

一、Transformer简要发展史
以下是Transformer模型发展历史中的关键节点:

Transformer架构于2017年6月推出。原本研究的重点是翻译任务。随后推出了几个有影响力的模型,包括:
| 时间 | 模型 | 简要说明 |
| 2017 年 6 月 | 「Transformer」 | Google 首次提出基于 Attention 的模型,用于机器翻译任务 |
| 2018 年 6 月 | 「GPT」 | 第一个使用 Transformer 解码器模块进行预训练的语言模型,适用于多种 NLP 任务 |
| 2018 年 10 月 | 「BERT」 | 使用 Transformer 编码器模块,通过掩码语言建模生成更强大的句子表示 |
| 2019 年 2 月 | 「GPT-2」 | 更大更强的 GPT 版本,由于潜在风险未立即发布,具备出色的文本生成能力 |
| 2019 年 10 月 | 「DistilBERT」 | BERT 的轻量化版本,在保留 97% 性能的同时,速度更快、内存占用更低 |
| 2019 年 10 月 | 「BART、T5」 | 使用完整的 Encoder-Decoder 架构,在各种 NLP 任务中表现优异 |
| 2020 年 5 月 | 「GPT-3」 | 超大规模语言模型,支持“零样本学习”,无需微调即可完成新任务 |
这个列表并不全面,只是为了突出一些不同类型的 Transformer 模型。大体上,它们可以分为三类:
| 类别 | 构成 | 特点 | 典型模型 |
| 「GPT-like」
(自回归 Transformer) |
只使用解码器 | 自回归方式预测下一个词,适合文本生成任务 | GPT、GPT-2、GPT-3 |
| 「BERT-like」
(自动编码 Transformer) |
只使用编码器 | 掩码机制学习上下文表示,适合理解类任务如问答、情感分析 | BERT、RoBERTa、DistilBERT |
| 「BART/T5-like」
(序列到序列 Transformer) |
编码器 + 解码器 | 完整的 encoder-decoder 架构,适合翻译、摘要等生成+理解结合的任务 | BART、T5 |
Transformer 默认都是大模型,除了一些特例(如 DistilBERT)外,实现更好性能的一般策略是增加模型的大小以及预训练的数据量。其中,GPT-2 是使用「transformer 解码器模块」构建的,而 BERT 则是通过「transformer 编码器」模块构建的。

二、Transformer 整体架构
论文中给出用于中英文翻译任务的 Transformer 整体架构如下图所示:

可以看出Transformer架构由Encoder和Decoder两个部分组成:其中Encoder和Decoder都是由N=6个相同的层堆叠而成。Multi-Head Attention 结构是 Transformer 架构的核心结构,其由多个 Self-Attention 组成的。其中,
| 部件 | 结构 | 层数 | 主要模块 |
| Encoder | 编码器层堆叠 | N=6层 | Self-Attention+Feed Forward |
| Decoder | 解码器层堆叠 | N=6层 | Self-Attention+Encoder-Decoder Attention+Feed Forward |
Transformer 架构更详细的可视化图如下所示:

1. 输入模块
(1) Tokenizer预处理
在基于Transformer的大模型LLM中,输入通常为字符串文本。由于模型无法直接处理自然语言,因此需要借助Tokenizer对输入进行预处理。具体流程如下:
- 分词(Tokenization):将输入文本按规则切分为一个个词元(token),如单词、子词或特殊符号。
- 词表映射(Vocabulary Mapping):每个 token 被映射到一个唯一的整数 ID,该 ID 来自预训练模型所使用的词汇表。
- 生成 input_ids 向量(矩阵):最终输出是一个由 token ID 构成的向量(或矩阵),作为模型输入。
以下是以 Hugging Face 的 transformers 库为例,展示如何使用 BertTokenizer 和 BertModel 完成输入文本的预处理和编码:
原始输入文本 “A Titan RTX has 24GB of VRAM” 通过 tokenizer 完成分词和词表映射工作,生成的输入 ID 列表:
其中,
- 101 表示 [CLS] 标记;
- 102 表示 [SEP] 标记;
- 其余为对应 token 在词表中的索引。
在所有基于 Transformer 的 LLM 中,唯一必须的输入是 input_ids,它是由 Tokenizer 映射后的 token 索引组成的整数向量,代表了输入文本在词表中的位置信息。
(2) Embedding 层
在基于 Transformer 的大型语言模型(LLM)中,嵌入层(Embedding Layer)是将输入 token ID 映射为向量表示的核心组件。其作用是将离散的整数索引转换为连续、稠密的向量空间表示,从而便于后续神经网络进行语义建模。
✅ 万物皆可 Embedding:虽然最常见的是词嵌入(Word Embedding),但图像、语音等也可以通过嵌入层映射为向量形式,实现统一建模。
例如,mnist 数据集中的图片,可以通过嵌入层来表示,如下图所示,每个点代表一个图片(10000*784),通过嵌入层,将图片的像素点转化为稠密的向量,然后通过 t-SNE/pca 降维,可以看到图片的空间分布。

