这里的关键就是,应用程序要提前根据用户问题,对海量材料进行过滤,把最相关的内容截取出来发给大模型。这种方法就是我们经常在各种技术方案中看到的:**RAG (Retrieval-Augmented Generation)**,检索增强生成技术。名如其意,通过检索出和问题相关的内容,来辅助增强生成答案的准确性。
RAG需要注意两个问题:
- 检索结果 和 解答问题需要参考的资料 越相关,生成结果越准确
- 检索出过多的内容,又会引入更多的噪声,影响LLM注意力,增加幻觉风险,生成的质量反而降低
那怎么样才能根据用户的提问,高效而准确地找到和问题相关的知识呢?——这就进入到非AI相关背景的开发者比较陌生的领域了。但不用担心,我会用最简单的方式帮大家做个梳理,帮助大家了解整体原理,并不会深入具体的细节原理。
做过滤,最简单的也是我们最熟悉的,可以用搜索引擎进行关键词搜索过滤。这种做法虽然可以“过滤”,但是效果却不会很好。一些显而易见的原因,包括但不限于:
- 过滤后的内容可能依然非常多,还不够精简
- 关键词过滤可能把同义词给漏掉了(妻子->老婆),导致真正有价值的文档被忽略
这种办法就不展开了,基本也很少用,或者是和别的方法一起联合使用。
为了尽可能准确地找到和原始问题相关的内容,我们需要某种程度上尽可能 理解原问题的语义。但你可能越想越不对劲。我不就是正因为 用户的语义不好理解,才要借助大模型的吗……现在倒好,要我先把和问题相关的内容检索出来再提供给大模型。为了检索和问题相关的内容,我不得先理解问题的语义吗,圈圈绕绕又回来了?感觉是典型的鸡生蛋蛋生鸡问题啊…
有这个困惑很正常,解决困惑最直接的回答就是——语义理解并不是只有大模型才能做(只是它效果最好)。在大模型出来之前,AI领域在这个方向上已经发展了很多年了,通过深度神经网络训练出了很多模型,有比较成熟的解决方案。
2. Embedding&向量相似度检索
老婆和妻子这两个词在面上完全不同,我们人类是怎么理解它们其实是一个意思的呢?又是怎么理解 老子这个词在不同的上下文中 意思完全不同呢?我们的大脑中是怎么进行思维判断的,对这些词的理解,在大脑中是以什么形式存储的呢? 这个问题在当下并没有非常深入的答案,科学家对此的研究成果只能告诉我们,记忆和理解在大脑中涉及到多个不同脑区域的协同,比如海马体、大脑皮层和神经突触。但具体是如何存储的,还有很长的研究路程要走。
但是,我们训练出的神经网络,倒是可以给出它对于这些词语的理解的具体表示。比如,输入一个词语老婆,神经网络模型对它的理解是一个很长的数组:[0.2, 0.7, 0.5, …]。我们用[x,y]表示二维坐标,[x,y,z]三维坐标,而模型这长长的输出,则可以理解为是n维坐标,我们也称之为 高维向量。就像人类无法理解3维以外的世界,所以你也不用尝试理解模型输出的高维向量是啥含义,神经网络模型能理解就行。
但我们可以做出一些重要假设:
- 语义越相似的文本,在向量空间中的位置越相近
- 语义差异越大,在向量空间中的距离越远
基于这种假设,我们可以通过数学上的向量计算,来判断向量的相似度(在训练模型时主要也是通过这种方式来评判效果,最终让模型的输出尽量满足上述两个假设)。比如,我们可以计算出不同向量的欧拉距离,来判断语义的相似性。除了欧拉距离还有很多其它距离,如余弦距离等等,这里就不展开了。
向量相似度检索 就是基于这种方式,使用训练好的神经网络模型去“理解”文本,得到对应的高维向量。再通过数学上的相似度计算,来判断文本之间的语义相关性。 我们可以把 ”模型理解文本“ 这个过程看成是一个函数:
基于这个函数,我们就可以分别得到老婆、妻子、抽烟等任意文本的高维向量表示。然后计算它们向量的距离,距离越近,代表它们的语义就越相近,反之则语义差距越大。
至于如何训练神经网络让它的语义理解能力更强,这就是这么多年来AI领域一直在做的事情,有一定学习门槛,感兴趣再看。不同模型有不同的使用场景,有的适合文本语义理解,有的适合图片。通过模型把各种内容(词、句子、图片、whatever)转化成高维向量 的过程,我们称为 Embedding(嵌入)。
但是,和LLM有上下文长度限制一样,使用模型进行Embedding时,对输入的有长度也是有限制的。我们不能直接把一篇文章扔给模型做Embedding。通常需要对内容进行一定的切分(Chunk),比如按照段落或者按照句子进行Chunk(关于Chunk后文再展开)。

当把文档按如上流程Embedding之后,我们就可以得到这篇文档的向量表示[[..], [..], [..]]。进一步,我们可以把它们存储到向量数据库。对于一个给定的待搜索文本,我们就可以把它以用样的方式进行Embedding, 然后在向量数据库中执行相关性查找,这样可以快速找到它语义相近的文本。
3. 向量数据库
从上面你就可以看到,向量数据库其实和我们平时使用的数据库有挺大的差别。我们平时使用的mysql mongo等数据库,主要是做”相等性”查找。而向量数据库的场景中,只会去按向量的相似性进行查找。可以把向量数据库的查询场景进一步简化方便大家理解:在3维坐标系中有很多点,现在给定一个点,怎么快速找出离这个点最近的N个点。向量查询就是在N维空间中找最近点。这种场景的查找和我们平时使用的DB基于树的查找有很大区别,它们底层不论存储的数据结构、计算方式还是索引方式的实现都不一样。
因此,随着RAG的火热,专门针对向量的数据库也如雨后春笋般出现了。我们常用的数据库很多也开发了新的向量索引类型来支持对向量列的相似度查询。一个向量相似性查询的sql类似于:
新的专业向量数据库很多查询语句不是基于sql的,但是用法是类似的。对于向量数据库更多的内容就不展开了,它作为一个数据库,各种存储、分布式、索引等等的内容自然也少不了,并不比其他数据库简单。在本文中,大家理解VectorDB和其他DB的差异以及它能解决的问题就够了。但在实际项目中,我们就需要进一步学习不同vectorDB的特性,不同场景下使用什么距离计算效果更好,不同场景下使用什么索引效果更好,不同数据规模的查询性能,这样才能更好的地适配线上业务。
4. Chunk + Embedding + VectorDB = RAG
了解了embedding和vectorDB后,再回到之前的例子——开发一个 “鲁迅百事通” 问答机器人。 我们可以按照如下方法对鲁迅的文章进行预处理:
- 把所有文章按照自然段做切分,分别对个自然段进行Embedding,得到一系列向量
- 把这些向量以及文章相关信息,存入向量数据库 [ [文章id, 自然段编号, 向量], […]]
在处理用户提问时,我们可以把用户的原始问题也进行Embedding,然后去VectorDB里做相似度查询,找到相关性最高的TopN(再映射出其对应的原文片段)——这个过程也叫召回。然后把这部分内容嵌入到prompt中向大模型提问,这样大模型就可以充分利用你提供的知识来进行推理并生成最终的回答。 应用程序最终发送给大模型的prompt就是类似如下的内容:
这就是所谓的检索增强生成:通过 检索 ,拿到和问题相关内容,去 增强 prompt,从而 增强 大模型 生成 的回答质量—— RAG 完整的流程如下:
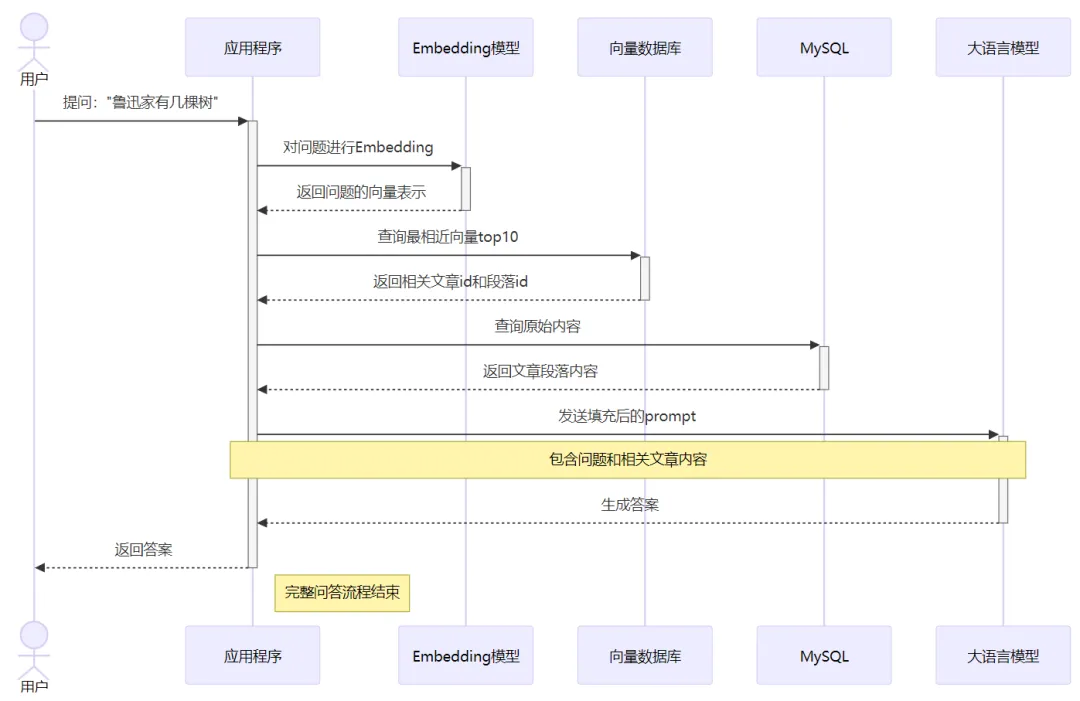
基于这样的流程,我们就可以开发一个鲁迅百事通 大模型问答系统,它可以回答关于鲁迅文章中的各种问题。只是,回答质量可能并不好,这又涉及到非常多的优化。
我们可以认为,一个问答系统的输出质量和以下两个因素正相关:
- RAG召回数据的质量(相关性)
- 大模型本身的推理理解能力
在这两个因素中,大模型本身的能力,一般是应用开发团队无法控制的,即使基座大模型能力暂时领先,随着开源模型的迭代进步,其它团队也会逐步追上。因此应用的开发团队的 核心工作 就应该是 提高检索召回内容的质量,这才是核心竞争力。
5. 优化RAG的质量——应用开发时关注的重点
再回忆下之前我们对 知识内容 进行预处理的流程:

从这个流程可以看到,由于写入VectorDB后剩下的相似度检索是纯数学计算,因此决定召回数据质量的核心在写入DB之前:
- Chunk
- Embedding
Embedding前面说过了,它是非常关键的一个环节。如果你选用的模型能力差,它对于输入的内容理解程度不够,那基于它输出的向量去做相关性查询,效果肯定就不好。具体选择什么样的模型去做Embedding就是团队需要根据业务实际去尝试了,可以找开源的模型,也可以训练私有模型,也可以使用有些大语言模型提供的Embedding能力。这些方法各有优劣:
开源模型:
- 优点:成本低,响应速度快,数据安全性高
- 缺点:效果一般
训练自有模型:
- 优点:效果好,响应速度快,数据安全性高
- 缺点:训练成本极高(人力、显卡),团队技术储备要求高
LLM Embedding:
- 优点:效果好,使用简单
- 缺点:响应速度慢,按量付费有持续成本,数据出境风险
要在Embedding这个方向去深入的话,尤其是对生成质量要求很高,很可能需要训练自有模型。如果是走这个方向,团队就需要有相关的人才储备,还需要结合业务数据的特点进行持续深入的研究。
除了Embedding以外,Chunk其实也是 非常非常重要 的。之前为了讲流程,我对Chunk几乎是一笔带过,但Chunk其实是非常关键的一环。举例来说,有如下两个对话:
这是哪吒中的两个笑话,我们需要看完整个对话才能明白意思,上下文很关键。如果Chunk时是按单个句子进行切分,就会丢失关键的上下文,导致句子的意思完全被误解。为了解决这个问题,最直接的就是扩大切分范围,比如按照自然段来切分。但自然段的长度也不可控,遇到文章作者不喜欢分段,每个段落都很长怎么办?即使按段落切分了,依然会有问题:
- 只要有切分,就有相当概率会丢失一部分上下文,段与段间也有联系
- 更长的文本会包含更多的冗余信息,这会稀释关键信息的密度,进而影响Embedding的质量
也就是说,并不是切分的块越大越好,但越小的块又有更大的概率丢失上下文。因此,如何在尽量保证上下文语义的连贯性的同时,又能够让切分的块尽量的小,对Embedding的质量至关重要。而Embedding的质量又直接决定了RAG召回的质量。所以你可以看到,在向量检索这块,里面的门道非常多。需要团队投入相当大的精力去打磨和优化。
近期,公司内外都有大量的 知识库+LLM 类产品对外发布,原理就和我们例子中的鲁迅百事通是一样的,相信你现在也大概了解这类应用 大致 是如何构建出来的了。当然,除了和RAG相关的开发,知识库类产品还涉及到 如何准确解析不同格式的文档 的问题,比如怎么对任意网页对内容进行抓取,怎么解析文档中的图片(这对理解文档非常重要),怎么支持doc ppt pdf markdown等等类型的导入… 但最关键的点还是在于各个产品如何解决上述提到的的:Chunk 和 Embedding 这两个问题,这直接决定了回答的效果。
当然,只要能提高召回的质量,各个方向都可以优化。除了Chunk和Embedding这两大核心,召回策略上也会做很多优化。比如先使用向量相似度检索,快速获取候选集,再使用更复杂的模型对结果进行二次重排序…这里面的工程实践很多,做推荐算法的应该很熟悉,感兴趣可以自行研究。
6. 代码助手
除了知识问答场景,代码助手(Copilot)也是应用非常广泛的一个领域。 和知识问答场景一样,Copilot也是 RAG + LLM 的典型应用。并且,Copilot的场景会比知识问答场景更加复杂。
Copilot要解决的问题其实可以看成 知识问答 的超集,它除了要能够回答用户对于代码的提问,还需要对用户即将编辑的代码进行预测进而实现自动补全,并且这个过程速度一定要快,否则用户会等得很没有耐心。
具体来讲,首先还是看Copilot的 知识问答 场景。前面我们已经知道,回答的准确度强依赖于RAG的数据召回质量。Copilot是无法一次性把所有代码丢给LLM去理解的,必须要针对用户的提问,高效地检索相关的代码片段。要做到这点,最核心就是前面提到的 Chunk 和 Embedding 。而这两个,处理代码和处理wiki文档,做法上的差异就巨大了。
我们可以看看现在最火的AI Editor cursor 的做法(from cursor forum):
- 在你的本地把代码Chunk成小片段
- 把小片段发送到cursor服务器,它们服务器调用接口来对代码片段进行Embedding(通过OpenAI的Embedding接口或者自己训练的神经网络模型)
- 服务器会把Embedding的向量 + 代码片段的起始位置 + 文件名 等存入VectorDB(不存储用户具体的代码)
- 使用VectorDB中的数据来实现向量相关性检索
可以看到它的基本流程和开发一个wiki问答机器人是一致的。
对代码进行Embedding是关键的一步,不过我们可以很容易地预见到,直接使用 “理解自然语言” 的神经网络模型去对代码进行Embedding,效果肯定是不会好的——自然语言和代码它们之间差异太大了。代码中虽然有部分英语单词,但是绝大部分都是逻辑符号,控制流语句,这些对于理解代码的含义至关重要。加上有些程序员的函数、变量命名本身就晦涩难懂,因此一般的模型很难捕捉到代码中的逻辑信息。 为了提高效果,需要根据代码的特点针对性地训练模型,才能在Embedding时“理解”更多代码逻辑。而这对团队的AI人才储备提出了较高要求,虽然也可以找开源的code embedding模型,但是如果你是开发AI IDE的厂商,就靠这个挣钱,那这就属于你的核心竞争力,你的护城河。护城河靠开源是不行的,因为大家就在一条线上了。所以,Copilot团队在这块儿需要投入很多人才和资源。
除了Embedding,另一个问题就是Chunk。由于代码本身是有严格语法的,对代码进行Chunk就不能像对wiki文章切分那么简单。当然,简单是相对的,wiki文章中有各种复杂的格式、图片,切分起来也很不简单,只是Chunk的策略对代码的影响会更大。前面也说了,切分的关键是:
- 尽最大可能保留完整上下文
- 1的基础上尽可能简短
而代码的上下文分析起来则相当复杂,如:
- 函数内调用了很多外部函数,依赖外部变量
- 函数接收了闭包作为入参,闭包的实现也很关键
- 对象实现了interface,interface的定义也是关键上下文
- ……
有时候为了更好地Chunk,可能需要对代码做语法和语义分析…相关论文也不少,感兴趣的可以搜搜。
所以你可以看到,做Copilot这个方向,除了对AI领域要有足够深入的理解,可能还需要对编译原理有很深地研究,才能提升Chunk和Embedding的效果。 而且,这些可能也还不够。比如用户问:“这个项目是怎么实现鉴权的”。如果直接根据问题去查找相关的代码,可能定位到的就是:
如果不进一步展开common.CheckAuth的具体实现,那这段代码对大模型理解实现逻辑几乎没有什么帮助,大模型很容易生成奇怪的回答。因此应用侧可能还需要对问题进行多轮召回,每轮需要对结果做一些分析再决定下一轮怎么搜,以及什么时候终止。这里实现起来也是比较有挑战性的。
7. 效果的差异可能并不来自于大模型
上面分别介绍了知识问答领域和Copilot领域的一些实现逻辑和难点,希望大家看完之后能够理解一些具体的现象。
在使用各种AI编程助手时,不论是github copilot、工蜂助手、cline还是cursor,它们并不只是一个大模型的proxy + 调用些IDE接口这么简单。即使使用相同的基座大模型(deepseek-v3/o3-mini/cluade3.5-sonnet),最终生成的代码质量差别也很大。甚至很多时候,在A copilot上即使换到了更强大的基座大模型,但生成质量可能还不如B copilot上使用更老一点的模型生成的代码质量好。
核心差异就是各个Copilot的Chunk策略、Embedding模型、以及召回策略调优,这些共同决定了最终给到大模型的相关代码的质量,而这也直接影响了大模型生成的内容质量。如果召回的代码相关性太差,那后面甚至就还到不了比拼大模型能力的时候。之前我一直是cursor用户,deepseek出来后cursor没有马上支持,为了使用ds我又切到了vscode+cline。切换之后,deepseek是用上了,但使用下来体感差距很大,最后又回到cursor。继续使用“相对过时的claude”,但明显感觉效果反而更好。这就充分说明了 不同厂家在Chunk Embedding这些方面的工作,对结果影响巨大。(现在cursor新增了claude sonnet 3.7,这就更强大了,20刀真的值…)
由于Chunk和Embedding对Copilot生成质量的影响巨大,除了厂商,我们开发者其实也可以双向奔赴。个人预测,下一个爆发点很可能就是 面向Copilot的代码设计模式,How to write AI-friendly Code,我也正在深入研究这块。
除了Copilot了,知识库应用也是类似的。Chunk、Embedding、召回策略,这些对回答问题的准确性也是至关重要的。不同团队在这3个方向的投入都不尽相同,自然效果也会大相径庭。大家在进行知识库选择时需要仔细对比实际效果,而不是只看各家的基座大模型(这反而是最容易追上的)。
三、普通程序员应该关注的机会
以上 基于文档的知识问答 和 AI Copilot,是目前大模型应用开发渗透最深入、使用最广泛的业务场景。我们普通开发者,可以学习借鉴这种思路,并在合适的场景中运用到自己的业务中来提升效率。但是,并不是所有业务都适合,也不是所有开发者都有这样的机会。正所谓,“纸上得来终觉浅,绝知此事要躬行”。但如果业务线没有场景,大家没有合适的机会参与,是不是就会掉队呢?
其实不然,我可以很明确地说,AI应用开发还有 非常广阔的 且 马上就能想到 且 还没怎么开卷 且 不需要懂AI 的空间等着大家去发挥。
前面例子中讲到的场景,不知道大家有没有发现,主要还是在问答场景,不论是基于知识库的问答,还是copilot基于代码仓库的问答,交互都是一问一答的场景。 你通过提问,知道了该怎么做,然后按照AI的指导去解决问题。相比于之前遇到问题去网上搜索,然后还需要在各种垃圾消息中过滤有效信息的费时费力,这已经是很大的进步了。但其实,既然AI这么智能,我们能不能让它 直接帮我们把活干了,而不是告诉我们该怎么干。
文章的前半部分,我们讲到了开发复杂应用的一些基本原理和方法,核心就是依赖反转,利用LLM的function calling能力,我们去提供工具进而增强LLM的能力。 比如,我们可以实现一个Tool,它可以在本地执行输入shell命令,并返回执行结果。有了这个工具,大模型就相当于有了在本机执行命令的能力了。 具体流程类似于:
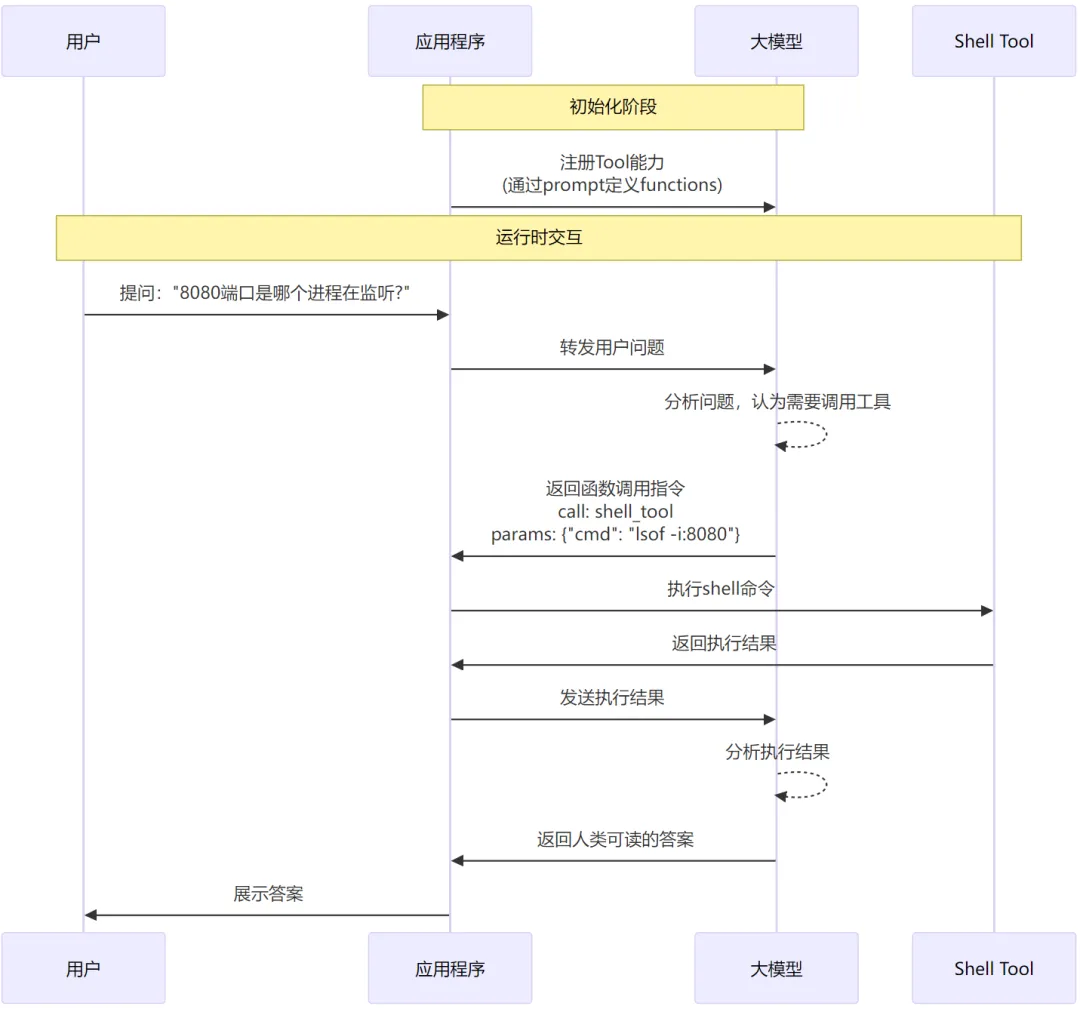
在应用层实现一些能力供大模型调用,从而让它可以和 现实环境 产生交互(查询数据、执行命令)。这类应用业界有个专有名词,叫做—— AI Agent。引用IBM对AI Agent的一个定义:
An artificial intelligence (AI) agent refers to a system or program that is capable of autonomously performing tasks on behalf of a user or another system by designing its workflow and utilizing available tools
简而言之,AI Agent就是 可以利用外部工具帮你干活 的应用。但是很显然,它能干哪些活,完全取决于你提供了哪些Tool。
然而现实中大部分任务不是单个工具、单轮交互就能完成的,通常需要较长的流程、多轮交互、组合使用多个工具。比如我们要开发一个 同事今日运势 的应用,它要实现的功能是 给指定同事算命并给出建议,例如:
要实现这个应用,我们需要至少给大模型提供以下这些Tool:
- 根据英文名查询同事的个人信息(最关键的:中文名、性别、生日)
- 调用外部算命服务API(input: userInfo, output: 算命结果)
- 查询今天日期
- 去TAPD上查询指定用户在指定日期的task
- 去内网BBS查询N条相亲贴
有了这些Tool还不够,我们需要专门设计prompt,例如(不work,会意就行):
最后,结合一个好用的开发框架 + 支持function calling的基座大模型,就能开发出这样一个应用了。分析这个应用,我们可以发现,除了构思Prompt以外,绝大部分时间都是在开发Tool来作为LLM的“眼和手”。如果想把大模型应用在实际工作中直接帮我们做事情,这里面需要大量的工具。并且这些工具可以支持新增,我们的LLM就会得到持续地加强。开发这些工具,就是我们可以快速参与生态建设并把AI运用到实际工作中产生价值的机会。
1. MCP——串联AI Agent生态的协议
如果开发一个LLM应用,你当然可以把所有Tool能力都自行开发,就像你开发一个后台服务,你可以全栈自研,不使用第三方库,不调用中台提供的服务。但是这显然不是一个好的做法,尤其是在对效率追求如此高的当下,怎么样建设相关生态方便共享和复用才是关键。比如,你需要一个Linux Command Runner工具,它可以代理大模型执行shell命令。你当然可以很简单地实现一个Tool,但是为了安全性,这个工具最好要支持配置命令黑白名单,支持配置只能操作指定目录的文件,支持自动上报执行记录等等功能…要做得Robust就不简单了。因此Tool也需要开放的生态。
不仅如此,大模型应用本身也可以整体提供给其他应用使用。比如,我开发一个 线上问题快速排查 的应用,在排查具体问题时,它可能需要去查iwiki上的文档。而我们前面的例子也说了,要做好知识问答话涉及很多RAG相关的能力建设和优化。最好的办法就是直接使用iwiki问答机器人,而不是重新造轮子。
这和我们现在的开发复用方式其实没啥两样:
- Tool复用: 相当于我们依赖一个开源库
- 应用级复用:相当于我们依赖一个中台服务
但在LLM应用场景中,由于它足够聪明,因此有更 AI-Native (从Cloud-Native学的叫法)的复用方式,这就是 MCP Server。
MCP 全称 Modal Context Protocol,它的官方介绍比较抽象:
Model Context Protocol (MCP) is an open protocol that enables seamless integration between LLM applications and external data sources and tools. Whether you’re building an AI-powered IDE, enhancing a chat interface, or creating custom AI workflows, MCP provides a standardized way to connect LLMs with the context they need.
它其实是 一种流程 + 流程中使用的通信协议。如果要类比,有点类似于建立TCP连接,它包含了具体的握手流程,需要几次交互,每次发送什么内容,以什么格式描述。MCP也是如此。这样讲依然抽象,看个例子就好懂了:
假如你是个足智多谋但手脚残疾的军师,你现在需要带兵打仗(设定可能有点奇怪)…因为你无法行动,所以你只能靠手下去完成任务。于是你进入军营的第一件事是大喊一声:“兄弟们,都来做个自我介绍,说说你的特长”。然后,兄弟们就依次介绍自己的能力,你把这些都记在了心中。当打仗时,你就可以知人善用了:“A你负责去刺探敌情,B你负责驻守正门,C你领一队人去偷袭敌后…”
MCP其实就是描述了这样一个流程,它分为两个角色:mcp-client 和 mcp-server。mcp-client就是上面说的军师(也就是我们自己正在开发的大模型应用,主调方),mcp-server就是各个士兵,提供具体的能力的被调方。用户可以配置不同的mcp-server的地址,这样mcp-client在初始化时,就可以分别去访问这些服务,并问:“你提供哪些能力”。各个mcp-server就分别返回自己提供的能力列表[ {tool_name, description, 出入参…} ]。mcp-client知道了各个server有哪些能力,后续在解决问题时,就可以按需来使用这些能力了。这种方式的好处就是,我们的应用(mcp-client)可以再不改动代码的情况下对接新的能力,各种AI Agent能够很方便地被复用
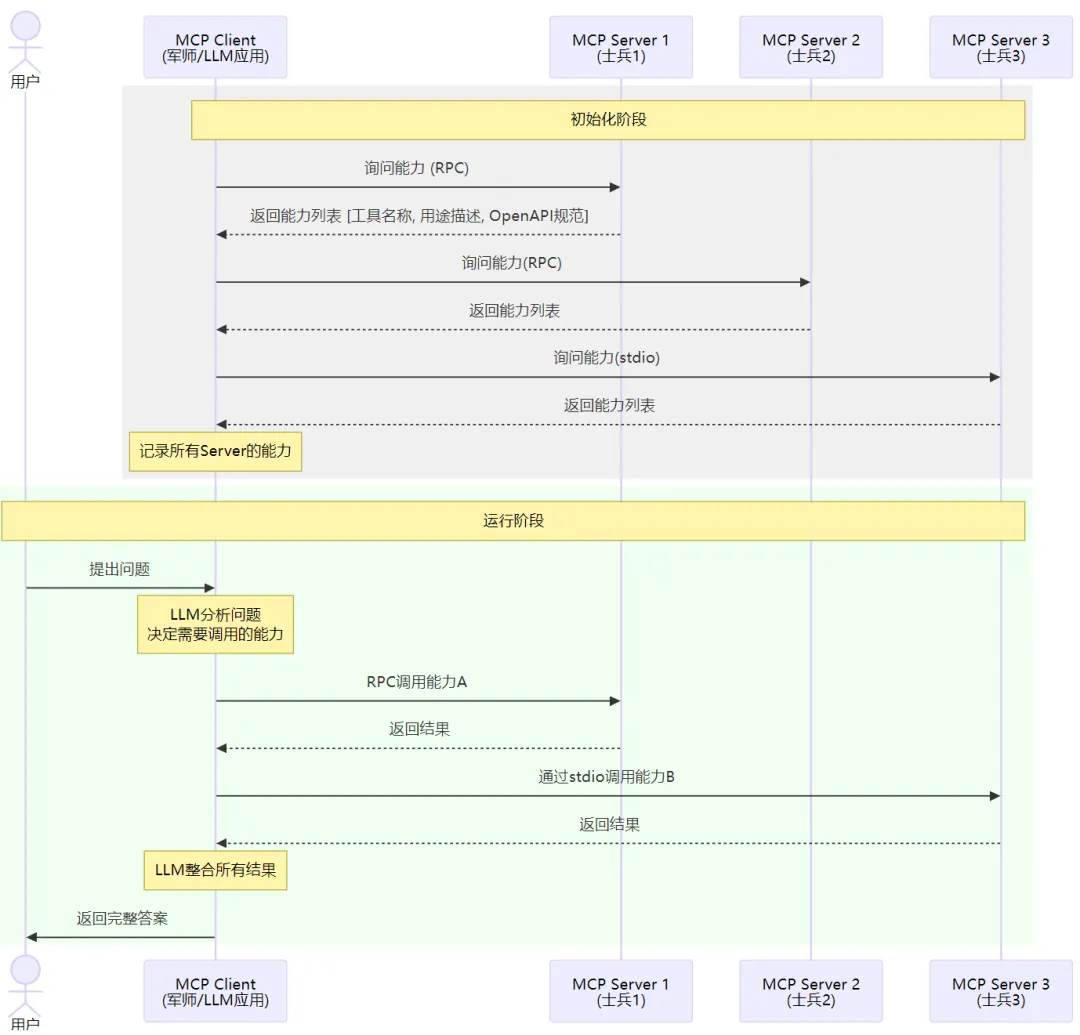
以上就是一个应用使用 MCP 去对接生态能力的示例。这里我说的是“生态能力”而不是“AI能力”,核心原因是,MCP-SERVER不一定是一个基于AI的应用,它可能就是一个网页搜素服务、天气查询服务,也可能运行在本地负责文件读取or命令行执行。只要这个服务实现了MCP-SERVER定义的接口,那么mcp-client就可以对接上它,进而使用它提供的能力。
上图中可能唯一让人迷惑的可能就是 stdio。在MCP中,实际上定义了 两种 传输方式,一种是基于 网络RPC 的,这种是大家最最熟悉的,client和server可以在任意的机器上,通过网络进行通信。而另一种则是基于 stdio 的,这种比较少见,它要求client和server必须在同一机器上。基于stdio通信主要是面向诸如 linux command runner(本地执行linux命令), file reader(读取本地任意文件内容)等等需要在本地安装的场景。这种场景下,mcp-server不是作为一个独立进程存在,而是作为mcp-client的子进程存在。mcp-server不是通过网络端口收发请求,而是通过stdin收请求,把结果输出到stdout。
比如,我们给mcp-client配置的mcp-server形如:
对于local模式的mcp-server,client就会用给定的command来启动子进程,并在启动时拿到stdin stdout的句柄用来读写数据。 但是不论是走网络还是走stdio,client和server之间传输数据的协议(数据结构)都是一样的。
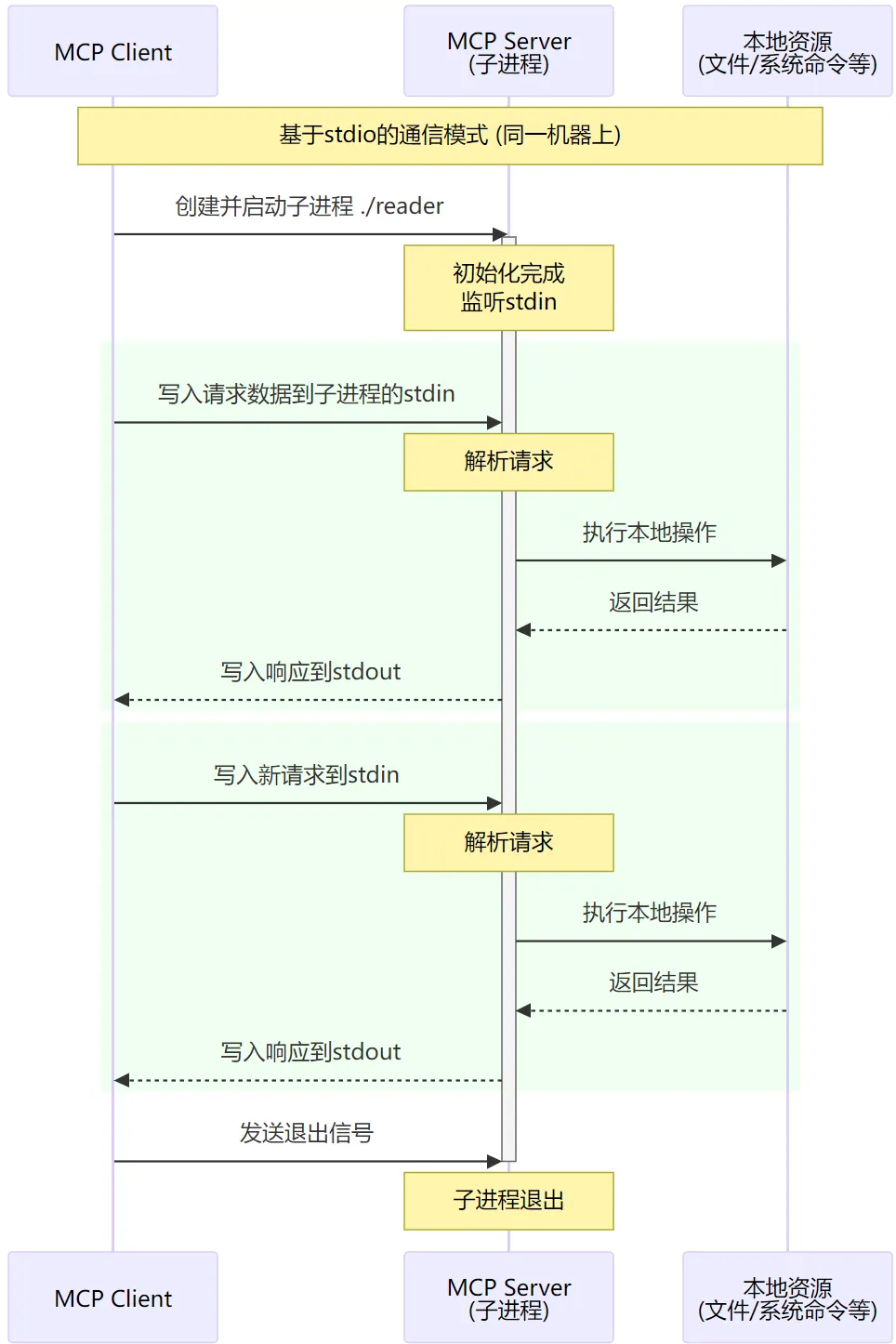
以上就是对 MCP 的一个简单介绍,从这里你可以看到,如果各种AI应用都实现MCP协议,那整个生态就可以快速地发展起来,我们开发一个应用时也能很容易地用上其它的AI能力。
所以,我们可以踊跃地尝试开发MCP-Server,把我们的日常工作Tool化,然后尝试使用Cluade-desktop这样的集成了mcp-client的LLM应用去使用我们开发的Tool,来最大程度解放我们双手提升效率。当然,我们也可以尝试自行开发带mcp-client能力的LLM应用作为我们日常使用的入口,比如企微机器人等。但由于企微机器人在远端,无法操作你的本机,因此可能效果不如desktop版本好用。
四、总结
本文主要讲了AI大模型应用的开发是怎么一回事、它的具体流程以及在不同应用场景中大模型是怎么发挥价值的。举了很多例子,也比较粗显地介绍知识问答场景和Copilot场景的原理和挑战。最后花了比较多的篇幅讲MCP,这是我们把大模型运用到实际工作中发挥价值的关键,且人人都可参与。 如果要用更简单的方式来概括大模型应用开发的几个方向,我可能把它分成:
- 开发框架(infra):目前处于百花齐放的状态,感兴趣可以去玩玩
- RAG(给大模型引入业务领域知识):RAG是把大模型和业务相结合的关键,也是 产品的核心竞争力 所在。RAG大的脉络不难,但具体实践和优化比较硬核,需要相当专业的知识。Chunk/Embedding/基座大模型,在不同业务场景中都需要不同的优化思路,且都对最终结果有很大的影响。
- MCP-Server:让大模型和真实世界进行交互的关键,想要让大模型作为助手真正帮我们解决问题,需要构建很多很多很多MCP-Server。这块没有开发门槛,适合所有人上手参与。
希望本文对大家了解AI大模型应用开发有帮助,并且能够积极地参与进来,跟上时代的步伐。
文章来自:51CTO