
此前,人形机器人Ameca「大梦初醒」的神情,已让许多人感受到了真正的「恐惧」。

随着ChatGPT横空出世,得到加持的人形机器人虽擅长语言交流,但是在非语言交流,特别是面部表情,还差得很远。

未来,如果人类真的要生活在一个充满机器人的世界之中,机器人必须要有像人类一样能自主通过面部表情获取人类的信任的能力。
显然,设计一款不仅能做出各种面部表情,还能知道何时表现的机器人,一直是一项艰巨的任务。
来自哥伦比亚大学工程学院的创新机器实验室,5年来一直致力于这一挑战。
最近,研究团队推出了一款机器人Emo——能够预测人类面部表情,并与人类同时做出表情。
最新研究已发表在Science子刊上。

论文地址:https://www.science.org/doi/10.1126/scirobotics.adi4724
Emo的自我监督学习框架,就像人类照镜子来练习面部表情。

有趣的是,Emo甚至学会了在一个人微笑前840毫秒提前预测,并同时与人类一起微笑。

这种快速及时的表情回应,能让人类感受到机器人的真诚和被理解的感觉。
而且,它还可以做出眼神互动。

Emo如何能够做到精准预测人类表情?
人机交互革命正来临
由Hod Lipson带领的研究团队称,在开发机器人Emo之前,需要解决两大挑战。
首先是硬件方面,如何机械地设计一个涉及复杂硬件和驱动机制,且具有表现力的多功能机器人人脸。
另一方面,就是设计好的机器人脸,需要知道生成哪种表情,让其看起来自然、及时和真实。

而且更进一步,研究小组还希望训练机器人能够预测人类的面部表情,并与人同时做出这些表情。
具体来说,Emo脸部配备了26个执行器,可以呈现出多种多样的微妙面部表情。
在执行器之外,Emo的脸使用了硅胶皮设计,方便快速定制和维护。

为了进行更加逼真的互动,研究人员为机器人的眼睛配备了高分辨率摄像头。
因此Emo还可以做到眼神交流,这也是非语言交流中重要的一部分。
此外,研究小组还开发了两个人工智能模型:一个是通过分析目标面部的细微变化来预测人类的面部表情,另一个使用相应的面部表情生成运动指令。
为了训练机器人如何做出面部表情,研究人员将Emo放在相机前,让它做随机的动作。
几个小时后,机器人学会了他们的面部表情和运动指令之间的关系。

团队将其称为「自我建模」,与人类想象自己做出特定表情的样子。
然后,研究小组为Emo播放了人类面部表情的视频,通过逐帧观察并学习。
经过几个小时的训练后,Emo可以通过观察人们面部的微小变化,来预测他们的面部表情。
这项研究主要作者Yuhang Hu表示,「我认为,准确预测人类面部表情是人机交互(HRI)的一场革命。传统上,机器人的设计并不考虑人类在交互过程中的表情」。

「现在,机器人可以整合人类的面部表情作为反馈。当机器人与人实时进行共同表达时,不仅提高了交互质量,还有助于在人类和机器人之间建立信任。未来,在与机器人互动时,它会像真人一样,观察和解读你的面部表情」。
接下来,一起看看Emo背后设计的具体细节。
技术介绍
机械控制结构


Emo 配备了26个执行器(下图),提供了更高的面部自由度,可以做出不对称的面部表情。

(1 和 2) 用磁铁连接的连杆控制眉毛。(3) 上眼睑。(4) 下眼睑。(5) 眼球连杆。(6) 眼球框架。(7) 相机

(8至10和13) 口形被动连杆机构。(11 和 12)二维五杆机制(2D five-bar mechanism)的连杆。
Emo设计的主要区别之一是使用直接连接的磁铁来使可更换的面部皮肤变形。这种方法可以更精确地控制面部表情。
此外,Emo的眼睛内嵌摄像头,可实现仿人视觉感知。

这些高分辨率的 RGB(红、绿、蓝)摄像头,每只眼睛的瞳孔内都有一个,增强了机器人与环境互动的能力,并能更好地预测对话者的面部表情。
眼睛模块控制眼球、眉毛和眼睑的运动,如上图所示。
每个眼框都装有一个高分辨率 RGB 摄像头。眼框分别由两个电机通过平行四边形机构在俯仰和偏航两个轴上驱动。
这种设计的优点是在眼框中央创造了更多空间,使研究人员能够将摄像头模块安装在与人类瞳孔相对应的自然位置。
这种设计有利于机器人与人类进行更自然的面对面互动。
它还能实现正确自然的注视,这是近距离非语言交流的一个关键元素。

除了这些硬件升级外,研究人员还引入了一个由两个神经网络组成的学习框架——一个用于预测Emo自身的面部表情(自我模型),另一个用于预测对话者的面部表情(对话者模型)。
研究人员的软皮人脸机器人有23个专用于控制面部表情的电机和3个用于颈部运动的电机。
整个面部皮肤由硅胶制成,并用30块磁铁固定在机器人面部之上。
机器人面部皮肤可以更换成其他设计,以获得不同的外观和皮肤材质。

表情生成模型
研究人员还提出了一个升级版逆向模型,可使机器人在相同的计算硬件上生成电机指令的速度比上一代产品快五倍以上。
他们提出了一种自我监督学习过程,以训练研究人员的面部机器人在没有明确的动作编排和人类标签的情况下生成人类面部表情。
控制机器人的传统方法依赖于运动学方程和模拟,但这只适用于具有已知运动学的刚体机器人。
机器人有柔软的可变形皮肤和几个带有四个套筒关节的被动机构,因此很难获得机器人运动学的运动方程。
研究人员利用基于视觉的自我监督学习方法克服了这一难题,在这种方法中,机器人可以通过观察镜子中的自己来学习运动指令与所产生的面部表情之间的关系。
机器人的面部表情由19个电机控制,其中18个电机对称分布,一个电机控制下颌运动。
在研究人员的案例中,面部数据集中的表情都是对称的;
因此,对称分布的电机在控制机器人时可以共享相同的电机指令。
因此,实际的控制指令只需要11个归一化为 [0, 1] 范围的参数。
面部反演模型是利用机器人自身生成的数据集(下图)进行训练的,其中包括电机指令和由此产生的面部地标。

研究人员以自我监督的方式,通过随机的 「电机咿呀学语 」过程收集数据。在将指令发送到控制器之前,该过程会自动删除可能会撕裂面部皮肤或导致自碰撞的电机指令。
在伺服电机到达指令定义的目标位置后,研究人员使用RGB摄像头捕捉机器人的面部图像,并提取机器人的面部地标。
通过将自我模型和预测对话者模型相结合,机器人可以执行协同表达。
表情预测模型
研究人员还开发了一个预测模型,它可以实时预测对话者的目标面部表情。

为使机器人能及时做出真实的面部表情,它必须提前预测面部表情,使其机械装置有足够的时间启动。
为此,研究人员开发了一个预测面部表情模型,并使用人类表情视频数据集对其进行了训练。该模型能够根据一个人面部的初始和细微变化,预测其将要做出的目标表情。
首先,研究人员使用每组面部地标与每个视频中初始(「静止」)面部表情的面部地标之间的欧氏距离来量化面部表情动态。
研究人员将静止面部地标定义为前五帧的平均地标,目标面部地标则定义为与静止面部地标差异最大的地标。
静态面部地标的欧氏距离与其他帧的地标的欧氏距离会不断变化,并且可以区分。
因此,研究人员可以通过地标距离相对于时间的二阶导数来计算表情变化的趋势。
研究人员将表情变化加速度最大时的视频帧作为 「激活峰值」。
为了提高准确性并避免过度拟合,研究人员通过对周围帧的采样来增强每个数据。
具体来说,在训练过程中,预测模型的输入是从峰值激活前后总共九帧图像中任意抽取四帧图像。
同样,标签也是从目标脸部之后的四帧图像中随机取样的。
数据集共包含45名人类参与者和970个视频。其中80%的数据用于训练模型,其余数据用于验证。
研究人员对整个数据集进行了分析,得出人类通常做出面部表情所需的平均时间为0.841 ± 0.713秒。
预测模型和逆向模型(仅指研究人员论文中使用的神经网络模型的处理速度)在不带 GPU 设备的 MacBook Pro 2019上的运行速度分别约为每秒 650 帧(fps)和 8000 帧(fps)。
这一帧频还不包括数据捕获或地标提取时间。
研究人员的机器人可以0.002秒内成功预测目标人类面部表情并生成相应的电机指令。这一时间留给捕捉面部地标和执行电机指令以在实体机器人面部生成目标面部表情的时间约为0.839秒。
为了定量评估预测面部表情的准确性,研究人员将研究人员的方法与两个基线进行了比较。
第一种基线是在逆模型训练数据集中随机选择一张图片作为预测对象。
该基线的数据集包含大量由咿呀学语产生的机器人表情图片。
第二条基线是模仿基线,它选择激活峰值处的面部地标作为预测地标。如果激活峰值接近目标脸部,那么该基线与研究人员的方法相比就很有竞争力。
然而,实验结果表明,研究人员的方法优于这一基线,表明预测模型通过归纳面部的细微变化,而不是简单地复制最后输入帧中的面部表情,成功地学会了预测未来的目标面部。
图4B显示了对预测模型的定量评估。
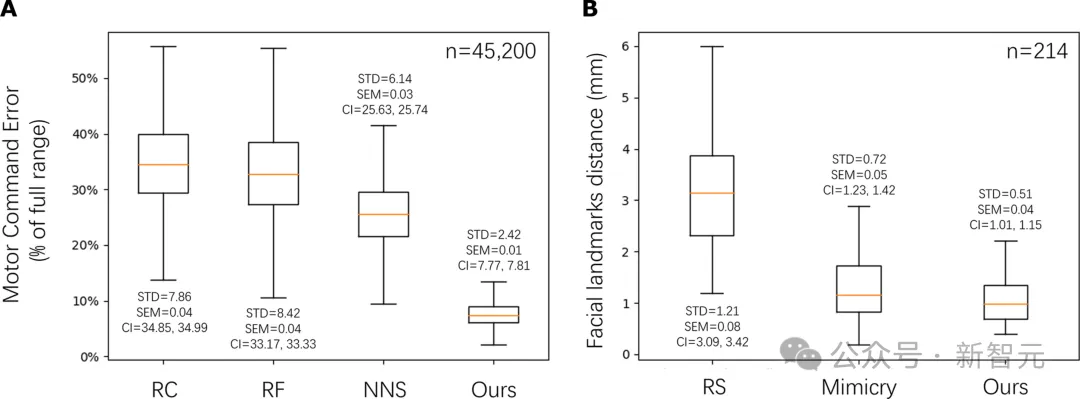
研究人员计算了预测地标与地面实况地标之间的平均绝对误差,地面实况地标由维度为113×2的人类目标面部地标组成。
表格结果(表S2)表明,研究人员的方法优于两种基线方法,表现出更小的平均误差和更小的标准误差。
Emo下一步:接入大模型
有了能够模拟预测人类表情的能力之后,Emo研究的下一步便是将语言交流整合到其中,比如接入ChatGPT这样的大模型。
随着机器人的行为能力越来越像人类,团队也将关注背后伦理问题。
研究人员表示,通过发展能够准确解读和模仿人类表情的机器人,我们正在向机器人可以无缝地融入我们的日常生活的未来更近一步,为人类提供陪伴、帮助。
想象一下,在这个世界,与机器人互动就像与朋友交谈一样自然和舒适。
作者介绍
Yuhang Hu(胡宇航)是这篇论文的通讯作者。
目前,他是哥伦比亚大学的博士生,专注于机器人和机器学习的研究。