LLM 中,单词 token 需要经过 Embedding 层,Embedding 层的作用是将输入的离散化表示(例如 token ids)转换为连续的低维向量表示,其由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到,通常定义为 TransformerEmbedding 层。
① 单词嵌入(Token Embedding)」
自然语言处理中,输入文本通常是以符号形式存在的词汇,而这些离散符号无法直接被神经网络处理。因此需要一个可学习的嵌入矩阵将每个 token 转换为固定维度的向量。
工作原理:
a. 输入是一个形状为 [batch_size, seq_len] 的整数张量,表示每个 token 在词表中的索引;
b. 输出是一个形状为 [batch_size, seq_len, d_model] 的三维张量,其中:
- d_model 是嵌入维度(如 512 或 768);
- 每个 token 对应一个 d_model 维的向量;
c. 嵌入层权重矩阵大小为 [vocab_size, d_model],参数量为:
在 PyTorch 中,词嵌入层通常使用 torch.nn.Embedding 模块实现,其作用是将 token 的索引转换为低维语义向量表示。
✅ 输入与输出说明
| 类型 | 描述 |
| 输入 | 一个整数张量,表示每个 token 在词表中的索引 |
| 输入形状 | (batch_size, sequence_length) 其中: – batch_size:批次大小(即一次处理多少条文本) – sequence_length:每条文本包含的 token 数量 |
| 输出 | 每个 token 被映射到 embedding_dim 维度的稠密向量 |
| 输出形状 | (batch_size, sequence_length, embedding_dim) |
- embedding_dim 是嵌入向量的维度,也称为词向量维度;
- 它通常被设置为 d_model 或 h,即后续 Transformer 层使用的隐藏层维度(如 512 或 768).
📐 示例代码:构建 Token Embedding 层
程序运行后输出结果如下所示:

② 位置嵌入(Positional Encoding)」
由于 Transformer 不依赖于 RNN 的顺序性建模方式,它必须显式地引入位置信息,以保留 token 在序列中的位置特征。
为此,Transformer 使用了 Sinusoidal Positional Encoding(正弦/余弦位置编码):

其中:
- pos:token 在序列中的位置;
- i:维度索引;
- d_model:嵌入维度。
③ TransformerEmbedding 层集成
transformer 输入模块有三个组成部分:文本/提示词、分词器(Tokenizer)和嵌入层(Embeddings)。输入模块的工作流程和代码实现如下所示:

矩阵的每一列表示一个 token 的嵌入向量。
2. Multi-Head Attention 结构
Encoder 和 Decoder 结构中公共的 layer 之一是 Multi-Head Attention,其是由多个 Self-Attention 并行组成的。Encoder block 只包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。

(1) Self-Attention 结构
Self-Attention 中文翻译为自注意力机制,论文中叫作 Scale Dot Product Attention,它是 Transformer 架构的核心,使得每个 token 能够关注整个序列中的其他 token,从而建立全局依赖关系。其结构如下图所示:

(2) Self-Attention 实现✅ 在本文中,Self-Attention 层与论文中的 ScaleDotProductAttention 层意义一致,实现方式完全相同。
🧮 数学定义
Self-Attention 的计算过程可以表示为:
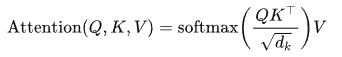
其中:
 :Query 向量;
:Query 向量; :Key 向量;
:Key 向量; :Value 向量;
:Value 向量; :Query 和 Key 的维度;
:Query 和 Key 的维度;- Softmax 对注意力分数按最后一个维度归一化;
 :用于缩放点积,防止 softmax 梯度消失;
:用于缩放点积,防止 softmax 梯度消失;
输入来源:
- 输入词向量经过 Embedding 层后,进入位置编码层;
- 再通过线性变换(Linear 层),分别生成 Query、Key 和 Value 向量;
- 这三个向量的形状通常为 [batch_size, seq_len, d_k] 或 [seq_len, d_k]。
计算步骤如下:
① 计算注意力分数矩阵
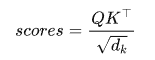
- 其中
 是 Key 张量的转置;
是 Key 张量的转置; - 点积结果是一个 [seq_len, seq_len] 的注意力得分矩阵;
- 使用 softmax 归一化,得到注意力权重。
② 应用掩码(可选)
- 在 Decoder 中使用 Masked Self-Attention,防止未来信息泄露;
- 若传入 mask,将对应位置设为极小值(如 -1e9)以抑制其影响。
③ 加权聚合 Value 向量
- 将 softmax 后的注意力权重与 Value 相乘,得到上下文感知的输出张量;
- 输出维度保持与输入一致:[batch_size, seq_len, d_v]。
🧱 代码实现:
📐 示例调用与输出解析:
| 变量 | 形状 | 描述 |
| Q, K, V | [5, 10, 64] | batch=5,序列长度=10,嵌入维度=64 |
| scores | [5, 10, 10] | 注意力得分矩阵,反映 token 之间的相似度 |
| attn_weights | [5, 10, 10] | softmax 后的注意力权重,用于加权聚合 Value |
| output | [5, 10, 64] | 最终输出,融合了上下文信息的 Value 加权表示 |
(3) Multi-Head Attention
Multi-Head Attention(MHA)是在Self-Attention基础上引入的一种增强机制。其核心理念是:将输入向量空间划分为多个子空间,在每个子空间中独立计算Self-Attention,最后将多个子空间的输出拼接在一起并进行线性变换,从而得到最终的输出。
对于 MHA,之所以需要对 Q、K、V 进行多头(head)划分,其目的是为了增强模型对不同信息的关注。具体来说,多组 Q、K、V 分别计算 Self-Attention,每个头自然就会有独立的 Q、K、V 参数,从而让模型同时关注多个不同的信息,这有些类似 CNN 架构模型的多通道机制。
下图是论文中 Multi-Head Attention 的结构图。

从图中可以看出, MHA 结构的计算过程可总结为下述步骤:
- 将输入 Q、K、V 张量进行线性变换(Linear 层),输出张量尺寸为 [batch_size, seq_len, d_model];
- 将前面步骤输出的张量,按照头的数量(n_head)拆分为 n_head 子张量,其尺寸为 [batch_size, n_head, seq_len, d_model//n_head];
- 每个子张量并行计算注意力分数,即执行 dot-product attention 层,输出张量尺寸为 [batch_size, n_head, seq_len, d_model//n_head];
- 将这些子张量进行拼接 concat ,并经过线性变换得到最终的输出张量,尺寸为 [batch_size, seq_len, d_model]。
📐 数学表达式

其中:

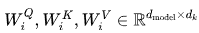 :第 i 个 head 的可学习参数;
:第 i 个 head 的可学习参数; :最终输出的线性变换矩阵;
:最终输出的线性变换矩阵;- Concat表示将各个 head 的输出拼接在一起。
(4) Multi-Head Attention 实现
📊 示例调用与输出解析:
| 变量 | 形状 | 描述 |
| Q, K, V | [32, 10, 512] | 输入张量,表示 batch=32,seq_len=10,d_model=512 |
| q, k, v | [32, 8, 10, 64] | 拆分后的 Q/K/V,每个 head 64 维 |
| sa_output | [32, 8, 10, 64] | 每个 head 的 attention 输出 |
| mha_output | [32, 10, 512] | 拼接后的最终输出 |
| attn_weights | [32, 8, 10, 10] | 每个 head 的注意力权重矩阵 |
3. Encoder结构
Transformer 中的 Encoder 是整个模型中用于编码输入序列的部分。它由 N=6 个相同的 encoder block 堆叠而成。每个 encoder block 主要包含两个子层(sub-layers):多头自注意力机制(Multi-Head Self-Attention)和位置全连接前馈网络(Position-wise Feed Forward Network)。
这两个子层之间都使用了 残差连接(Residual Connection) 和 层归一化(Layer Normalization),以增强训练稳定性和模型表达能力。
下图中红色框选部分表示一个标准的 Encoder Block,其内部结构如下:

由以下四个关键部分构成。
| 模块 | 描述 |
| Multi-Head Attention | 使用多个 attention head 并行提取序列中的不同特征 |
| Add & Norm (1) | 残差连接(Residual Connection)+ 层归一化(LayerNorm) |
| Position-wise FeedForward | 两层线性变换 + 激活函数,对每个词独立建模 |
| Add & Norm (2) | 同样应用残差连接和 LayerNorm |
(1) 每一层的计算流程(以单个 encoder block 为例)
① 多头自注意力机制(Multi-Head Self-Attention)
- 输入:嵌入后的张量

- 输出:通过自注意力加权后的新张量 sa_output
其中,
- Query、Key 和 Value 来自同一个输入 ;
- 可选 mask 通常用于屏蔽 padding token 或控制位置感知范围。
② 残差连接 + 层归一化(Sublayer 1)
- 应用残差映射,缓解梯度消失问题;
- 使用 LayerNorm 对每个 token 的向量进行标准化处理;
- 整体目标:提升模型表达能力与训练稳定性。
③ 位置全连接前馈网络(Position-wise FeedForward)
定义为:
![]()
- d_model:模型隐层维度(如 512);
- d_ff:FeedForward 网络中间维度(如 2048);
- ReLU 导致非线性更强的语义表达。
④ 再次残差连接 + 层归一化(Sublayer 2)
- 保证模型在经过复杂变换后仍能保留原始信息;
- 达成对上下文感知表示的稳定学习。
(2) 维度变化说明(输入输出保持一致)
无论经过多少层 Encoder block,每个 block 的输入与输出形状始终一致:
| 张量 | 形状 | 描述 |
| 输入 | [batch_size, seq_len, d_model] | 批次大小 × 序列长度 × 模型维度 |
| MHA 输出 | [batch_size, seq_len, d_model] | 注意力加权后的输出 |
| FFN 输出 | [batch_size, seq_len, d_model] | 每个 Token 的前馈网络输出 |
| 最终输出 | [batch_size, seq_len, d_model] | 经过两次 Sublayer 后仍然保持相同维度 |
(3) PyTorch 模块封装示例
(4) 封装整个 Encoder 模块
有了 EncoderBlock 后,我们可以将它 重复 N 次 构建完整的 Encoder:
📈 示例调用
4. Decoder结构
Decoder是Transformer架构中用于生成输出序列的部分。与Encoder类似,它由N=6个相同的Decoder block堆叠而成,但结构更为复杂。
(1) Decoder Block 的核心组件
一个标准的Decoder block包含三个主要子层:
- Masked Multi-Head Self-Attention
- Encoder-Decoder Attention
- Position-wise Feed Forward Network
每个子层后面都跟随 残差连接(Residual Connection) 和 层归一化(Layer Normalization)。
如下图右侧红框表示一个标准的 Decoder Block。

①「Masked Multi-Head Self-Attention」
这是Decoder的第一个注意力机制,用于处理目标语言的输入序列(即解码器自身的输入)。
- 使用 masking 技术 防止在预测当前词时看到未来的词,保持因果关系。
- 实现方式:通过 trg_mask 屏蔽未来信息。
②「Encoder-Decoder Attention」
这是 Decoder 的第二个注意力机制,用于将 Encoder 的输出信息融合到 Decoder 中。
- Query (Q) 来自上一层 Decoder 的输出;
- Key (K) 和 Value (V) 来自 Encoder 的输出;
- 这样 Decoder 在生成每个词时都能关注到整个输入句子的信息。
③ 「Position-wise Feed Forward Network」
这是一个简单的两层全连接网络,对每个位置的向量进行非线性变换。
④「残差连接 + 层归一化(Add & Norm)」
每个子层都应用:
- 提升训练稳定性;
- 缓解梯度消失问题。
⑤「Decoder的完整实现」
DecoderLayer类:
Decoder 类:
三、Transformer实现
基于前面实现的 Encoder 和 Decoder 组件,我们就可以实现 Transformer 模型的完整代码,如下所示: