

梁文峰说,我们缺的从来都不是钱,而是高端芯片。

幻方官网显示,2022年,公司员工“一只平凡的小猪”一个人就向捐助了1.38亿。你说,这是钱的事吗?
为了突破卡脖子,幻方选择了搞AI的另一条路:从软件架构突破。理解了这个战略方向,就不难理解幻方核心技术突破点了。
要搞AI,存储,通信,计算三者缺一不可。
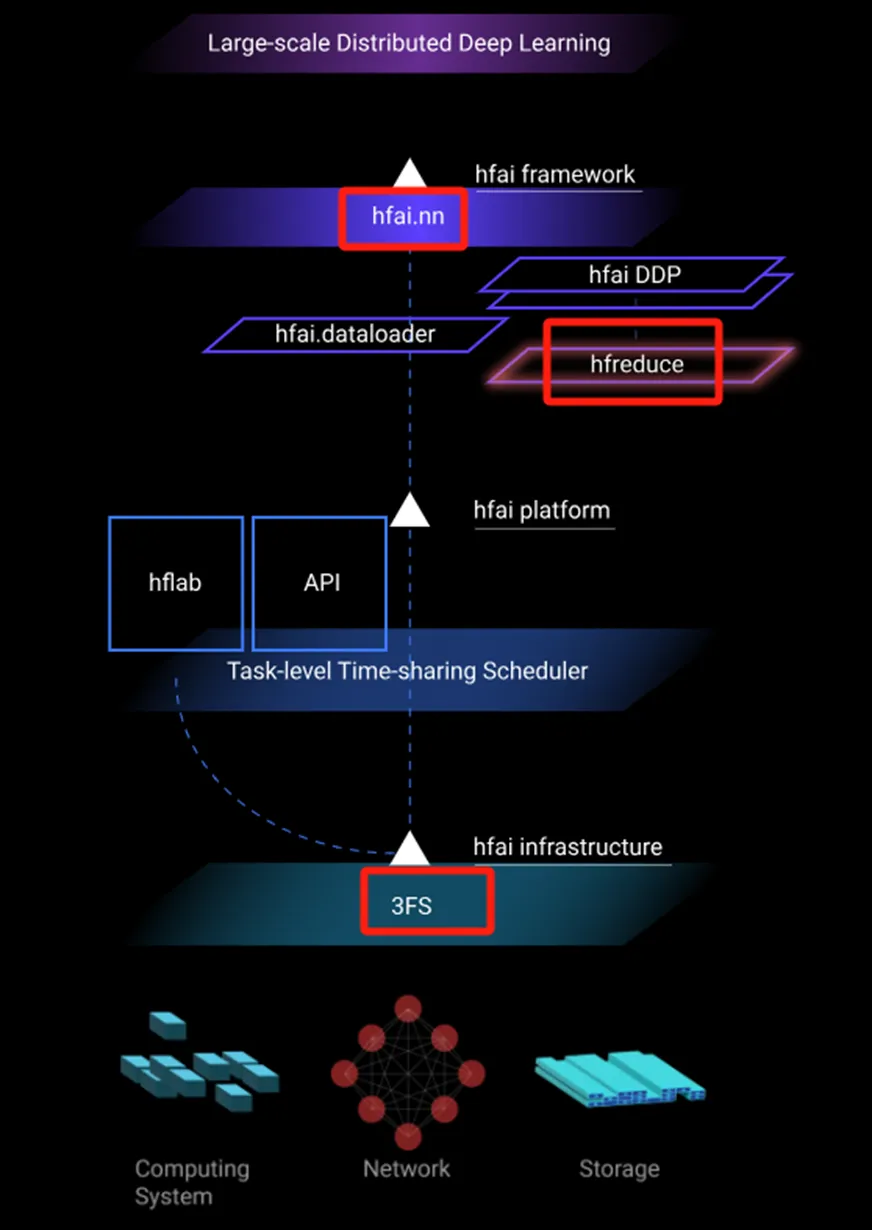
幻方的软件架构优化三大核心技术,正好与其一一对应。
- 存储模块,核心技术:3FS
- 通信模块,核心技术:hfreduce
- 计算模块,核心技术:hfai.nn
杀手锏一:3FS
(1) 3FS是什么?
一个用C++写的高性能分布式文件系统。
(2) 幻方为什么要搞3FS?
AI训练与推理的业务需求,传统分布式文件系统已经难以满足:
- 海量数据顺序读(语料输入);
- 检查点(分步骤重算);
- 顺序写(模型参数保存);
- 随机读(特征查询);
任何脱离业务的架构设计都是耍流氓。既然已有的分布式文件系统无法满足需求时,幻方就说,那我自己重写一个。
(3) 重写后的3FS有多牛逼?
- 读:8T/s
- 写:500G/s
- IO响应:18亿次/s
- 集群使用率:96%
- GPU使用率:85%
这个项目已开源,感兴趣的同学可在git查看细节。
杀手锏二:hfreduce
(1) hfreduce是什么?
一个高性能多卡并行通信工具。
本质上hfreduce相当于PyTorch中的DistributedDataParallel(DDP),只不过使用CPU做加法运算以计算总梯度,而不是调用其他的集体通信库(CCL),传递梯度到不同的显卡上,再各自计算总梯度。
(2) 幻方为什么要搞hfreduce?
还是那句话,任何脱离业务的架构设计都是耍流氓。幻方AI之所以采用CPU来做加法运算,计算总梯度,是因为幻方的主要AI场景是金融行为分析、自然语言处理、生物分子结构预测等。
在这些场景中,基本是数据规模大而模型大小适中。换句话说,在A100显卡40G的显存中,完全可以装得下一个完整的模型和批次样本数据。因此,模型的加速主要是依赖大量的数据并行,让尽可能多的显卡参与训练,再同步梯度。
(3) hfreduce达到什么效果?
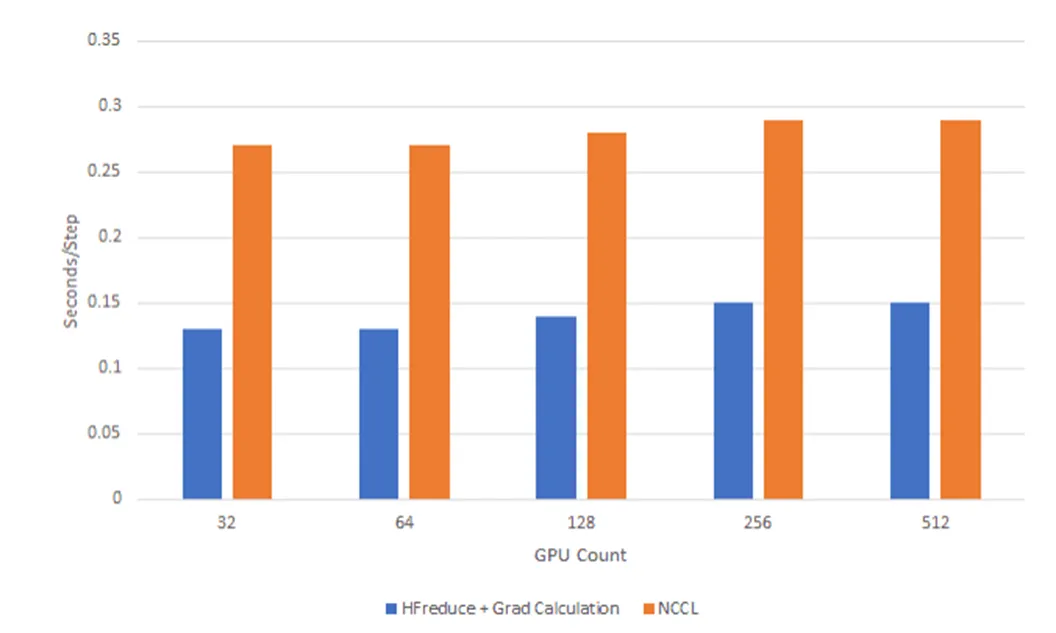
如上图所示,对比传统通信方案,训练速度提高了多少,不用我多说了吧。
杀手锏三:hfai.nn
(1) hfai.nn是什么?
幻方AI深度学习算子。
(2) 幻方为什么要搞hfai.nn?
深度学习框架的流行(如PyTorch,Tensorflow等)极大方便了我们研发设计各种各样的AI模型,而在实际落地的环节中,模型代码往往面临着性能、准确度、资源等各种各样的问题。
幻方自研了一系列AI基础设施:3FS,hfreduce之后,同样需要对Pytorch框架进行了深度优化,结合自身集群特点与自身业务特点,对一些常用的AI算子重新研发,提升效率,于是,就有了hfai.nn。
幻方按照PyTorch框架风格,在hfreduce的基础上进行进一步封装,使用方法和PyTorch的DDP基本相同,但性能与表现明显比后者更好。
(3) hfai.nn达到什么效果?
最重要的三个算子:
①LSTM(长短期记忆网络)
画外音:记住重要的,忘记无关的,核心是根据重要性打分。
训练性能提升8倍。
②Attention(注意力机制)
画外音:动态关注当下最相关的,核心是QKV。
训练性能提升40%+,推理性能提升30%+。
③LayerNorm(归一化)
画外音:把数据拉到均值0,方差1的标准范围。
训练性能提升88%。
总结
幻方软件架构三大核心技术,对于幻方的发展,对于deepseek的发展,至关重要。在幻方的官网,在最显眼的地方,是这么描述的:

思路,比结论更为重要。
文章来自:51CTO